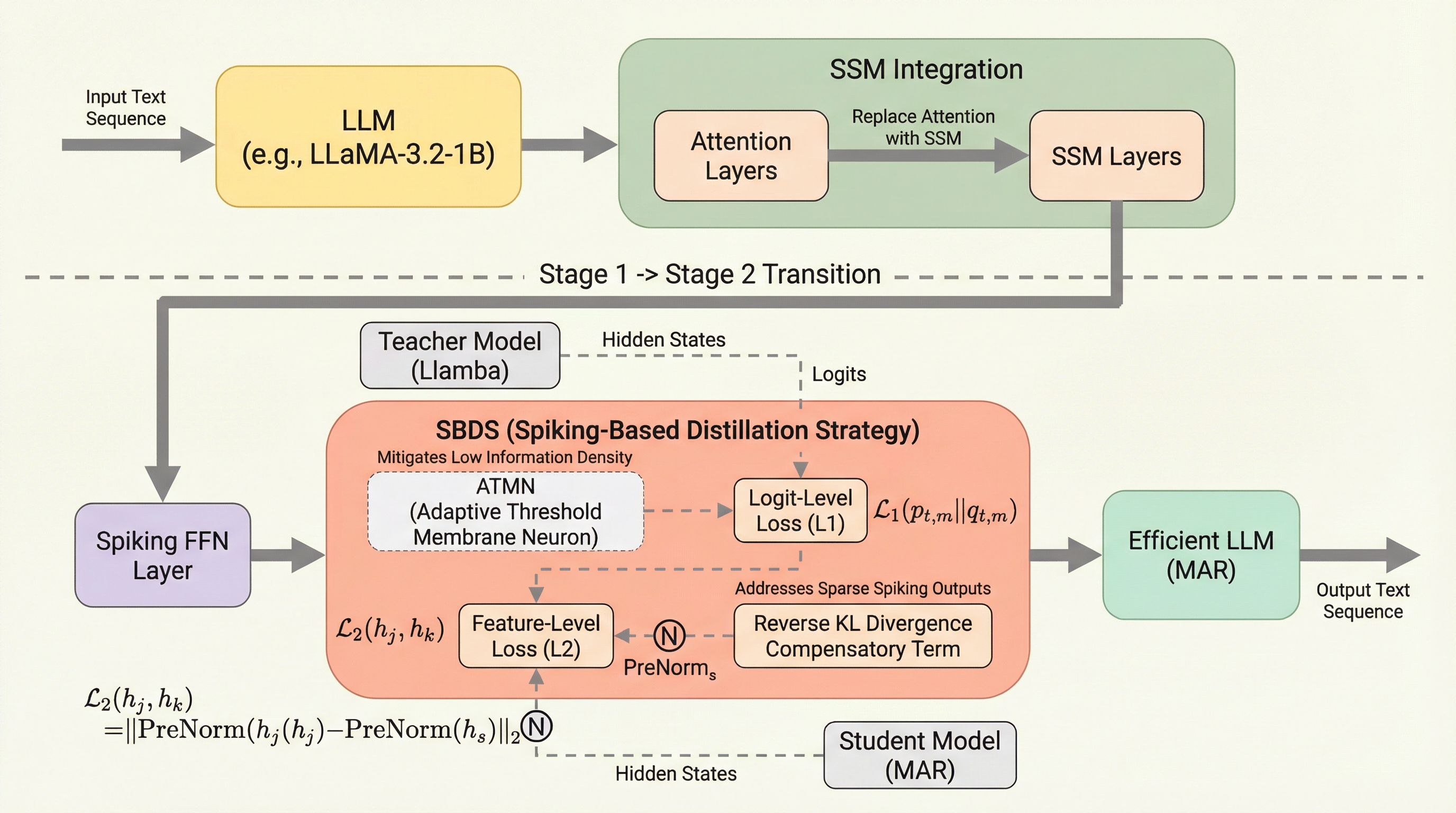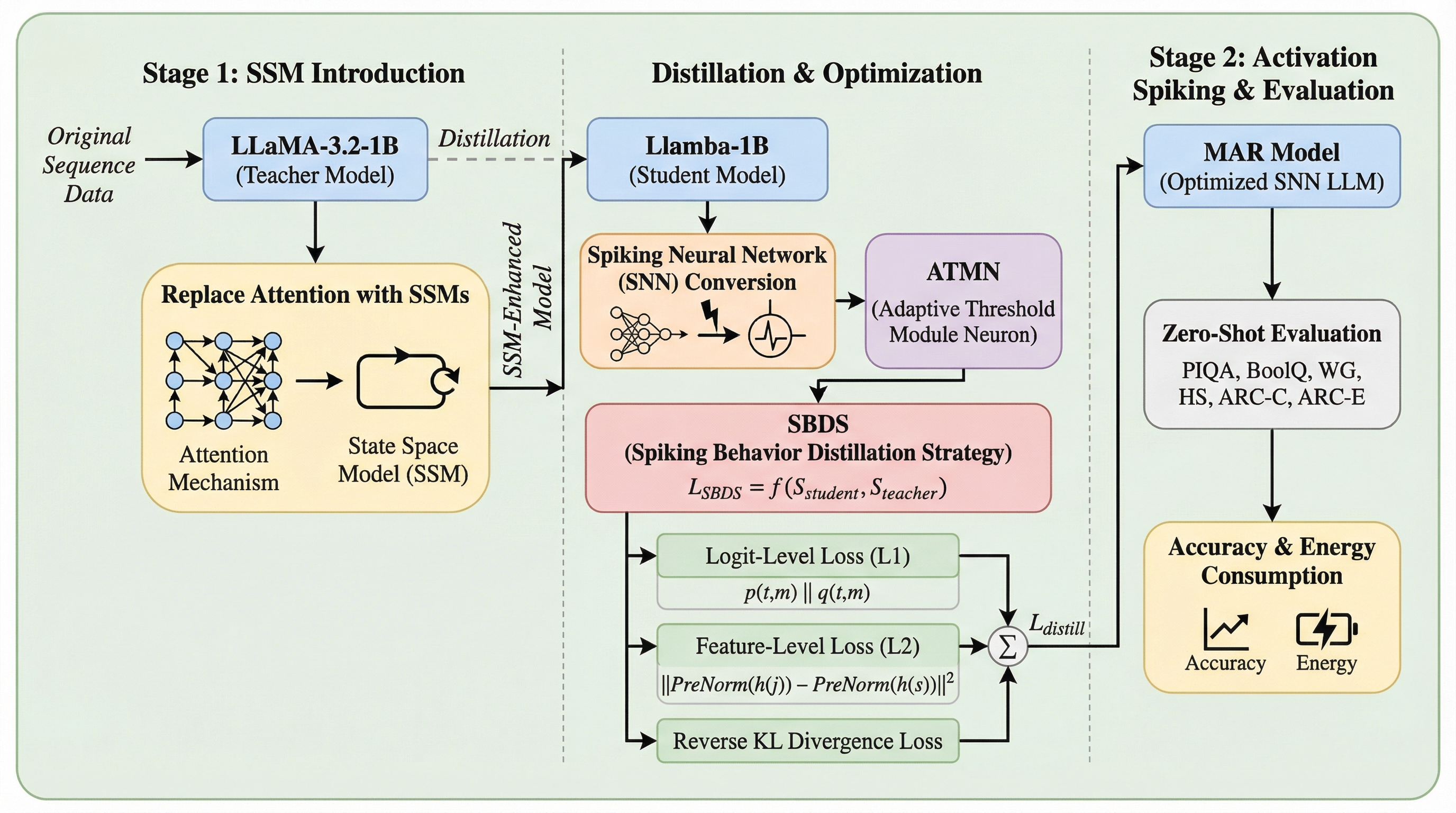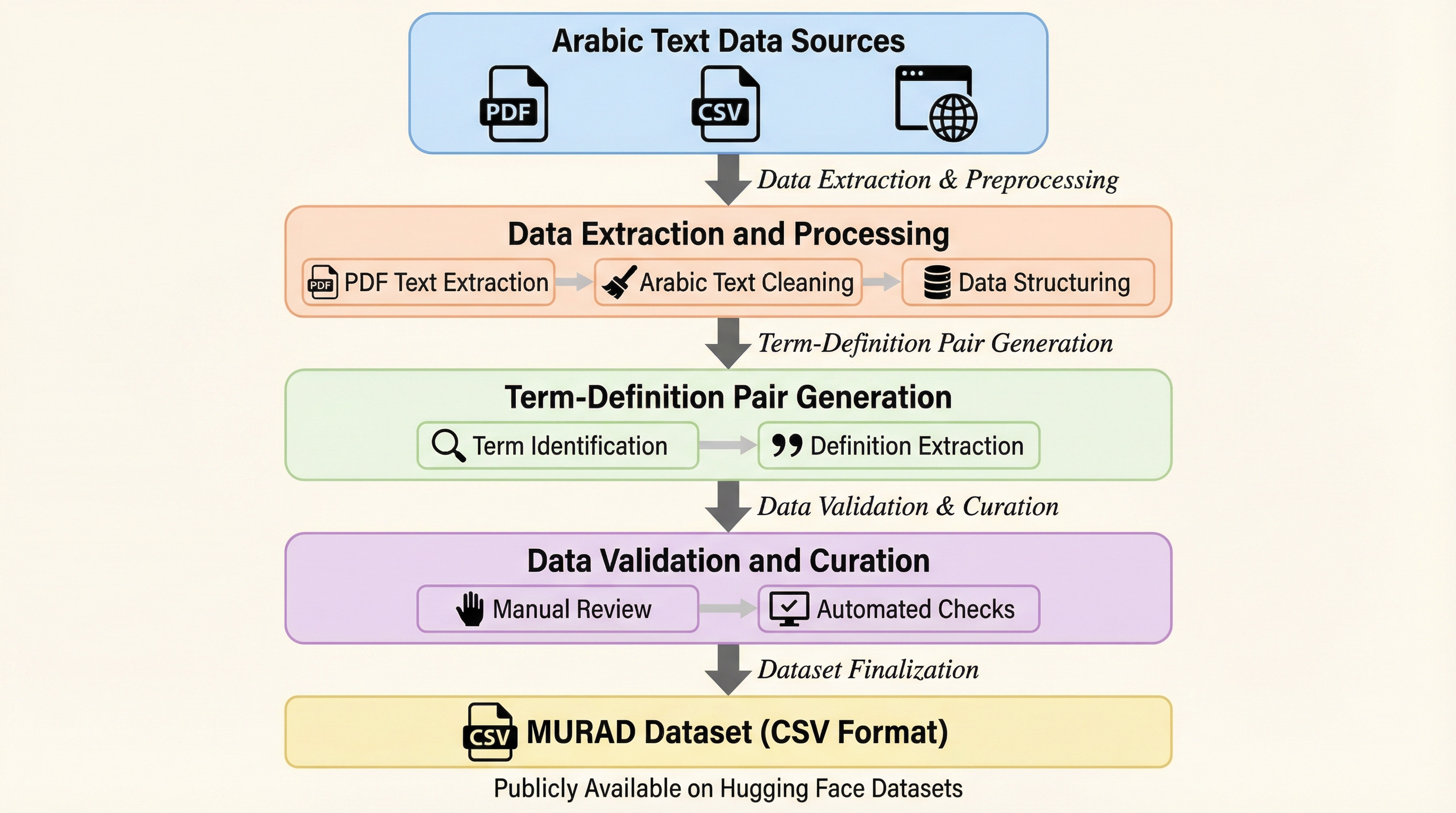