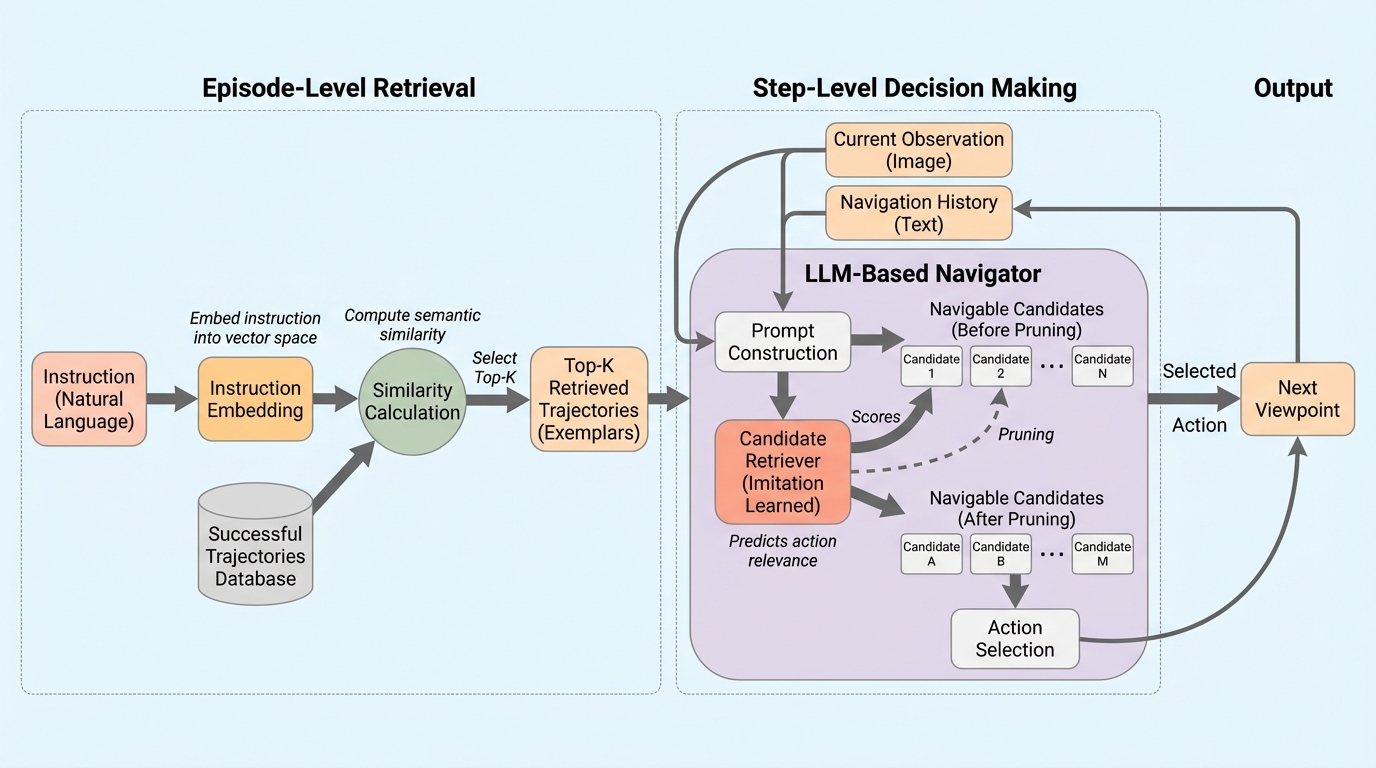
効率的な視覚と言語ナビゲーションのための、移動可能候補の取得を学習する
大規模言語モデルをナビゲータとして用いる視覚と言語ナビゲーションでは、毎回の指示解釈を最初からやり直し、各ステップで冗長な移動候補すべてを読み比べる必要があるため、意思決定が非効率かつ不安定になりやすいと整理されています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルをナビゲータとして用いる視覚と言語ナビゲーションでは、毎回の指示解釈を最初からやり直し、各ステップで冗長な移動候補すべてを読み比べる必要があるため、意思決定が非効率かつ不安定になりやすいと整理されています。
