大規模言語モデルにおける合成的推論のための再帰的概念進化
大規模言語モデルは多くの推論課題で強い一方、推論中に新しい抽象を組み立てる合成的推論では、内部表現空間が固定されていること自体がボトルネックになり、探索を増やしても精度が崩れやすいと位置づけられています。
TL;DR(結論)
- 大規模言語モデルは多くの推論課題で強い一方、推論中に新しい抽象を組み立てる合成的推論では、内部表現空間が固定されていること自体がボトルネックになり、探索を増やしても精度が崩れやすいと位置づけられています。
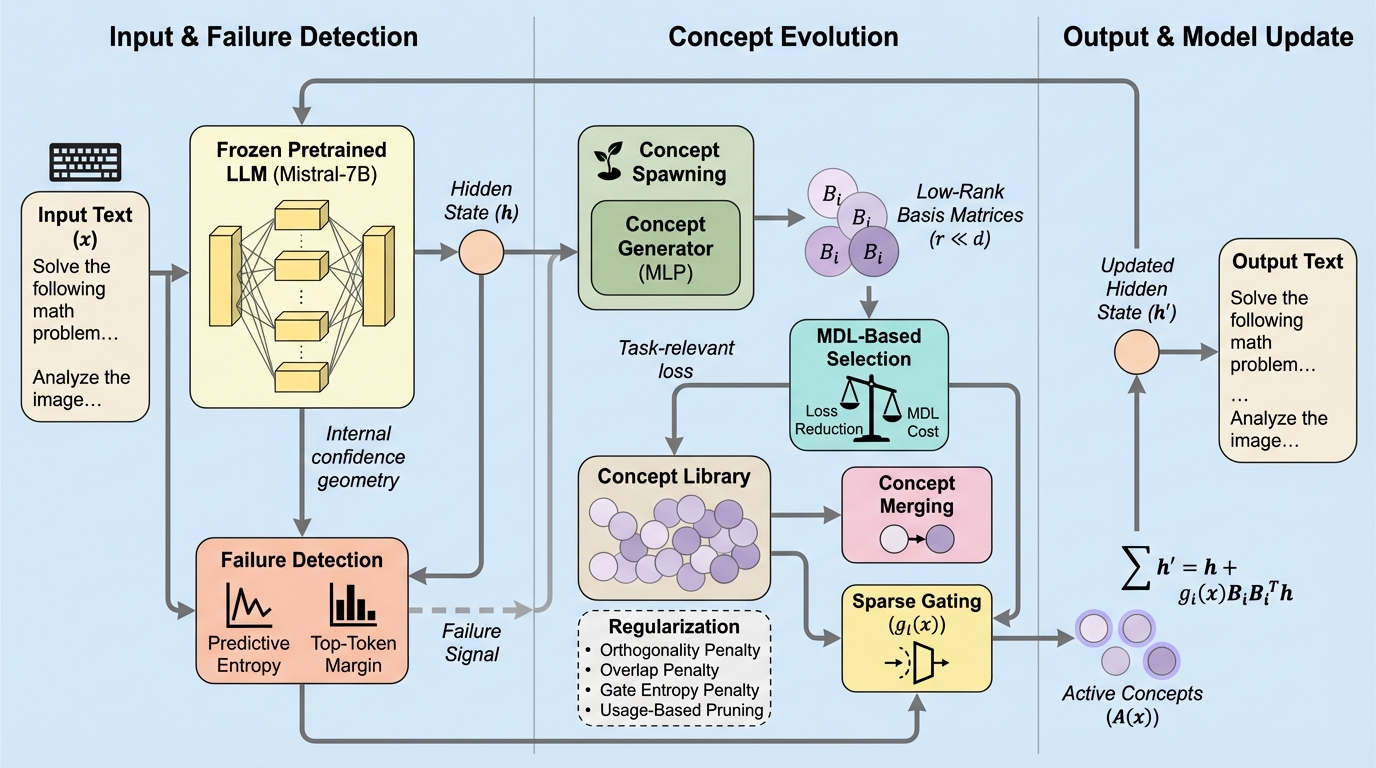
- Recursive Concept Evolution(RCE)は、凍結した事前学習済みモデルに対して推論時に低ランクの「概念部分空間」を動的に生成・選択・統合し、最小記述長の基準で増殖を抑えつつ、相乗効果のある概念はマージして階層化する枠組みです。
- Mistral-7Bへの統合評価ではARC-AGI-2で12〜18ポイント、GPQAとBBHで8〜14ポイントの改善が報告され、MATHとHLEでも推論の深さに伴う誤りが一貫して減ったとされ、表現の側を適応させる発想の有効性が示唆されています。
なぜこの問題か
大規模言語モデルは幅広い課題で高い性能を示す一方、ARC-AGI-2、GPQA、MATH、BBH、HLEのように「合成的推論」を要求するベンチマークでは精度が急激に落ちると述べられています。ここでいう合成的推論は、既に知っている知識断片を並べるだけでは足りず、推論の途中で新しい抽象や中間構造を作り、それを足場に次の推論へ進むことが必要になる状況を指しています。本文では例として、ARCのグリッド問題で隠れた対称性を見つける場合や、多段の論理推論で入れ子になった制約を追跡する場合が挙げられています。こうした場面では、必要な概念構造が事前学習済みの表現空間のどこにも埋め込まれていない可能性があります。するとモデルは、内部にある「近いパターン」への補間に頼り、見た目はもっともらしいのに構造的に誤った解答を出しやすいと説明されています。 従来は、連鎖的な推論のプロンプト、木探索、自己一致、強化学習などにより、トークン列としての探索を広げることで推論を改善してきました。しかし本文の主張では、これらは「探索の軌跡」を増やすだけで、推論が行われる内部表現の幾何は変わらない点が根本的な限界になります。…
核心:何を提案したのか
提案はRecursive Concept Evolution(RCE)であり、凍結した事前学習済み言語モデルが、推論時に自分の内部表現の幾何を作り替えられるようにする枠組みです。重要なのは、ベースモデルの重みそのものを更新するのではなく、あるデコーダ層の残差ストリームに「概念部分空間」を注入して、以降の層が受け取る中間表現を変形させる点です。RCEは概念ライブラリを維持し、各概念は低ランクの基底行列 (Bi \in \mathbb{R}^{d \times r})((r \ll d))と、入力ごとに活性度を決めるゲート関数 (gi(x)\in[0,1]) を持つとされています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related