GDCNet: マルチモーダル皮肉検出のための生成的差異比較ネットワーク
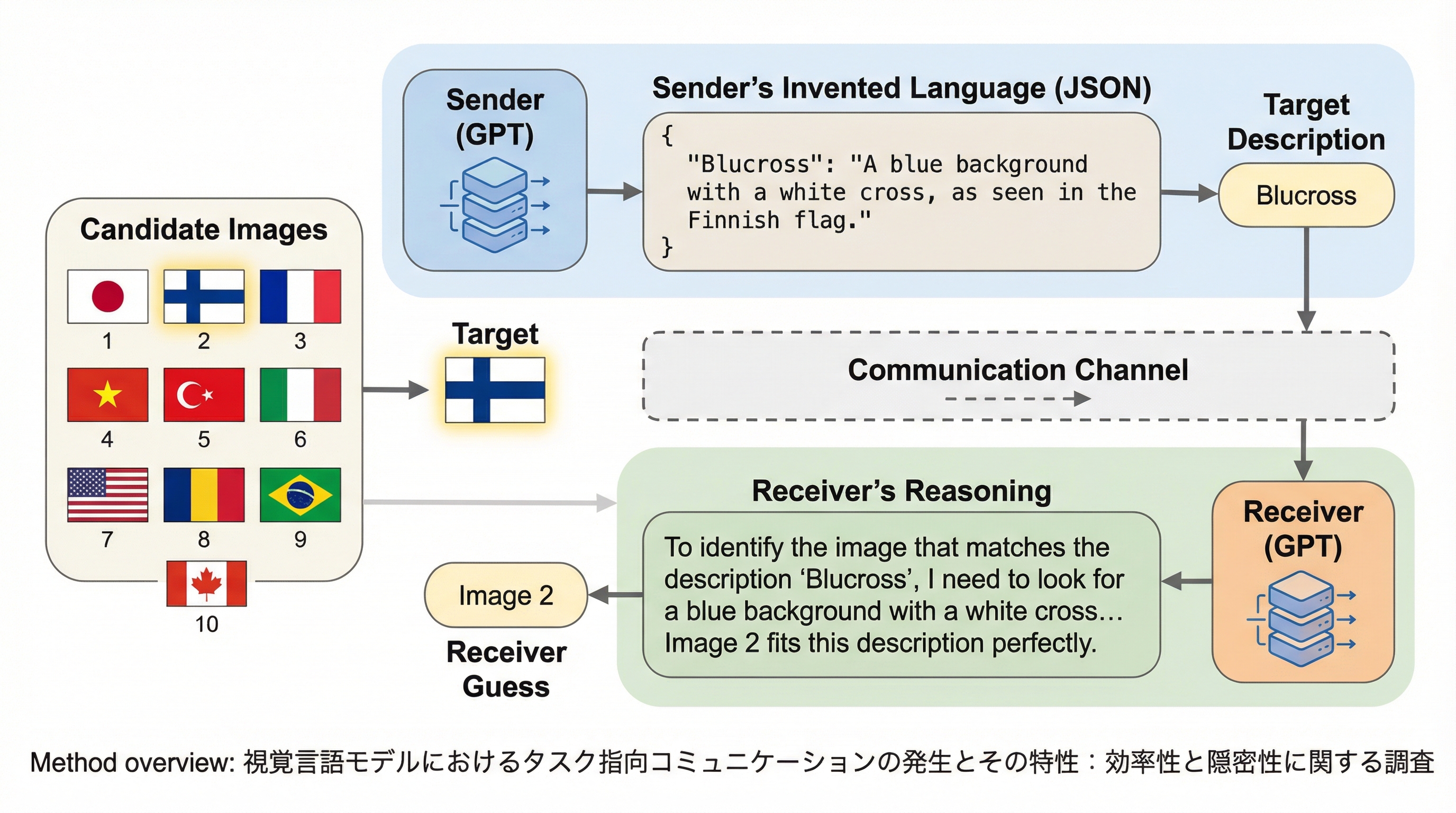
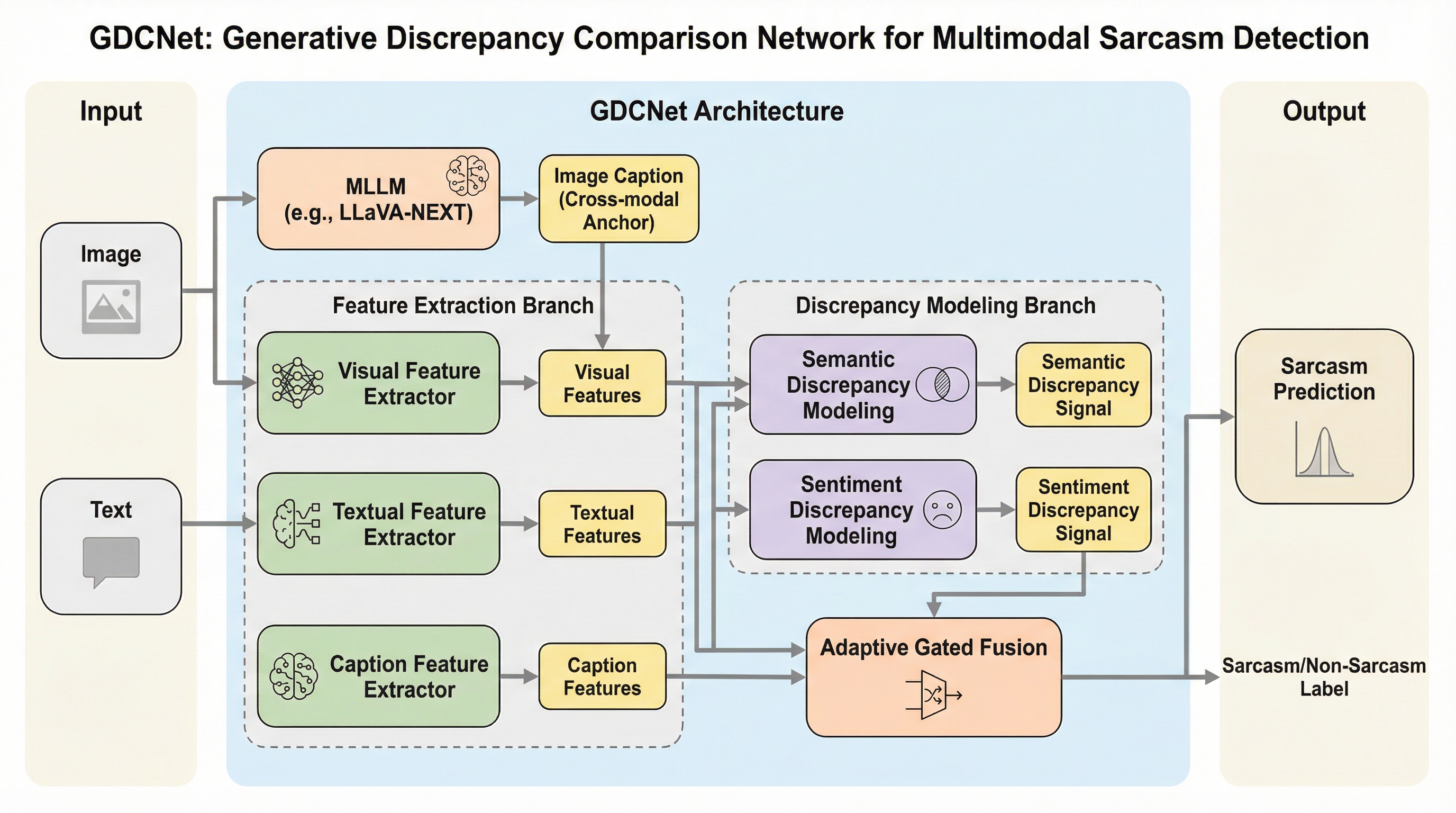
GDCNetは、画像とテキストのペアから皮肉を検出するために、マルチモーダル大規模言語モデル(MLLM)を「客観的な画像説明の生成器」として活用する新しいフレームワークである。従来のモデルがLLMに主観的な皮肉の理由を生成させていたのに対し、本手法は画像に基づいた事実的なキャプションを生成し、それを安定したセマンティック・アンカー(意味の指標)として活用することで、解釈の多様性によるノイズを抑制している。 このネットワークは、生成された客観的な画像説明と元のテキストとの間にある意味的な不一致、感情的な不一致、および画像とテキストの忠実度を測定する「生成的差異表現モジュール(GDRM)」を備えている。これにより、画像とテキストの間の微妙な矛盾や、文字通りの意味と意図された意味の乖離を、多角的な差異特徴として抽出することが可能になり、皮肉特有の複雑な不一致を捉えることができる。 大規模なベンチマークであるMMSD2.0を用いた実験において、GDCNetは既存のマルチモーダル手法や、GPT-4oなどの最新モデルを用いた直接的な推論手法を大幅に上回る最高精度を達成した。適応的なゲート付き融合メカニズムを導入することで、画像、テキスト、および差異情報の各モダリティの寄与を動的にバランスさせ、特定の情報の偏りを防ぎながら、頑健な皮肉検出を実現している。