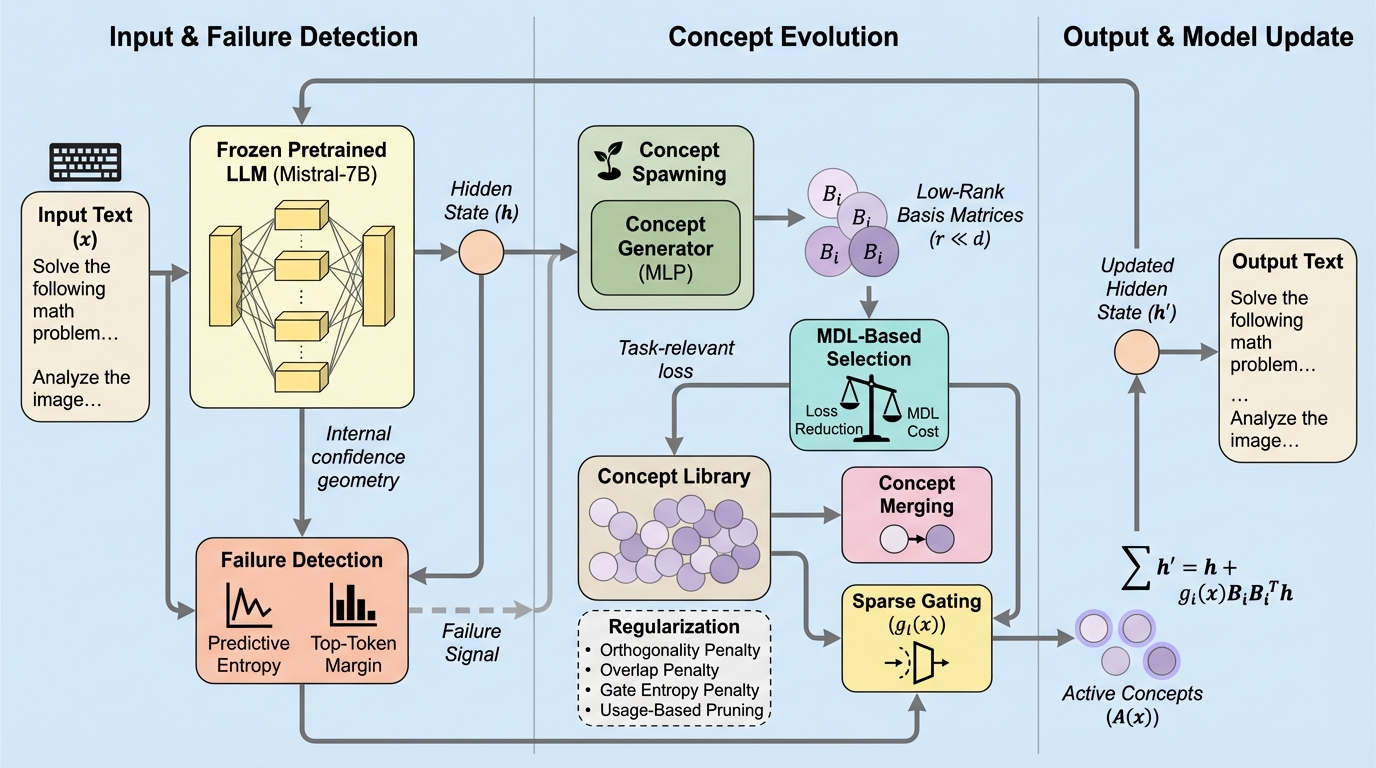
大規模言語モデルは多くの推論課題で強い一方、推論中に新しい抽象を組み立てる合成的推論では、内部表現空間が固定されていること自体がボトルネックになり、探索を増やしても精度が崩れやすいと位置づけられています。
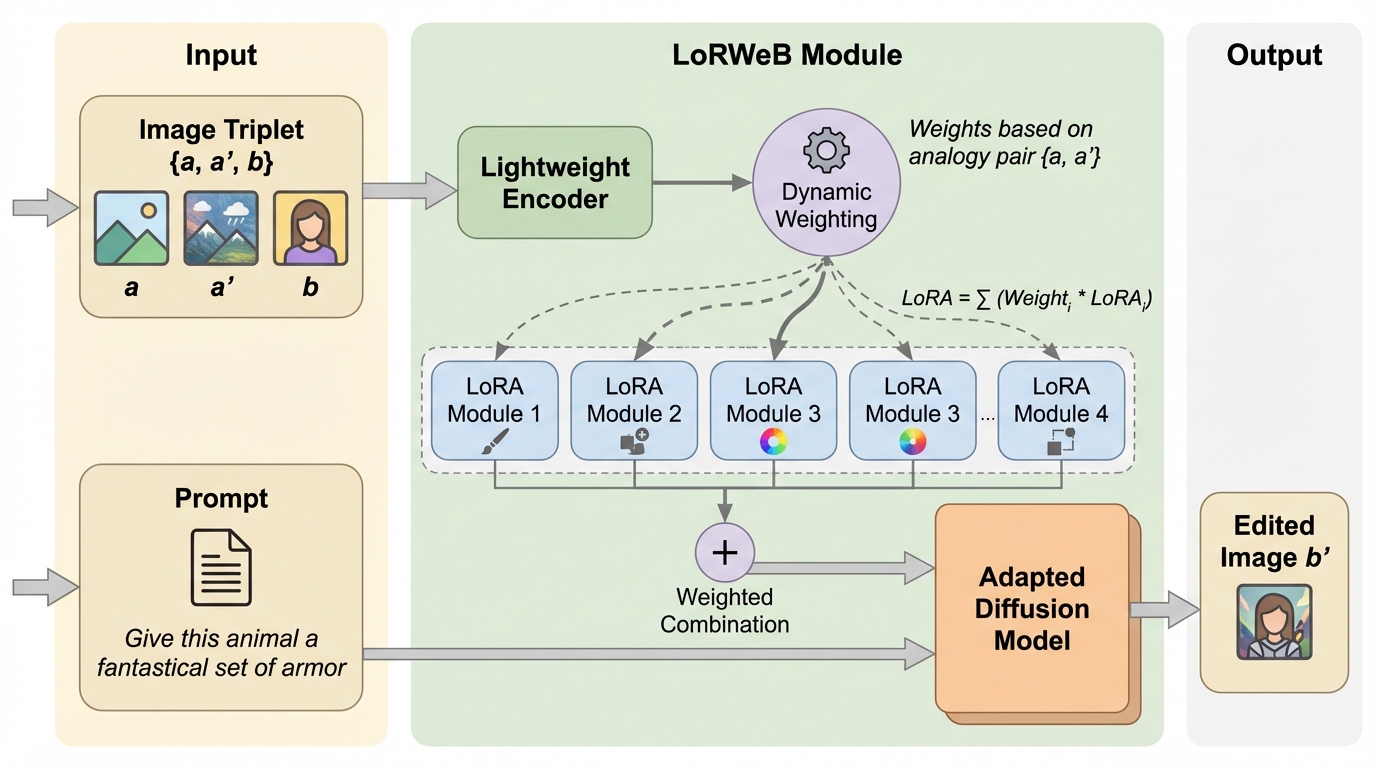
言葉では説明しにくい編集でも、見本の「前→後」画像から変換を読み取り別画像へ移す視覚アナロジーは有用ですが、単一のLoRAに多様な変換を詰め込む設計は未知の変換への一般化を妨げやすいです。 / LoRWeBは、複数のLoRAを「変換の部品」として学習可能な基底にしておき、入力された三つ組(a, a′, b)を手がかりに軽量エンコーダが混合係数を推定して、推論時に1つのMixed LoRAとして動的に合成して注入します。 / 包括的な評価により最先端の性能が示され、学習時に見ていない視覚変換への一般化も大きく改善したと報告されており、LoRAを基底分解して混ぜる方針が柔軟な例示ベース編集に有望だと示唆されます。
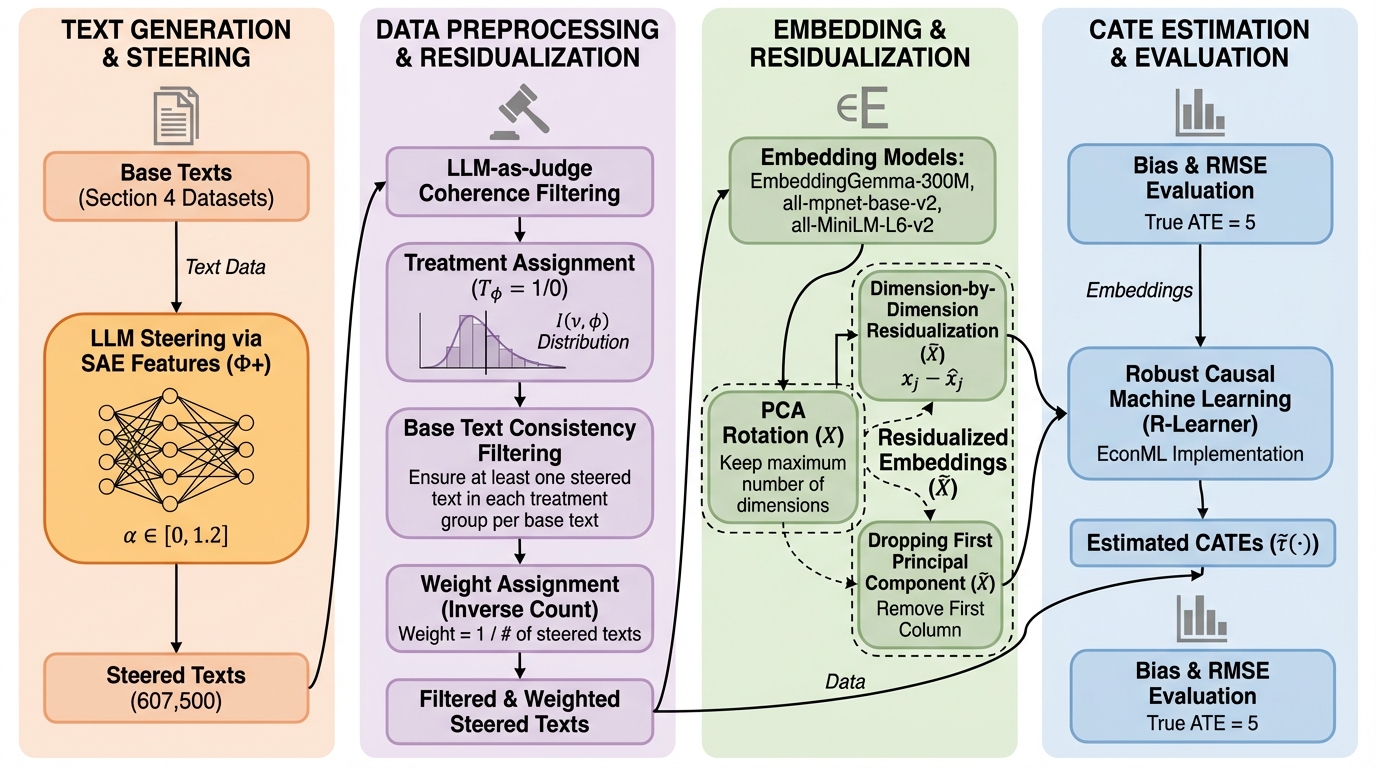
テキストを「処置」として因果効果を推定すると、同じ文章の中に処置情報と共変量情報が混ざりやすく、素朴な推定では大きな偏りが出たり、重なりの仮定が崩れたりします。 / 本研究は、疎オートエンコーダで解釈しやすい潜在特徴を仮説として選び、ステアリングでその特徴を主に変えた疑似反実仮想テキストを生成し、さらに埋め込みから処置情報を除く残差化で推定を安定化します。 / 理論整理と半合成シミュレーションにより、狙った特徴の変動を誘発できること、そして埋め込みをそのまま調整に使う方法で生じる推定誤差を残差化が緩和し得ることが示されています。
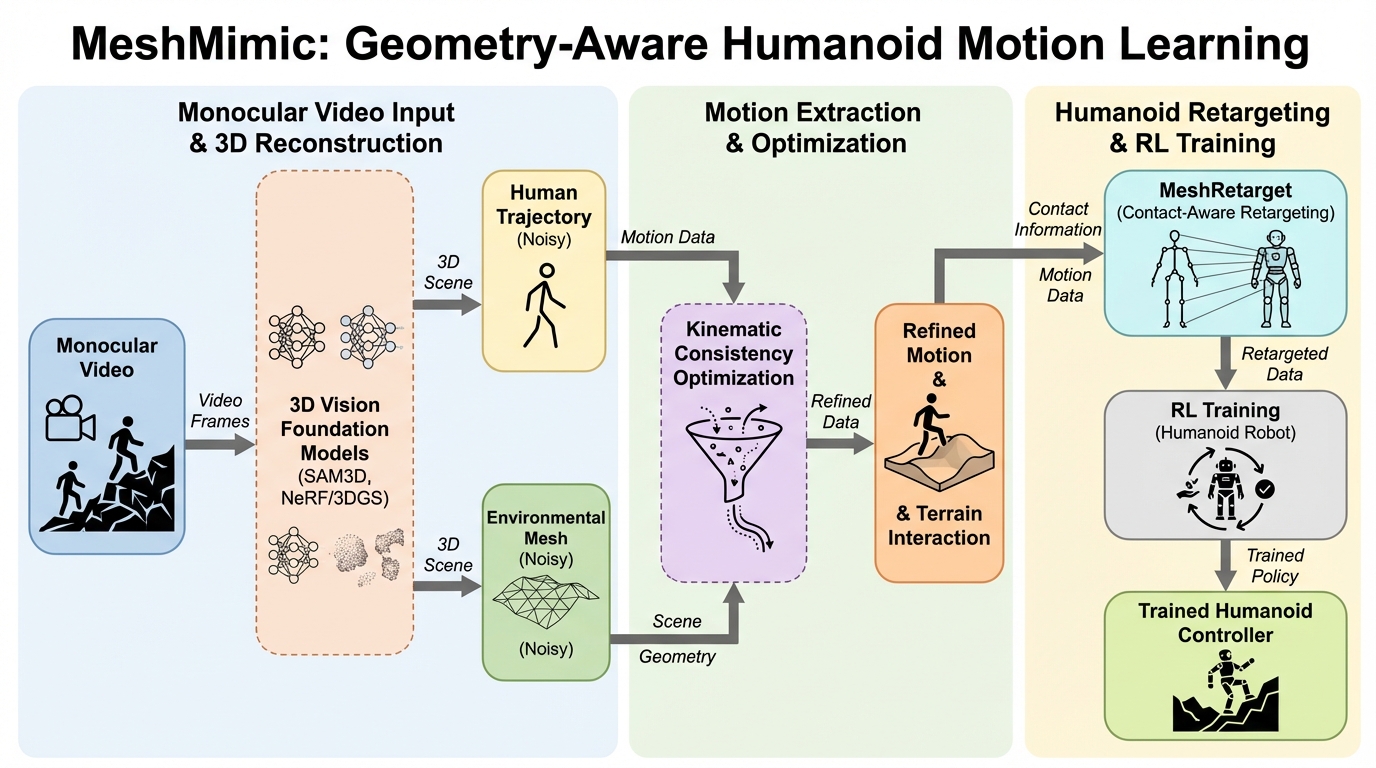
MeshMimicは、単眼の動画から人の動きだけを取り出すのではなく、その動きが成立している地形や物体の三次元形状も同時に復元し、動作と地形の相互作用を結び付けた参照データとしてヒューマノイドの学習に使う枠組みです。
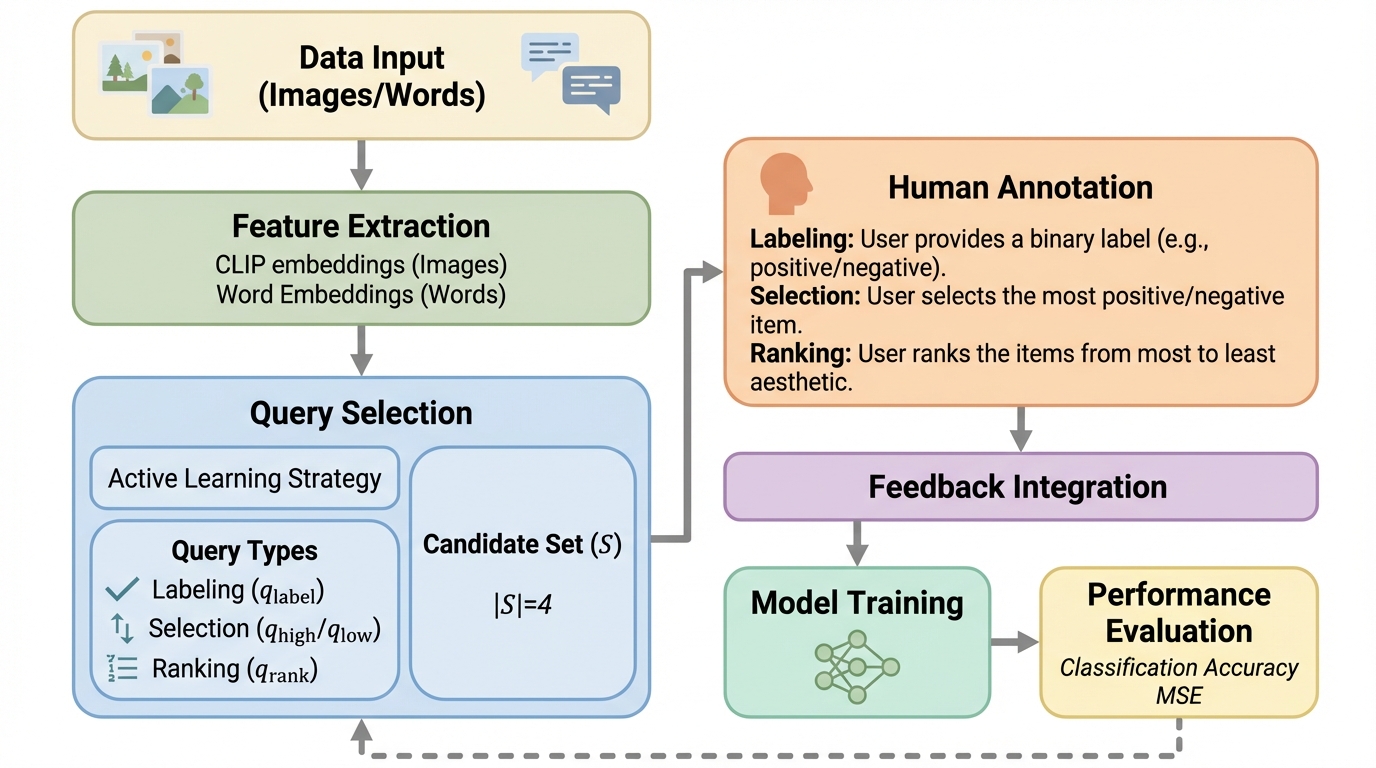
