DimStance: 多言語における次元的スタンス分析のためのデータセット
従来のスタンス検出は「賛成」「反対」「中立」といったカテゴリ分類が主流であったが、本研究では感情科学の枠組みを導入し、感情の価数(ポジティブ・ネガティブ)と覚醒度(穏やか・活発)という連続的な数値でスタンスを捉える新しいアプローチを提案した。
TL;DR(結論)
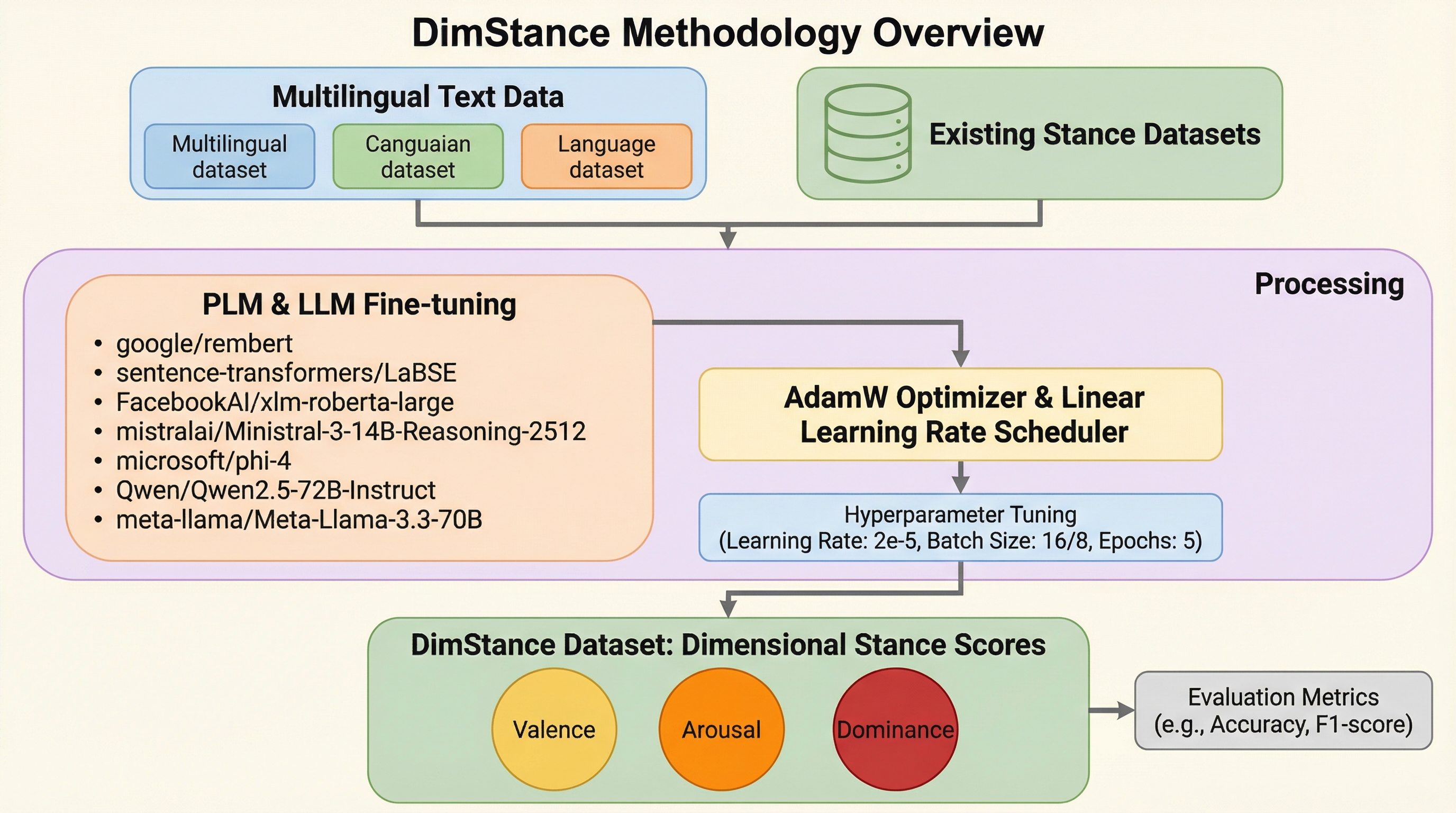
従来のスタンス検出は「賛成」「反対」「中立」といったカテゴリ分類が主流であったが、本研究では感情科学の枠組みを導入し、感情の価数(ポジティブ・ネガティブ)と覚醒度(穏やか・活発)という連続的な数値でスタンスを捉える新しいアプローチを提案した。英語、ドイツ語、中国語に加え、低リソース言語であるナイジェリア・ピジン語やスワヒリ語を含む5言語、政治と環境保護の2ドメインを対象とした、11,746件のターゲット・アスペクトを含む初の実数値アノテーション付きデータセット「DimStance」を構築した。大規模言語モデル(LLM)を用いた回帰タスクの検証により、微調整されたモデルが高い性能を示す一方で、低リソース言語における精度の課題や、トークンベースの予測の限界が明らかになり、今後の多言語かつ感情を考慮したスタンス分析の基盤を提示した。
なぜこの問題か
スタンス検出は、特定のターゲット(人物、組織、政策など)に対する著者の態度を自動的に特定することを目的としている。しかし、既存の研究の多くは、著者の態度を「賛成(Favor)」、「反対(Against)」、あるいは「どちらでもない(Neither/Neutral)」といった定義済みのカテゴリに分類する手法に依存してきた。現実のコミュニケーションにおいて、人々のスタンスは単なる賛否の二択で割り切れるものではない。同じ「賛成」というラベルが付けられる表現であっても、その背後にある感情のトーンや強度は多様である。例えば、ある政策に対して非常に熱狂的に支持する声もあれば、消極的で穏やかな承認を示す声も存在する。このような感情的な差異を無視した従来の分類手法では、なぜ特定の議論において意見が先鋭化し、深刻な分極化が起こるのかという背景を十分に理解することが困難であった。 特に気候変動や政治的議論のような複雑な問題においては、意見が「賛成」か「反対」かだけでなく、その意見がどのような感情的な熱量を持って語られているかを把握することが重要である。…
核心:何を提案したのか
本研究の核心は、実数値による価数と覚醒度(VA)のアノテーションを付与した、世界初の次元的スタンス分析用データセット「DimStance」を導入したことである。このデータセットは、5つの言語(英語、ドイツ語、中国語、ナイジェリア・ピジン語、スワヒリ語)を網羅しており、リソースが豊富な言語だけでなく、低リソース言語もバランスよく含まれている。対象とするドメインは、感情的な表現が多様に現れ、かつ多様なスタンスが存在する「政治」と「環境保護」の2分野に設定されている。具体的には、合計7,365件のテキスト内に含まれる11,746件のターゲット・アスペクトに対して、人間のアノテーターが詳細な数値を割り当てている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related