知覚と較正の分離:ラベル効率の高い画像品質評価フレームワーク
多峰性大規模言語モデル(MLLM)は画像品質評価(IQA)において優れた知覚能力を持つものの、膨大な計算コストと大量の人間による評価ラベル(MOS)への依存が実用上の大きな障壁となっている。 本研究が提案する「LEAF」は、MLLMの知覚能力と特定の評価尺度への校正を分離し、強力な教師モデルから軽量な学生モデルへ知覚知識を蒸留することで、極めて少数のラベルのみで高精度な予測を実現する。 検証の結果、わずか10%のラベルを用いた校正だけで、AI生成画像等のベンチマークにおいて従来のフルデータ学習に匹敵する性能を達成し、デバイス上での動作や大規模データの高速処理を可能にする道を示した。
TL;DR(結論)
多峰性大規模言語モデル(MLLM)は画像品質評価(IQA)において優れた知覚能力を持つものの、膨大な計算コストと大量の人間による評価ラベル(MOS)への依存が実用上の大きな障壁となっている。 本研究が提案する「LEAF」は、MLLMの知覚能力と特定の評価尺度への校正を分離し、強力な教師モデルから軽量な学生モデルへ知覚知識を蒸留することで、極めて少数のラベルのみで高精度な予測を実現する。 検証の結果、わずか10%のラベルを用いた校正だけで、AI生成画像等のベンチマークにおいて従来のフルデータ学習に匹敵する性能を達成し、デバイス上での動作や大規模データの高速処理を可能にする道を示した。
なぜこの問題か
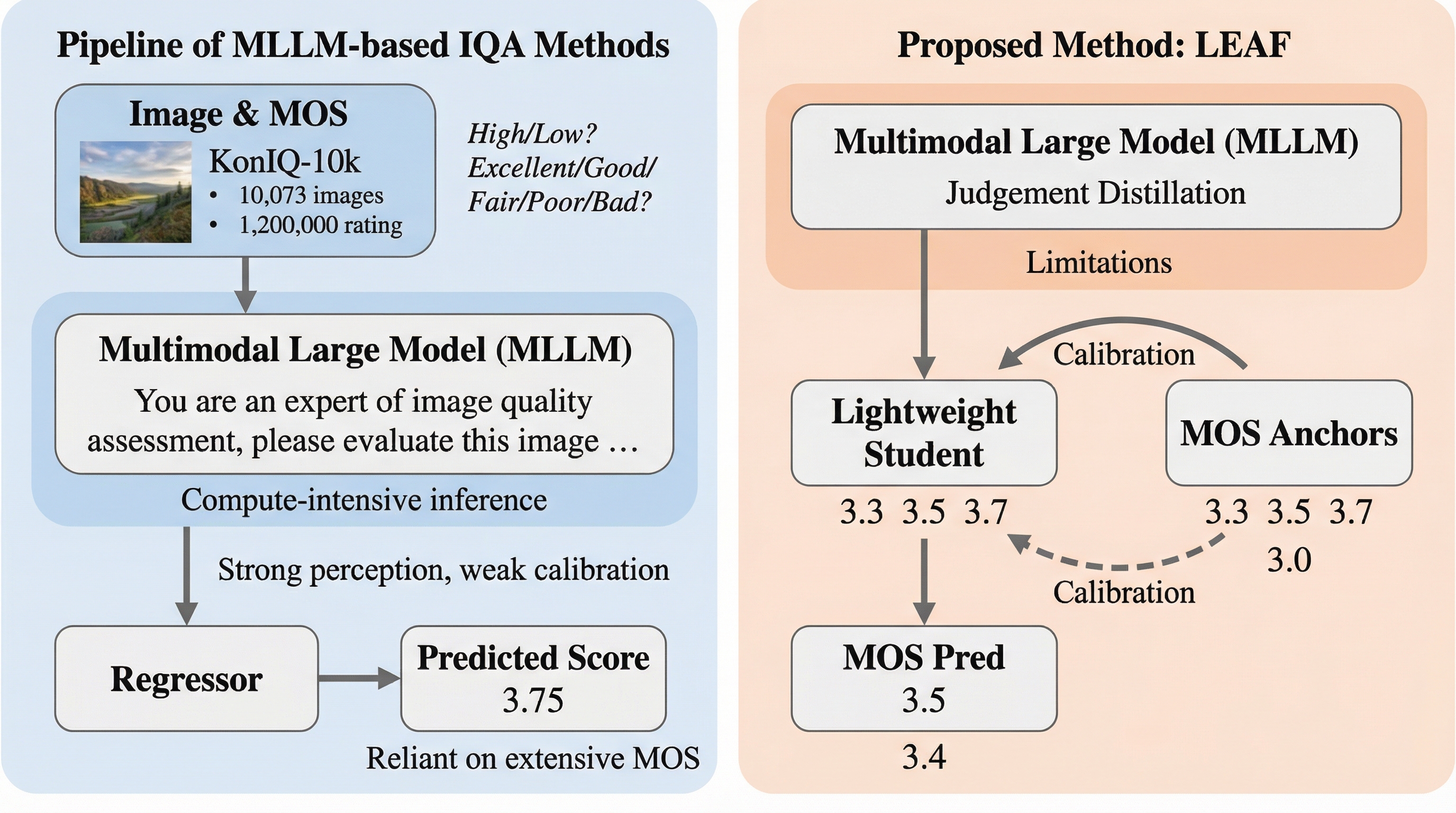
画像品質評価(IQA)は、現代の視覚システムにおいて不可欠な基盤技術であり、カメラの校正、画像鮮明化、コンテンツフィルタリング、ストリーミングメディアの最適化、そして大規模なデータ管理に至るまで、極めて広範なアプリケーションを支えている。特に近年、画像生成モデルや画像修復技術が飛躍的に発展したことで、人間の主観的な基準に合致したフィードバックを提供できる高品質な評価モデルの需要はかつてないほど高まっている。最新の多峰性大規模言語モデル(MLLM)は、その強力な視覚理解能力と豊富な事前知識を活用することで、専門的なIQAモデルに匹敵する優れた性能を示している。しかし、これらを実用化するにあたっては、二つの深刻な障壁が立ちはだかっている。 第一に、MLLMは学習および推論の両面で計算資源の消費が極めて激しく、大規模なデータのフィルタリングやモバイルデバイス上でのリアルタイム監視といった、高速かつ低コストな処理が求められる現場での導入が困難である。第二に、現在の主要なIQA手法は、人間による平均意見スコア(MOS)を用いた教師あり学習に強く依存しているが、このMOSの収集には膨大なコストと時間がかかる。…
核心:何を提案したのか
本研究では、知覚知識の獲得と数値尺度の校正を分離するという基本原則に基づき、ラベル効率の高い画像品質評価フレームワークである「LEAF(Label-Efficient Image Quality Assessment Framework)」を提案した。このフレームワークの最大の特徴は、強力な知覚能力を持つMLLMを「教師」として活用し、ラベルのない膨大な画像セットに対して密な教師信号を生成させ、その知覚パターンを「軽量な学生モデル」に継承させる点にある。これにより、MLLMの持つ高度な視覚的洞察力を、計算負荷の低い小さなモデルへと効率的に転移させることが可能になった。 具体的には、教師モデルであるMLLMから二種類の相補的な知覚情報を抽出する。一つは個々の画像に対する「点単位の品質判断」であり、もう一つは画像ペア間の相対的な優劣を示す「対比較の嗜好性」である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related