LoRAの重み基底で視覚アナロジー空間を張る:LoRWeBによる例示ベース画像編集
言葉では説明しにくい編集でも、見本の「前→後」画像から変換を読み取り別画像へ移す視覚アナロジーは有用ですが、単一のLoRAに多様な変換を詰め込む設計は未知の変換への一般化を妨げやすいです。 / LoRWeBは、複数のLoRAを「変換の部品」として学習可能な基底にしておき、入力された三つ組(a, a′, b)を手がかりに軽量エンコーダが混合係数を推定して、推論時に1つのMixed LoRAとして動的に合成して注入します。 / 包括的な評価により最先端の性能が示され、学習時に見ていない視覚変換への一般化も大きく改善したと報告されており、LoRAを基底分解して混ぜる方針が柔軟な例示ベース編集に有望だと示唆されます。
TL;DR(結論)
- 言葉では説明しにくい編集でも、見本の「前→後」画像から変換を読み取り別画像へ移す視覚アナロジーは有用ですが、単一のLoRAに多様な変換を詰め込む設計は未知の変換への一般化を妨げやすいです。
- LoRWeBは、複数のLoRAを「変換の部品」として学習可能な基底にしておき、入力された三つ組(a, a′, b)を手がかりに軽量エンコーダが混合係数を推定して、推論時に1つのMixed LoRAとして動的に合成して注入します。
- 包括的な評価により最先端の性能が示され、学習時に見ていない視覚変換への一般化も大きく改善したと報告されており、LoRAを基底分解して混ぜる方針が柔軟な例示ベース編集に有望だと示唆されます。
なぜこの問題か
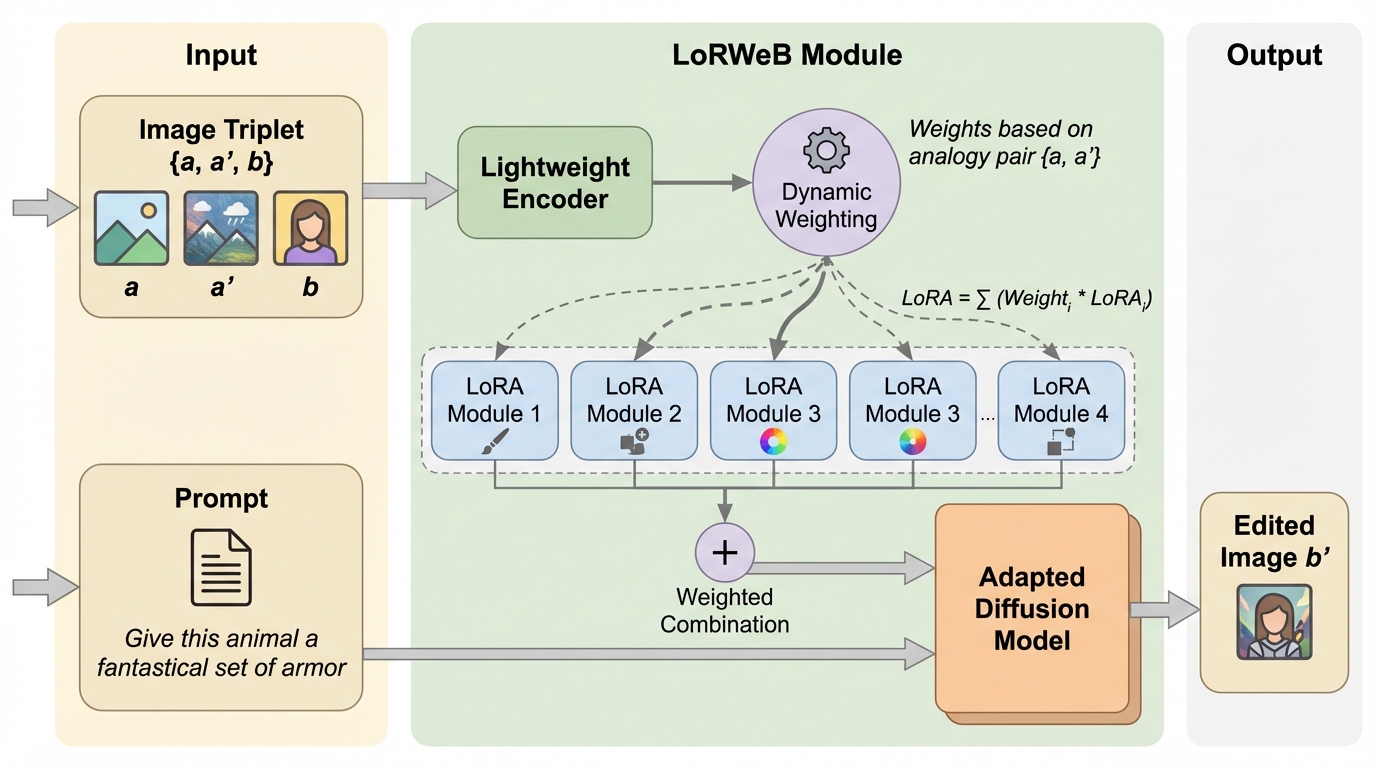
画像編集は、テキスト条件付き生成モデルの発展によって「言葉で指示して変える」方法が広がってきましたが、変換の内容によっては文章化そのものが難しいです。たとえば、写真をある作風へ変える、特定のポーズやメイクの雰囲気へ寄せる、背景や小物を自然に足す、といった操作は、文面が少し曖昧になるだけで解釈がぶれやすいです。そこで重要になるのが、言語ではなく例示で変換を伝える視覚アナロジー学習です。ここでは三つ組 {a, a′, b} が与えられ、aからa′への関係が b へも同様に成り立つように b′ を生成し、a:a′::b:b′ を満たすことを狙います。 近年は、強力なテキストから画像への基盤モデルを流用し、このタスクへLoRAで適応させる流れが提示されています。ただし、単一のLoRAアダプタに「スタイル変換、物体追加、配置変更」など幅広い視覚関係を押し込もうとすると、固定容量のボトルネックになり、訓練で見ていない変換への一般化が弱くなるという問題意識が示されています。…
核心:何を提案したのか
提案手法はLoRWeBで、視覚アナロジー編集を「1つのLoRAで全タスクを賄う」発想から、「複数のLoRAの線形結合としてタスクを表す」発想へ置き換えます。背景にある見立ては、制約された領域では複数のLoRAが意味のある空間を張り、LoRA同士の補間が新しい点として機能し得る、という近年の観察です。LoRWeBはこれを視覚アナロジーへ持ち込み、各アナロジータスクをLoRA空間上の一点として選ぶように、推論時に動的な合成を行います。 構成は大きく2要素です。第一に、多様な視覚変換をカバーするための「学習可能なLoRA基底」を複数本用意します。第二に、入力されたアナロジー三つ組(a, a′, b)に基づいて、どの基底をどれだけ混ぜるかを推定する軽量エンコーダを用意します。ここで重要なのは、基底LoRAを事後的に寄せ集めるのではなく、基底・混合・選択の仕組みを前提として同時に学習する点です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related