人を二値ラベルの「回答者」として扱うだけでは、1回の対話で得られる情報が最大でも1ビット程度に制限され、少ないデータで分類器を学びたい場面ほど対話回数と負担が増えやすいです。 / 本研究は、項目集合から代表例を選んでラベルも付ける選択クエリと、項目を強い順に並べて最後の正例位置まで示すランキングクエリを導入し、埋め込み空間での分類境界との距離が人の暗黙スコアに結び付くという観測に基づいて応答確率をモデル化します。 / シミュレーション注釈者でサンプル複雑度の大幅な削減を示し、さらに注釈コストを入れた情報レート最適化により、単語感情分類では従来のラベルのみ能動学習より学習時間が57%超短縮されたと報告しています。
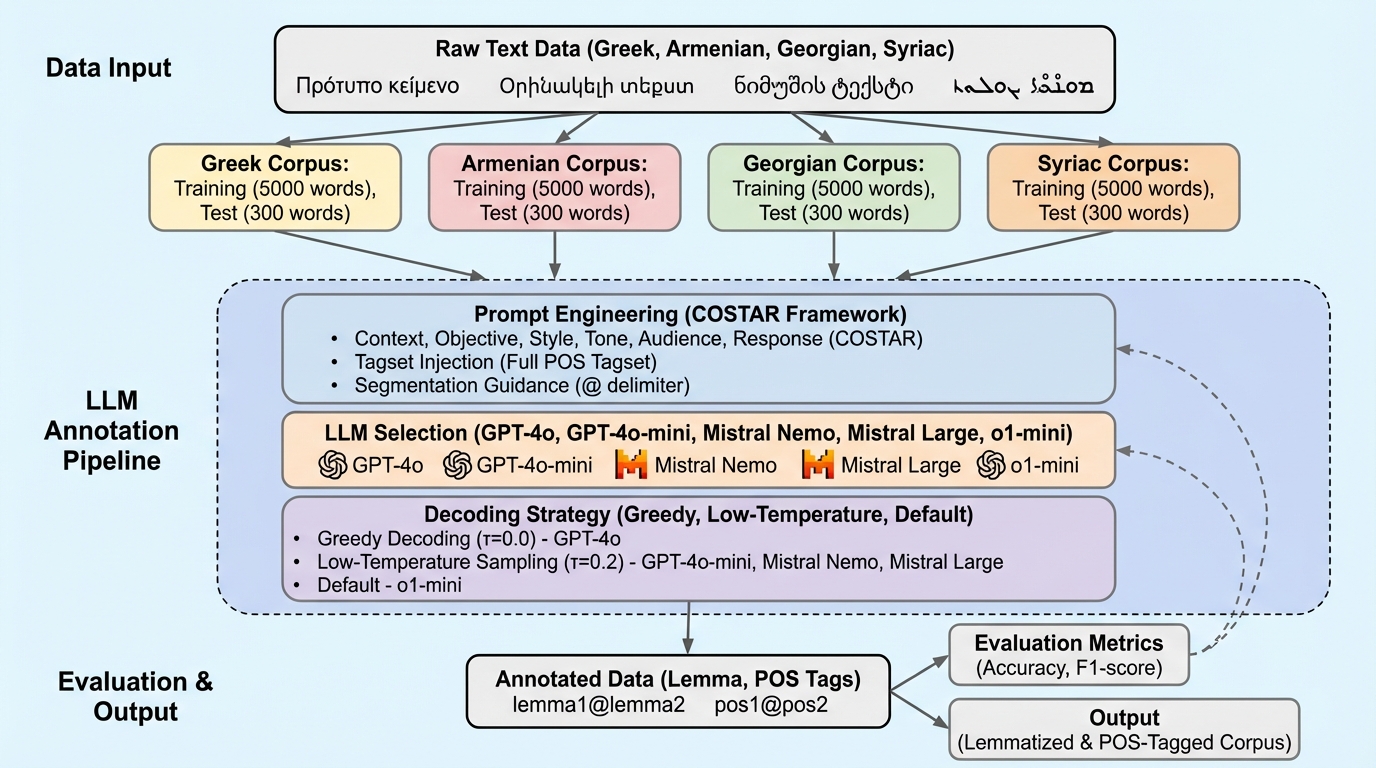
