ChartEditBench:マルチモーダル言語モデルにおける「根拠付き・複数ターンのチャート編集」を評価するベンチマーク。
マルチモーダル言語モデルは単発のチャート生成では高い性能を示しやすい一方で、実務のように既存の図を何度も直しながら仕上げる場面で必要な「共通理解の維持」と「過去の編集の追跡」を、長い会話の中で安定して行えるかは十分に測れていません。
TL;DR(結論)
- マルチモーダル言語モデルは単発のチャート生成では高い性能を示しやすい一方で、実務のように既存の図を何度も直しながら仕上げる場面で必要な「共通理解の維持」と「過去の編集の追跡」を、長い会話の中で安定して行えるかは十分に測れていません。
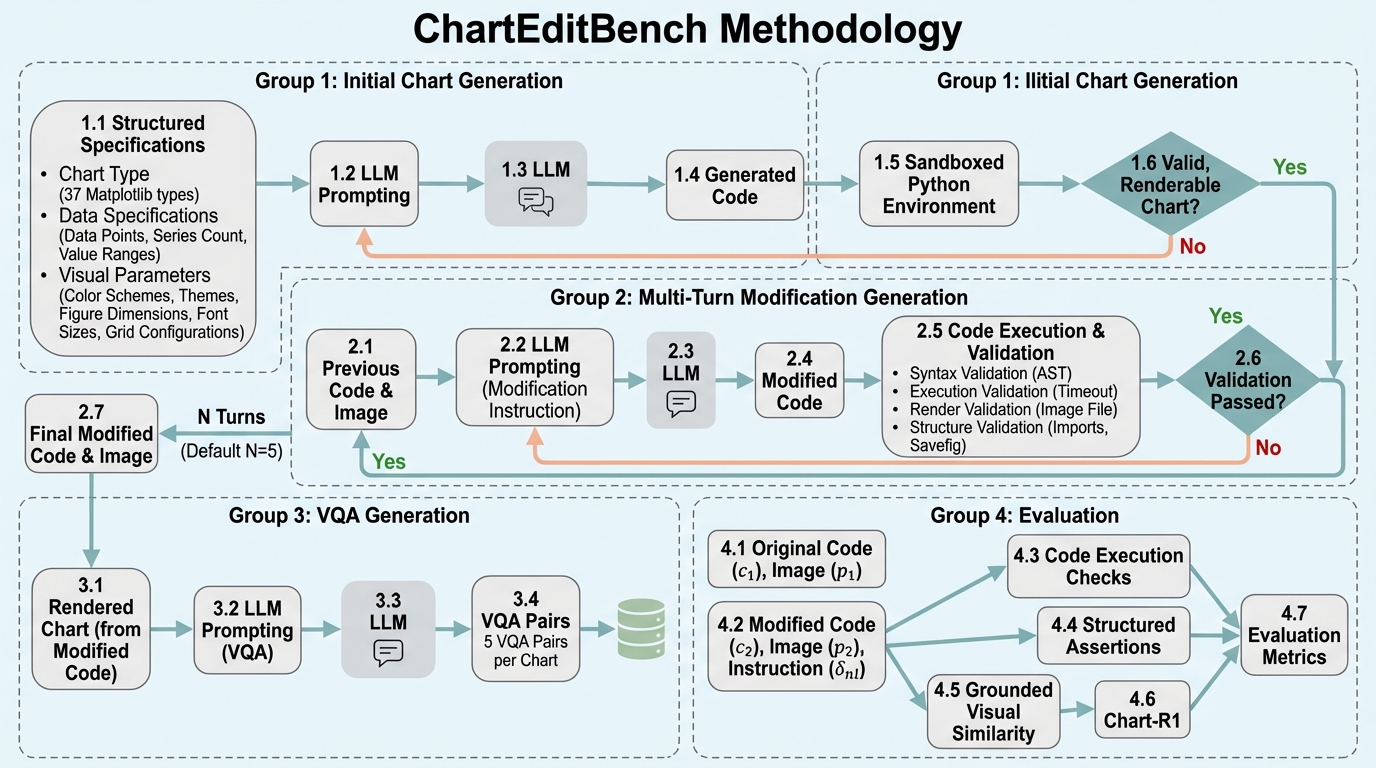
- ChartEditBenchは、初期のコードとチャート画像を起点に、目標画像または変更指示に従ってコードを段階的に更新させるベンチマークで、難易度を制御した多数の編集連鎖と、人手で厳密に確認したサブセットを用意して、複数ターンでの編集の継続性そのものを評価対象にしています。
- 実験では、ターンが進むほどエラーが蓄積し共有コンテキストが崩れやすく、見た目の調整は比較的できてもデータ中心の変換では実行失敗が増えることが観察され、実行確認・画素レベルの視覚類似・コードの論理検証を組み合わせた評価の重要性が示されています。
なぜこの問題か
近年のマルチモーダル言語モデルは、自然言語の記述や入力画像からチャートを生成するような単発タスクで急速に進歩してきましたが、探索的データ分析の現場で価値が出る能力は「一度で作り切る力」だけではありません。実務では、開発者や分析者、技術ライターが、既存の可視化仕様を土台にしながら、エンコーディングの調整、統計的な重ね合わせの追加、レイアウトの組み替えなどを、フィードバックに応じて反復的に行います。ここでは、前のターンまでに決めたことを共通理解として保持し、どこを変えてどこを維持するべきかを追跡し続ける必要があります。単発の生成ベンチマークや単問の質問応答では、この「状態をまたいだ編集の一貫性」や「誤りが後のターンに与える影響」が見えにくく、実務適性を判断しづらいという課題があります。さらに、複数ターンの編集では小さなミスが次の入力状態そのものを壊し、以後のターンで修復できない形で失敗が連鎖しやすい点も重要です。著者らは、従来の枠組みではこの種の失敗要因を切り分けにくいことを問題として捉え、会話を通じて「既存コードを壊さずに意図へ寄せる」能力を正面から測る必要があると位置づけています。加えて、評価方法にも難しさがあります。…
核心:何を提案したのか
著者らの提案は、「増分のチャート編集」を、マルチモーダル言語モデルに対する明確なベンチマーク課題として定式化し、そのためのデータと評価枠組みをセットで提示することです。ベンチマークであるChartEditBenchでは、初期状態としてチャートのコードと画像の組を与え、そこから段階的な変更を経て別の状態に遷移できるかを測ります。課題設定は大きく2種類に整理されています。1つは、元のコードと元画像に加えて「変更後の目標画像」を提示し、その見た目の差分を根拠にしてコードを修正させるものです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related