SOUP:大規模言語モデルのためのトークンレベル単一サンプル混合ポリシー強化学習
大規模言語モデルの強化学習において、従来のオンポリシー手法は探索の多様性が不足し、性能が早期に飽和するという課題がありました。本研究では、単一の回答サンプル内で過去のポリシーによる接頭辞と現在のポリシーによる継続生成をトークンレベルで統合する新しい枠組みであるSOUPを提案し、学習の安定性と探索能力の両立を図っています。数学的推論タスクを用いた広範な実験の結果、SOUPは標準的なオンポリシー学習や既存のオフポリシー拡張手法を上回る性能を達成し、より安定した報酬の推移と高い探索効率を実現することが確認されました。
TL;DR(結論)
大規模言語モデルの強化学習において、従来のオンポリシー手法は探索の多様性が不足し、性能が早期に飽和するという課題がありました。本研究では、単一の回答サンプル内で過去のポリシーによる接頭辞と現在のポリシーによる継続生成をトークンレベルで統合する新しい枠組みであるSOUPを提案し、学習の安定性と探索能力の両立を図っています。数学的推論タスクを用いた広範な実験の結果、SOUPは標準的なオンポリシー学習や既存のオフポリシー拡張手法を上回る性能を達成し、より安定した報酬の推移と高い探索効率を実現することが確認されました。
なぜこの問題か
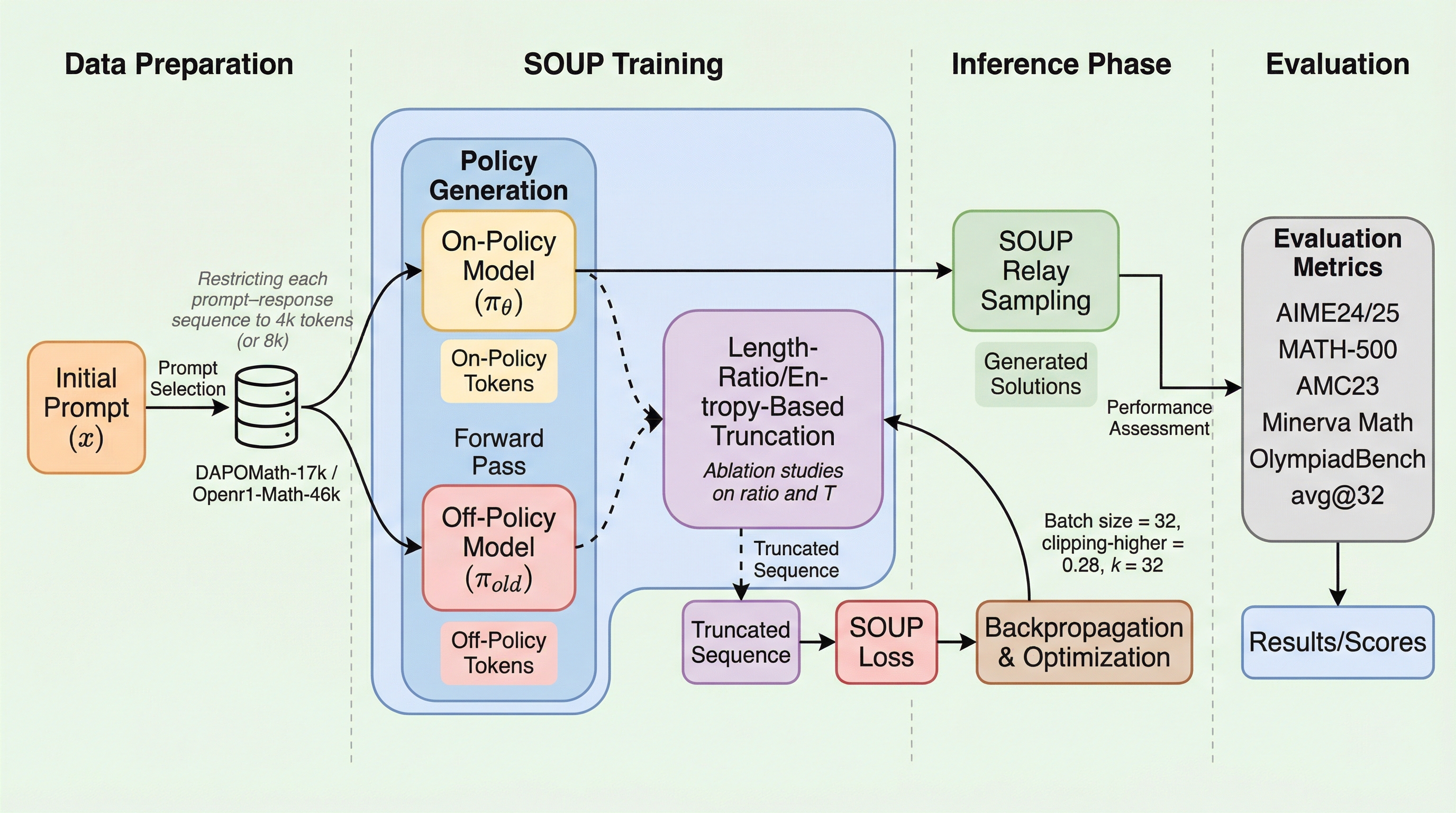
大規模言語モデル(LLM)の事後学習において、人間からのフィードバックや検証可能な報酬を用いた強化学習は、モデルの推論能力を向上させるための中心的な技術となっています。特に、Group Relative Policy Optimization(GRPO)のような手法は、価値関数ネットワークの訓練を不要にすることで計算コストを大幅に削減しつつ、高い性能を維持できるため、広く注目を集めています。しかし、現在主流となっているこれらの手法の多くは、現在のポリシーモデルから生成されたサンプルのみを用いて勾配を推定するオンポリシー学習の枠組みに従っています。オンポリシー学習は理論的には不偏な勾配推定と収束性が保証されていますが、実際にはモデルが既に持っている行動パターンを繰り返し強化するだけに留まり、確率の低い未知の有望なサンプルを抑制してしまう傾向があります。 このサンプリングの多様性の欠如は、モデルが自身の能力の限界を超えて成長することを妨げ、性能が早期に頭打ちになる「飽和状態」を引き起こします。…
核心:何を提案したのか
本研究では、オフポリシー学習とオンポリシー学習を単一のサンプル内でトークンレベルで統合する新しいフレームワーク「Single-sample Mix-pOlicy Unified Paradigm(SOUP)」を提案しています。この手法の核心的なアイデアは、生成される一つの回答シーケンスを二つの部分に分け、それぞれの生成ポリシーを戦略的に切り替えることにあります。具体的には、回答の冒頭部分(接頭辞)を過去のポリシー(挙動ポリシー)からサンプリングし、その後の続き(継続部分)を現在の学習対象であるポリシーから生成します。このように、オフポリシーの影響を接頭辞の範囲に限定し、回答の核心となる後半部分をオンポリシーで生成することで、学習の安定性を維持しながら過去の多様な探索情報を活用することが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related