歴史的な低資源言語のレンマ化と品詞付与をLLMで進める試み:古代ギリシア語・古典アルメニア語・古ジョージア語・シリア語での少数例/ゼロ例評価
歴史的で注釈資源が乏しい4言語(古代ギリシア語・古典アルメニア語・古ジョージア語・シリア語)のレンマ化と品詞付与を、微調整なしの大規模言語モデルでもどこまで開始できるかを、同一条件のベースラインと並べて検証した研究です。
TL;DR(結論)
- 歴史的で注釈資源が乏しい4言語(古代ギリシア語・古典アルメニア語・古ジョージア語・シリア語)のレンマ化と品詞付与を、微調整なしの大規模言語モデルでもどこまで開始できるかを、同一条件のベースラインと並べて検証した研究です。
- 訓練用5,000語とドメイン外テスト300語からなる新しいベンチマークを用い、ゼロショットと少数例(5・50・500例)プロンプトで、GPT-4系およびオープンウェイトのMistral系を、タスク特化RNNのPIEと比較評価しています。
- 少数例設定では多くの言語でレンマ化・品詞付与とも競争力のある、またはより高い性能が示されましたが、非ラテン文字や複雑な形態、@による分割が多い条件では課題が残り、それでもデータ不在の注釈立ち上げに有力だと位置づけています。
なぜこの問題か
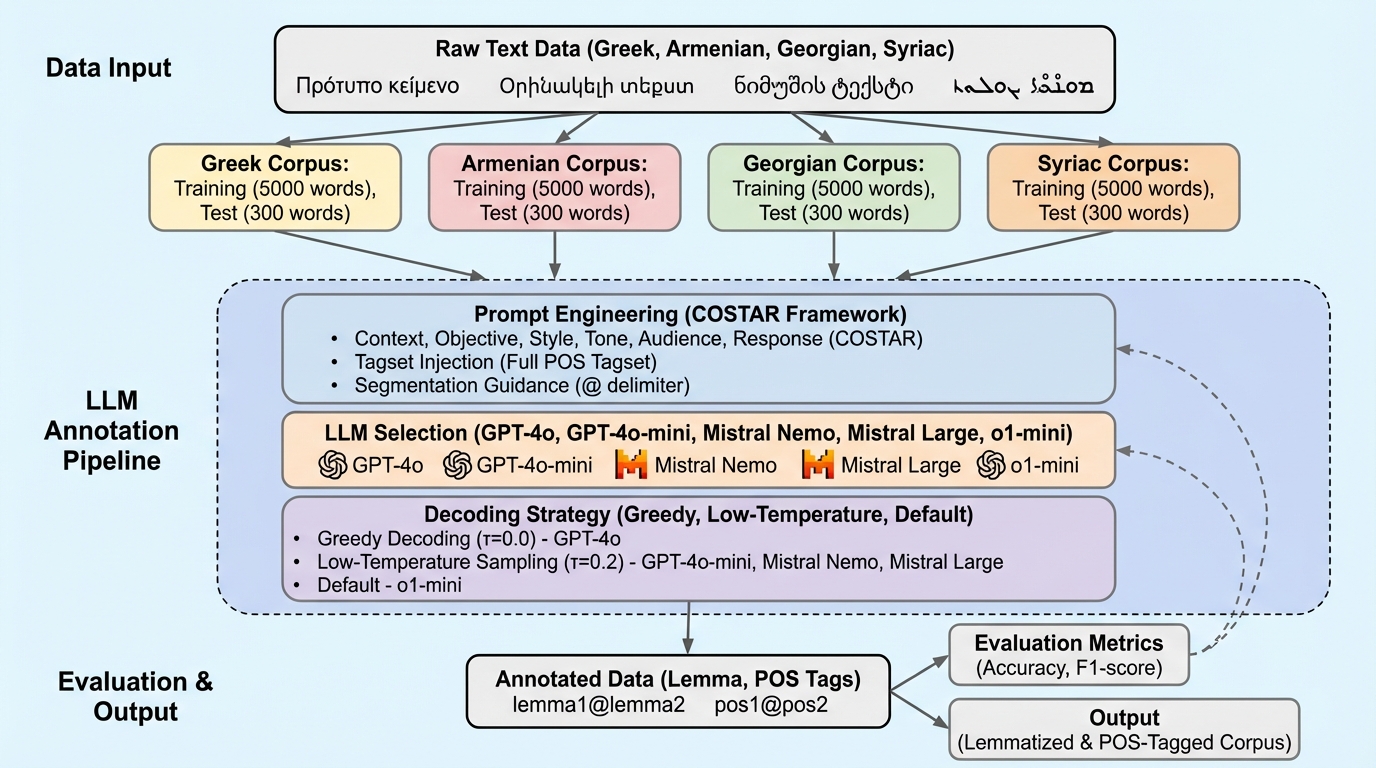
低資源言語では、自然言語処理の基礎タスクであるレンマ化と品詞(POS)付与に必要な注釈データが十分に集まりにくく、手法比較や再現可能な評価自体が難しくなりがちです。さらに歴史言語の場合、綴りや用法が時代・文献ジャンルで揺れやすく、現代語中心のモデルや一般的な注釈枠組みをそのまま当てはめにくい点が問題になります。本研究が扱う古代ギリシア語、古典アルメニア語、古ジョージア語、シリア語は、言語系統も形態体系も異なり、屈折が豊かな言語、膠着的要素が強い言語、テンプレート的な形態をもつ言語が並びます。データは西暦4世紀から15世紀にかけての文献で、禁欲、書簡、注解、聖人伝、史書、説教、教父文献、偽典、神学など多様な話題が含まれ、同一ドメインに閉じた評価では済まない構成です。 この状況で鍵になるのが、注釈の「コールドスタート」です。注釈付きデータがほぼない段階でも、何らかの方法で最初の注釈を起こせれば、その後に教師あり学習や反復的な修正が可能になります。近年、大規模言語モデルがゼロショットや少数例でも一定の適応力を示す報告があり、歴史言語の形態注釈にも転用できるかが論点になります。…
核心:何を提案したのか
本研究の提案は、歴史的・低資源の4言語について、最近の大規模言語モデルを「注釈者」として用い、レンマ化と品詞付与をゼロショットおよび少数例の設定で体系的に評価することです。対象モデルにはGPT-4系(本文ではGPT-4o、GPT-4o-mini、o1-miniが挙げられています)と、オープンウェイトのMistral系(Mistral Nemo、Mistral Largeなど)が含まれます。これらを、タスク特化のRNNベースラインであるPIEと比較し、歴史言語向けの従来型ニューラル注釈器と同じ土俵で性能を見ます。 評価にあたっては、各言語で「訓練コーパス5,000語」と「ドメイン外のテストコーパス300語」を整列させた新しいベンチマークを用意し、訓練内に閉じない一般化を確認できる設計にしています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related