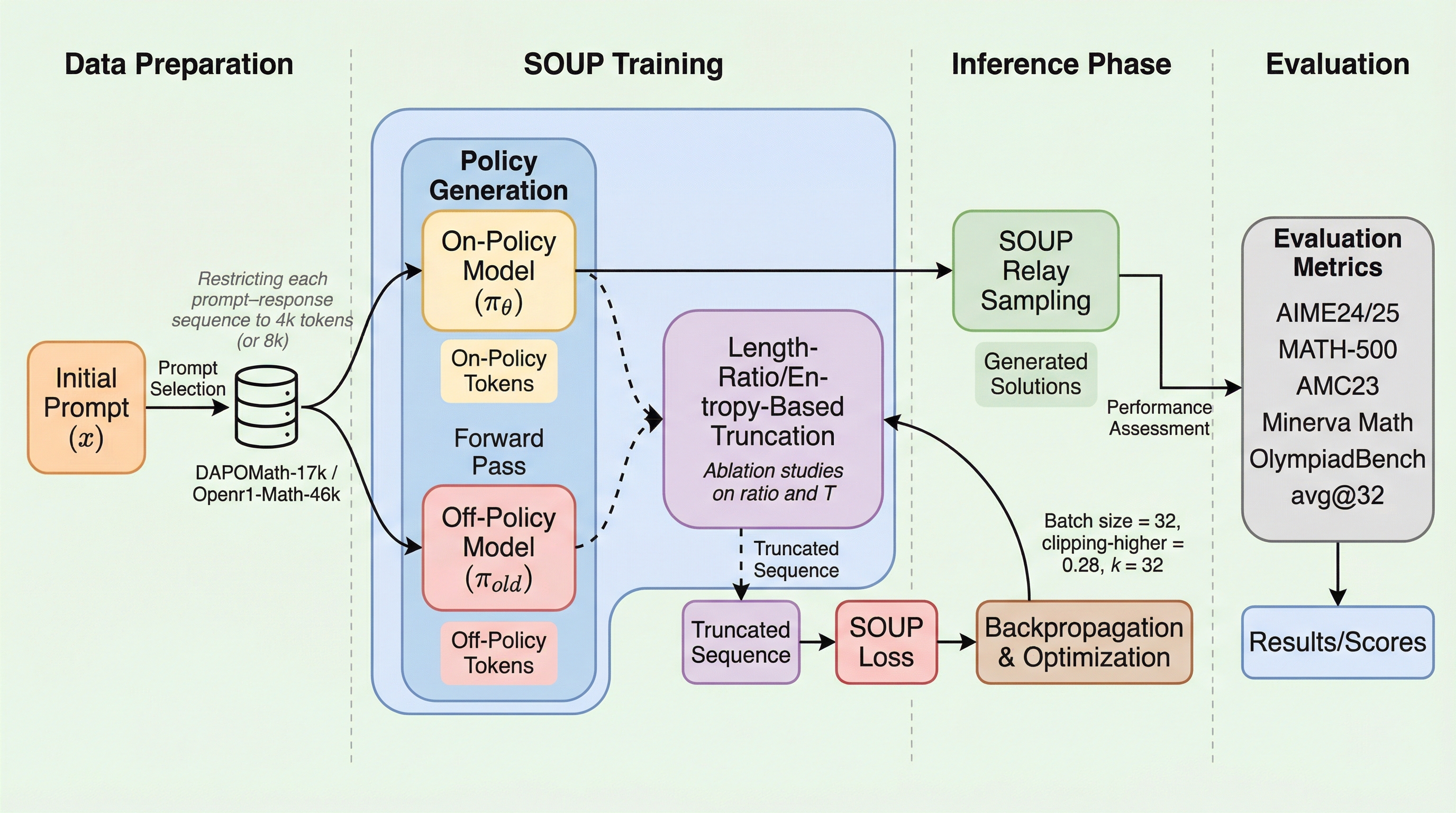
SOUP:大規模言語モデルのためのトークンレベル単一サンプル混合ポリシー強化学習
大規模言語モデルの強化学習において、従来のオンポリシー手法は探索の多様性が不足し、性能が早期に飽和するという課題がありました。本研究では、単一の回答サンプル内で過去のポリシーによる接頭辞と現在のポリシーによる継続生成をトークンレベルで統合する新しい枠組みであるSOUPを提案し、学習の安定性と探索能力の両立を図っています。数学的推論タスクを用いた広範な実験の結果、SOUPは標準的なオンポリシー学習や既存のオフポリシー拡張手法を上回る性能を達成し、より安定した報酬の推移と高い探索効率を実現することが確認されました。