潜在的なテキスト処置による因果効果推定
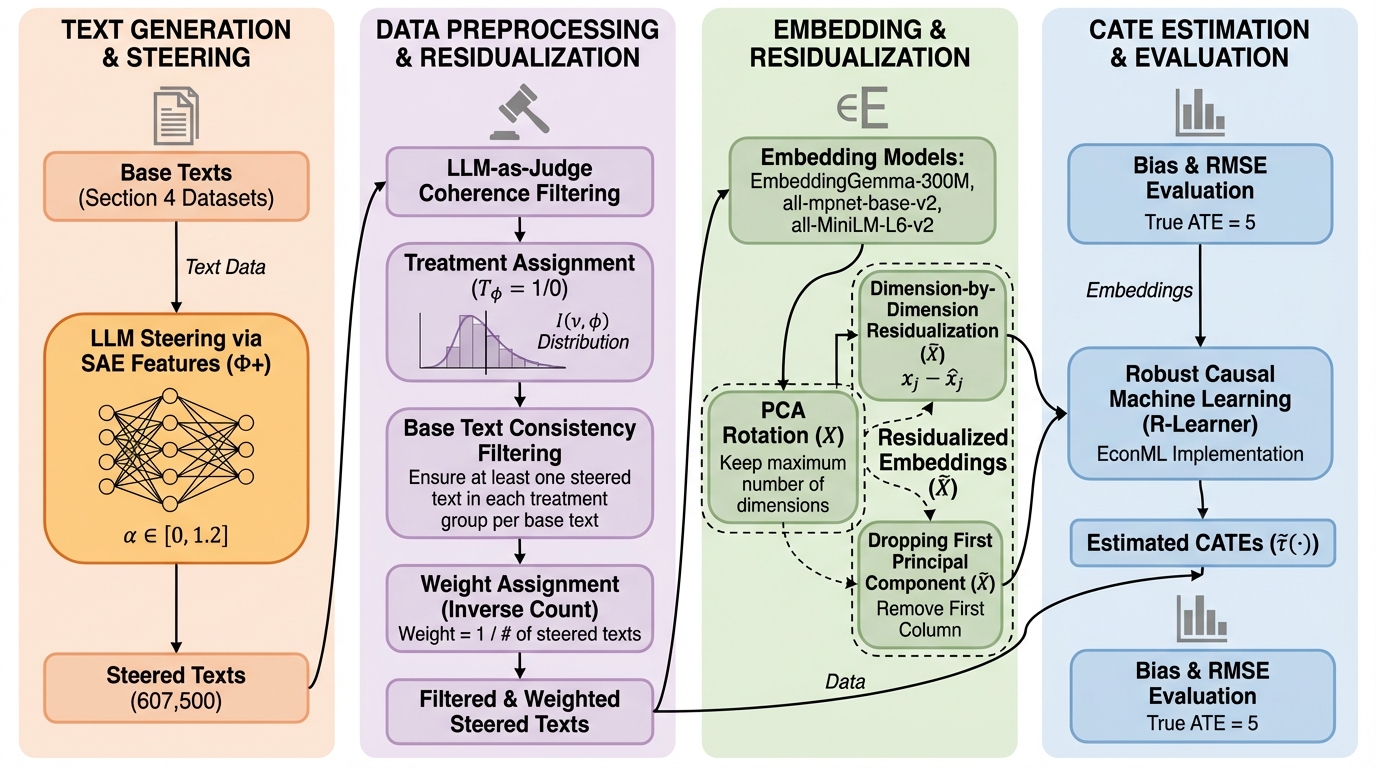
テキストを「処置」として因果効果を推定すると、同じ文章の中に処置情報と共変量情報が混ざりやすく、素朴な推定では大きな偏りが出たり、重なりの仮定が崩れたりします。 / 本研究は、疎オートエンコーダで解釈しやすい潜在特徴を仮説として選び、ステアリングでその特徴を主に変えた疑似反実仮想テキストを生成し、さらに埋め込みから処置情報を除く残差化で推定を安定化します。 / 理論整理と半合成シミュレーションにより、狙った特徴の変動を誘発できること、そして埋め込みをそのまま調整に使う方法で生じる推定誤差を残差化が緩和し得ることが示されています。
TL;DR(結論)
- テキストを「処置」として因果効果を推定すると、同じ文章の中に処置情報と共変量情報が混ざりやすく、素朴な推定では大きな偏りが出たり、重なりの仮定が崩れたりします。
- 本研究は、疎オートエンコーダで解釈しやすい潜在特徴を仮説として選び、ステアリングでその特徴を主に変えた疑似反実仮想テキストを生成し、さらに埋め込みから処置情報を除く残差化で推定を安定化します。
- 理論整理と半合成シミュレーションにより、狙った特徴の変動を誘発できること、そして埋め込みをそのまま調整に使う方法で生じる推定誤差を残差化が緩和し得ることが示されています。
なぜこの問題か
テキストが下流の結果に与える因果的な影響を理解することは、多くの応用領域で中心的な課題になります。たとえば政治的な発話のどの側面が支持に効くのか、あるいはソーシャルメディア投稿のどの表現が関与を高めるのかといった問いです。こうした因果効果を推定するには、本来はテキスト特徴を系統的に変える統制実験が必要になりますが、現実には二つの難しさがあります。第一に、文章の可読性や自然さを保ちながら、特定の特徴だけを狙って変えることが難しい点です。第二に、意図した変更と、それに付随して起きる別の変化を分離して推定する必要がある点です。大規模言語モデルは大量のテキスト生成を可能にしましたが、「制御された変動」を作るには追加の設計が必要になります。さらに、ステアリングの介入は外科的に一点だけを動かすとは限らず、相関する別特徴まで一緒に揺らす可能性があります。すると、処置群と対照群の差が単一要因に還元できず、推定の解釈が難しくなります。加えて、共変量として使う埋め込みが強力すぎると処置自体をほぼ完全に予測してしまい、傾向スコアが極端になるなどして重なり(オーバーラップ、ポジティビティ)の仮定が破れます。…
核心:何を提案したのか
本研究が提案するのは、潜在的なテキスト介入を生成し、その因果効果推定までを一続きにしたエンドツーエンドのパイプラインです。大きく分けると、仮説生成、ステアリングによる疑似反実仮想テキスト生成、そして頑健な因果推定の三段で構成されます。まず仮説生成では、介入したい意味概念についてラベルが付いたテキスト集合を起点にし、疎オートエンコーダの潜在特徴を候補として探索します。その際、SAE表現に対してプローブを行い、意味的に関連が強く、かつ安定して現れる特徴を「仮説」として抽出します。次に、その特徴を処置として言語モデルの生成過程に介入し、ターゲット特徴が主に変化するような出力を生成します。ただし生成された文は真の反実仮想ではないため、本研究では疑似反実仮想として扱い、不要な揺らぎは後段の推定で調整します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related