SERA:プライベートコードベースに特化できる効率的なオープンソースコーディングエージェント
SERAは、プライベートなコードベースに特化可能なオープンソースのコーディングエージェントであり、従来の強化学習より26倍、既存の合成データ手法より57倍も安価に訓練できる手法を提案しています。
TL;DR(結論)
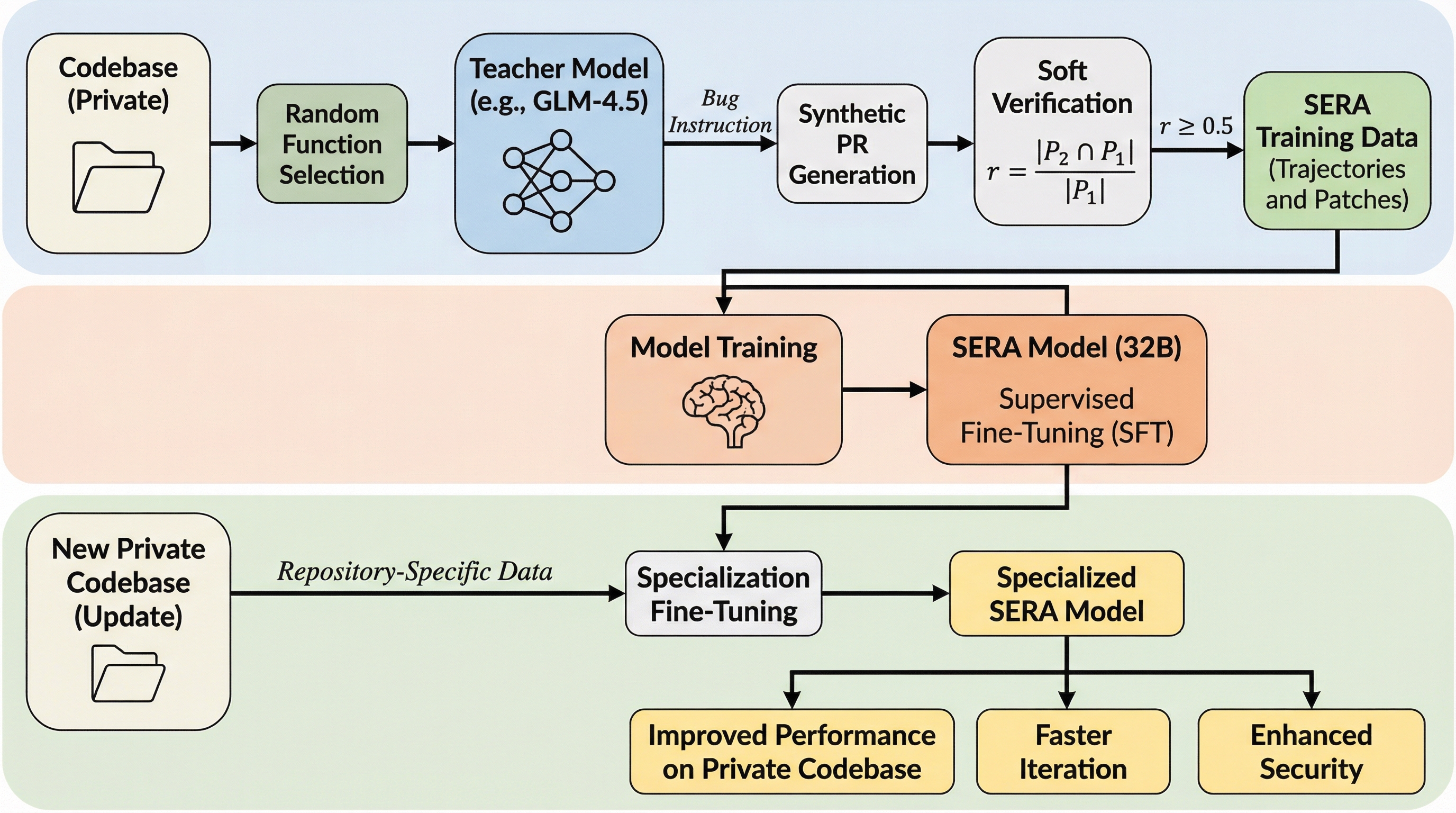
SERAは、プライベートなコードベースに特化可能なオープンソースのコーディングエージェントであり、従来の強化学習より26倍、既存の合成データ手法より57倍も安価に訓練できる手法を提案しています。 新開発の「Soft Verified Generation(SVG)」は、実行テストの代わりにパッチの行レベル一致度を確認する「ソフト検証」を採用し、複雑なテスト環境を不要にしながら、あらゆるリポジトリから高品質な訓練データを生成することを可能にしました。 32B規模のモデルでSWE-bench Verifiedにおいて最大54.2%のスコアを達成し、特定のコードベースへの特化ではわずか8,000個のサンプルで教師モデルの性能を凌駕できることを示しており、開発チームが独自のコードに最適化したモデルを即座に構築できる道を開きました。
なぜこの問題か
現代のソフトウェア開発において、コーディングエージェントは中心的な役割を果たしていますが、依然としてクローズドソースのシステムが強力な力を保持しています。オープンウェイトのモデルには、プライベートなコードベースに特化し、リポジトリ固有の情報や慣習、ドメイン知識をモデルの重みに直接エンコードできるという根本的な利点があるはずですが、これまでは訓練のコストと複雑さがその利点を理論上のものに留めていました。 従来のコーディングエージェントの訓練には、主に強化学習(RL)または複雑な合成データ生成パイプラインが必要でした。強化学習には、サンドボックス化された実行環境、分散訓練インフラ、およびロールアウトのオーケストレーションが必要であり、これには膨大なリソースが求められます。実際に、近年の強化学習を用いた研究では、平均して12人以上の著者が関わっていることがその複雑さを物語っています。 また、既存の合成データ手法であるSWE-smithなどは、テスト環境のセットアップ、有効なバグの生成、およびテストスイートによるバグの検証を必要とします。…
核心:何を提案したのか
本研究では、効率的な訓練手法である「Soft-Verified Efficient Repository Agents(SERA)」を提案しています。SERAは、教師あり微調整(SFT)のみを使用しながら、完全にオープンソース(データ、手法、コードが公開されている)のモデルの中で最先端の結果を達成し、Devstral-Small-2のような強力なオープンウェイトモデルの性能に匹敵します。 SERAの核心となるのは、新しく開発された「Soft Verified Generation(SVG)」というデータ生成手法です。SVGは、従来のパイプラインから不要な複雑さを取り除いた2つの重要な観察に基づいています。 第一に「ソフト検証(Soft Verification)」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related