効率的な視覚と言語ナビゲーションのための、移動可能候補の取得を学習する
大規模言語モデルをナビゲータとして用いる視覚と言語ナビゲーションでは、毎回の指示解釈を最初からやり直し、各ステップで冗長な移動候補すべてを読み比べる必要があるため、意思決定が非効率かつ不安定になりやすいと整理されています。
TL;DR(結論)
- 大規模言語モデルをナビゲータとして用いる視覚と言語ナビゲーションでは、毎回の指示解釈を最初からやり直し、各ステップで冗長な移動候補すべてを読み比べる必要があるため、意思決定が非効率かつ不安定になりやすいと整理されています。
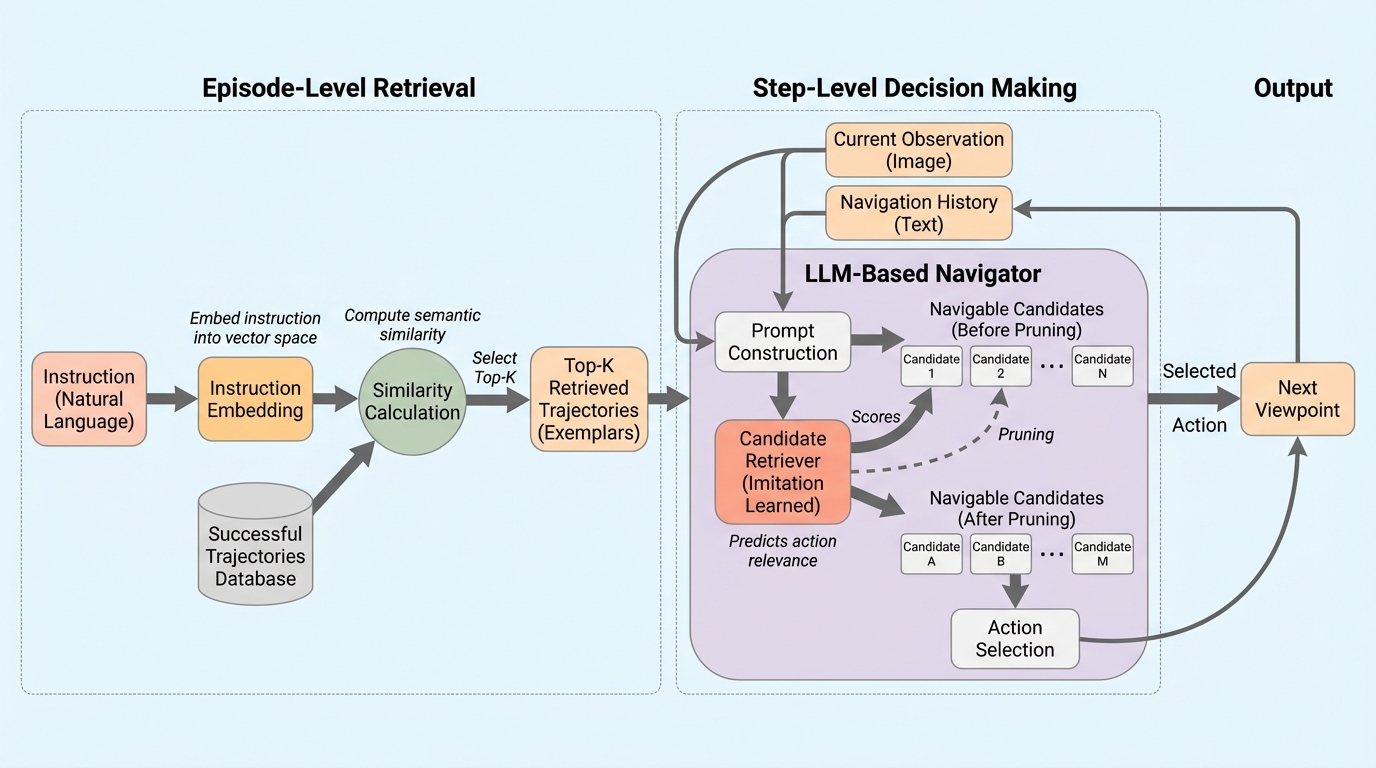
- 言語モデル本体は改変や追加学習をせず、エピソード開始時に「似た指示で成功した軌跡」を例示として検索してプロンプトに追加し、移動中は模倣学習した検索器で無関係な方向候補を事前に刈り込む二段階の検索拡張が提案されています。
- Room-to-Room(R2R)の見慣れた環境と未知環境の両方でSuccess Rate、Oracle Success Rate、SPLが一貫して改善し、例示検索は大域的な手がかり、候補刈り込みはステップごとの判断効率として補完的に効くことがアブレーションで示されています。
なぜこの問題か
Vision-and-Language Navigation(VLN)は、自然言語の指示に従って、これまで見たことのない環境内を移動する課題です。エージェントは視覚観測と言語を結び付け、長い手順の中で逐次的に行動を選ぶ必要があります。近年は大規模言語モデル(LLM)を高レベルのナビゲータとして使い、観測や履歴、移動可能な候補行動をテキスト化してプロンプトに入れ、推論と行動選択を言語として出力する枠組みが広がっています。こうした方式は、指示の文脈を長い範囲で保持しやすく、推論過程を自然言語のトレースとして残せる点が利点です。 一方で本文抜粋では、LLMをプロンプト駆動で動かすVLNの中心的な難しさが、視覚認識そのものよりも「情報量が多く複雑なプロンプトの下で、安定して意思決定すること」に移っていると述べられています。具体的なギャップは二つあります。第一に、各エピソードの冒頭で、LLMが指示を毎回ゼロから解釈し、戦略を推測し直す点です。過去に似た指示や成功パターンが存在しても、それを明示的に再利用する仕組みがないため、推論負荷が不必要に増えるとされています。…
核心:何を提案したのか
本研究は、LLMベースのVLNを「検索で補助する」検索拡張の枠組みを提案しています。重要なのは、基盤となる言語モデルを改変したり、ファインチューニングしたりしない方針を明確にしている点です。その代わりに、意思決定の前後を支える軽量な検索モジュールを追加し、LLMが読む情報をタスクに即して整えることで、効率と安定性を改善する狙いです。 提案の中心は、相補的な二つの検索を導入することです。第一はエピソードレベルの検索で、現在の指示と意味的に近い「成功したナビゲーション軌跡」を選び、in-contextの例示としてプロンプトに含めます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related