GLM-5:バイブ・コーディングからエージェント的エンジニアリングへ
GLM-5は、思いつきに任せたvibe codingではなく、計画・実行・自己修正までをエージェントが進めるagentic engineeringを成立させる基盤モデルとして提案されています。 / 長文脈で高コストになりやすい注意計算をDSA(DeepSeek Sparse Attention)で効率化しつつ、生成(ロールアウト)と学習を切り離す非同期の強化学習基盤と、長い相互作用から学びやすい非同期Agent RLアルゴリズムを組み合わせています。 / 主要な公開ベンチマークやArtificial Analysis Intelligence Index v4.0、LMArenaなどで強い結果が示され、特に実世界のコーディング課題で従来の基準を押し上げる能力が強調されています。
TL;DR(結論)
- GLM-5は、思いつきに任せたvibe codingではなく、計画・実行・自己修正までをエージェントが進めるagentic engineeringを成立させる基盤モデルとして提案されています。
- 長文脈で高コストになりやすい注意計算をDSA(DeepSeek Sparse Attention)で効率化しつつ、生成(ロールアウト)と学習を切り離す非同期の強化学習基盤と、長い相互作用から学びやすい非同期Agent RLアルゴリズムを組み合わせています。
- 主要な公開ベンチマークやArtificial Analysis Intelligence Index v4.0、LMArenaなどで強い結果が示され、特に実世界のコーディング課題で従来の基準を押し上げる能力が強調されています。
なぜこの問題か
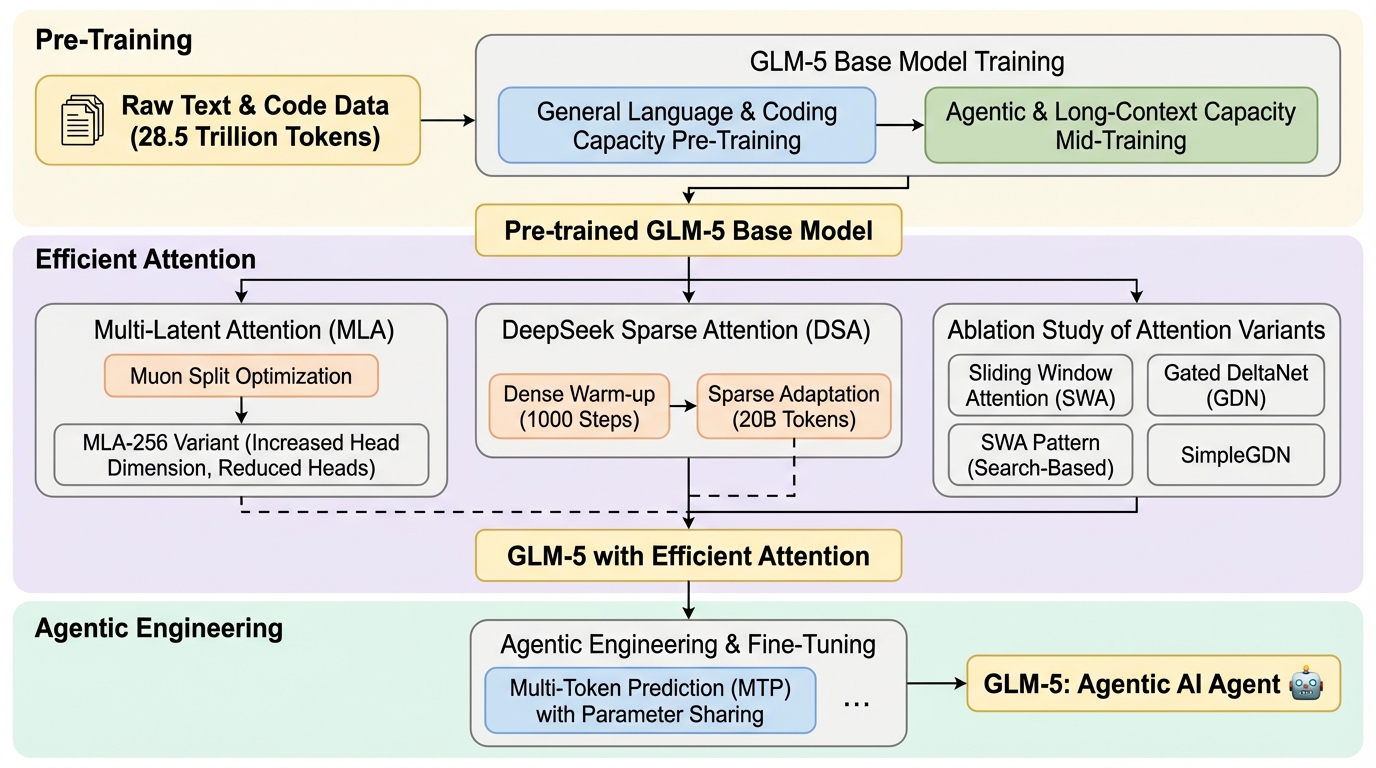
大規模言語モデルが「知識を答える仕組み」から「課題を解く主体」へ近づくほど、計算コストと現実環境への適応が主要なボトルネックになると述べられています。とりわけソフトウェア工学のように、単発の正答よりも、計画立案、ツール実行、途中経過の検証、失敗時の修正といった連続行動が必要な領域では、モデルが長時間にわたって一貫性を保つことが重要になります。本文抜粋では、コーディングエージェントが何時間も自律的にコードを書き続ける状況が想定されており、その際には入出力の文脈が長くなり、参照すべき情報の範囲も拡大します。ところが従来の密な注意機構は、文脈長が増えるほど計算負荷が急増しやすく、128K文脈では実用上の重さが問題になります。さらに、学習後段の強化学習では、生成と学習が同期している設計だと反復が遅くなり、大規模な軌跡探索を回しにくいという課題意識も示されています。長い相互作用から学ぶにはロールアウト量を増やしたい一方で、同期が詰まり点になると探索規模が制約されます。したがって、長文脈の忠実性を維持しつつ推論・学習コストを下げ、長期の相互作用データを効率よく学べる学習基盤へ更新することが、この研究の出発点になります。
核心:何を提案したのか
GLM-5は、vibe codingからagentic engineeringへの移行を狙う次世代の基盤モデルとして提示されています。Abstractでは、先行モデルが持っていたARC(Agentic・Reasoning・Coding)能力を土台にしつつ、DSA(DeepSeek Sparse Attention)を採用して学習と推論のコストを大きく下げながら、長文脈の忠実性を維持する点が中心的な提案として述べられています。あわせて、アラインメントと自律性を前進させるために、生成(ロールアウト)と学習を分離する新しい非同期の強化学習インフラを実装し、学習後工程の効率を大幅に高めたとされています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related