歴史的で注釈資源が乏しい4言語(古代ギリシア語・古典アルメニア語・古ジョージア語・シリア語)のレンマ化と品詞付与を、微調整なしの大規模言語モデルでもどこまで開始できるかを、同一条件のベースラインと並べて検証した研究です。
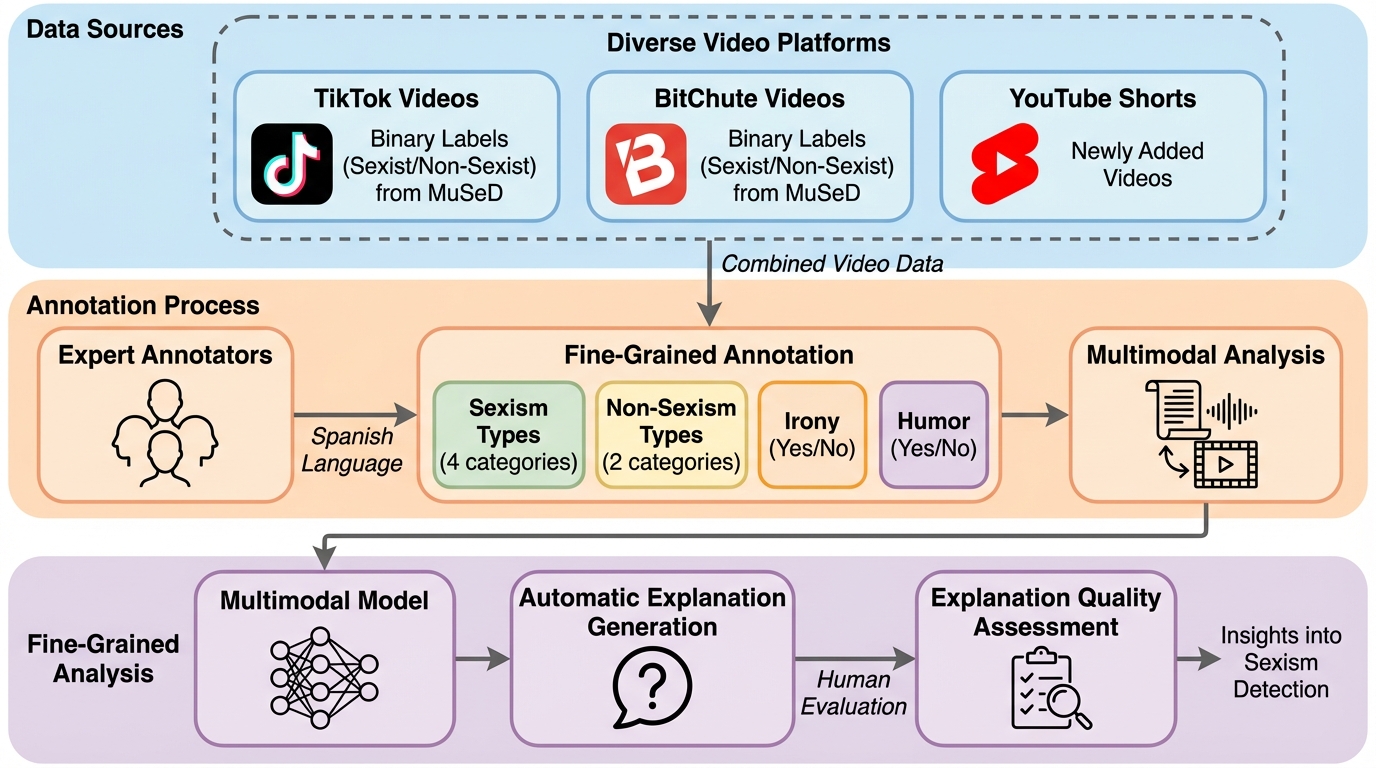
オンライン上の性差別は形が複数あり、性差別か非性差別かの二値だけでは、文脈に依存する微妙で暗黙的な表現が見落とされやすく、説明がない自動フラグは透明性の面でも課題になり得ます。 / そこで、スペイン語のソーシャルメディア動画を対象に、二値注釈と詳細注釈を併せ持つFineMuSeと、性差別・非性差別に加えて皮肉とユーモアも扱える三層の階層タクソノミーを提示し、二値検出と詳細検出の両方で多数の大規模言語モデルを評価しています。 / その結果、マルチモーダル大規模言語モデルはニュアンスのある性差別の同定で人手注釈者と競争的な性能を示す一方、視覚的手掛かりで伝わる「複数タイプの併発」を捉える点には難しさが残ると報告されています。
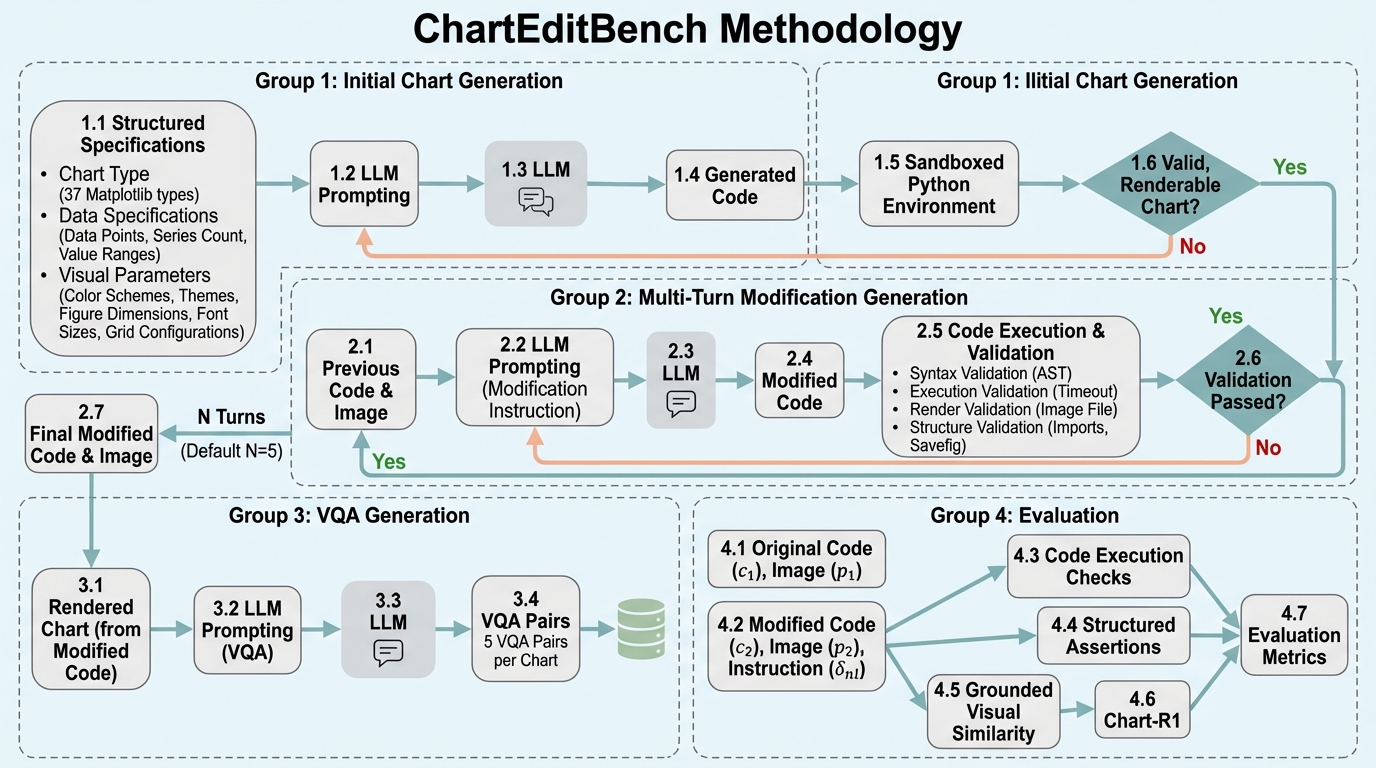
マルチモーダル言語モデルは単発のチャート生成では高い性能を示しやすい一方で、実務のように既存の図を何度も直しながら仕上げる場面で必要な「共通理解の維持」と「過去の編集の追跡」を、長い会話の中で安定して行えるかは十分に測れていません。
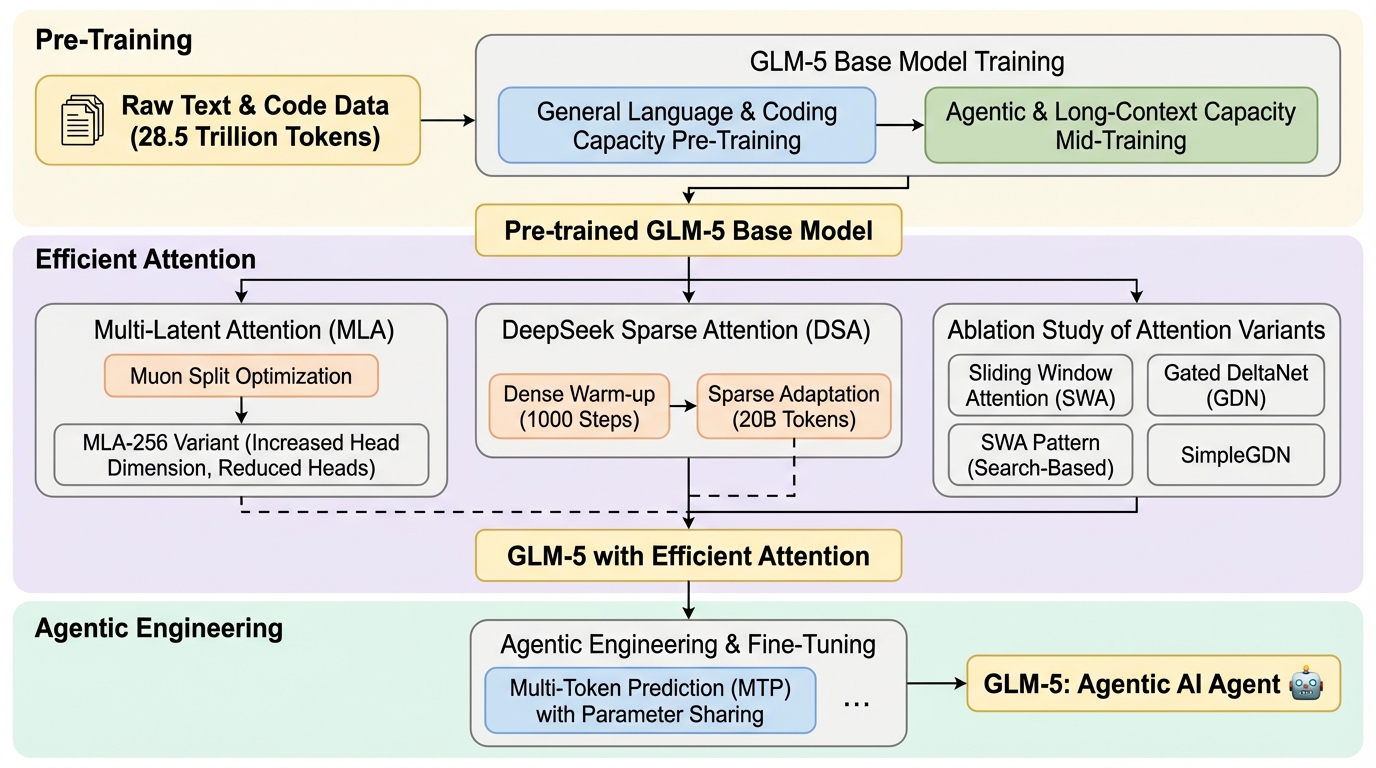
GLM-5は、思いつきに任せたvibe codingではなく、計画・実行・自己修正までをエージェントが進めるagentic engineeringを成立させる基盤モデルとして提案されています。 / 長文脈で高コストになりやすい注意計算をDSA(DeepSeek Sparse Attention)で効率化しつつ、生成(ロールアウト)と学習を切り離す非同期の強化学習基盤と、長い相互作用から学びやすい非同期Agent RLアルゴリズムを組み合わせています。 / 主要な公開ベンチマークやArtificial Analysis Intelligence Index v4.0、LMArenaなどで強い結果が示され、特に実世界のコーディング課題で従来の基準を押し上げる能力が強調されています。