GDCNet: マルチモーダル皮肉検出のための生成的差異比較ネットワーク
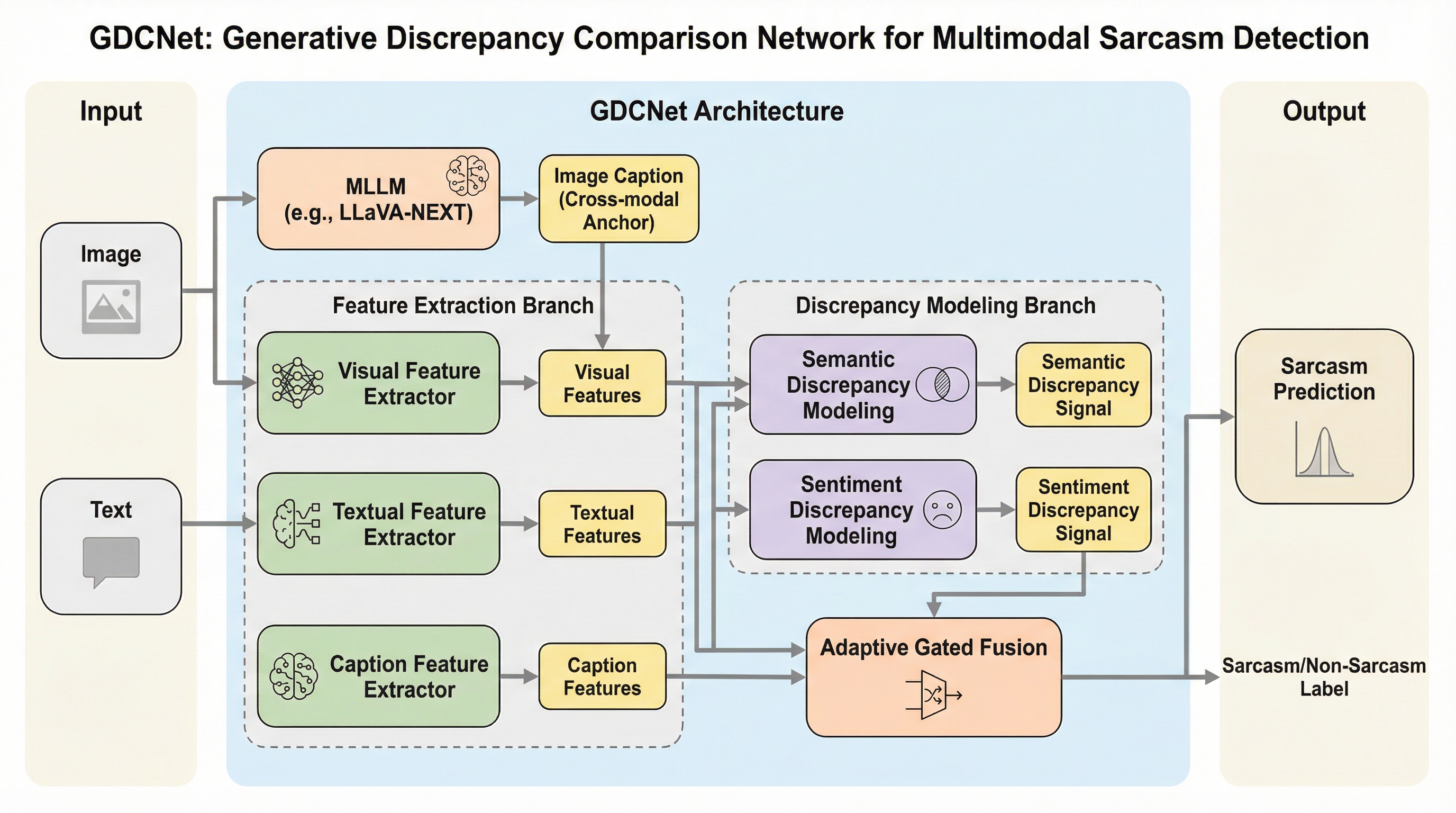
GDCNetは、画像とテキストのペアから皮肉を検出するために、マルチモーダル大規模言語モデル(MLLM)を「客観的な画像説明の生成器」として活用する新しいフレームワークである。従来のモデルがLLMに主観的な皮肉の理由を生成させていたのに対し、本手法は画像に基づいた事実的なキャプションを生成し、それを安定したセマンティック・アンカー(意味の指標)として活用することで、解釈の多様性によるノイズを抑制している。 このネットワークは、生成された客観的な画像説明と元のテキストとの間にある意味的な不一致、感情的な不一致、および画像とテキストの忠実度を測定する「生成的差異表現モジュール(GDRM)」を備えている。これにより、画像とテキストの間の微妙な矛盾や、文字通りの意味と意図された意味の乖離を、多角的な差異特徴として抽出することが可能になり、皮肉特有の複雑な不一致を捉えることができる。 大規模なベンチマークであるMMSD2.0を用いた実験において、GDCNetは既存のマルチモーダル手法や、GPT-4oなどの最新モデルを用いた直接的な推論手法を大幅に上回る最高精度を達成した。適応的なゲート付き融合メカニズムを導入することで、画像、テキスト、および差異情報の各モダリティの寄与を動的にバランスさせ、特定の情報の偏りを防ぎながら、頑健な皮肉検出を実現している。
TL;DR(結論)
GDCNetは、画像とテキストのペアから皮肉を検出するために、マルチモーダル大規模言語モデル(MLLM)を「客観的な画像説明の生成器」として活用する新しいフレームワークである。従来のモデルがLLMに主観的な皮肉の理由を生成させていたのに対し、本手法は画像に基づいた事実的なキャプションを生成し、それを安定したセマンティック・アンカー(意味の指標)として活用することで、解釈の多様性によるノイズを抑制している。 このネットワークは、生成された客観的な画像説明と元のテキストとの間にある意味的な不一致、感情的な不一致、および画像とテキストの忠実度を測定する「生成的差異表現モジュール(GDRM)」を備えている。これにより、画像とテキストの間の微妙な矛盾や、文字通りの意味と意図された意味の乖離を、多角的な差異特徴として抽出することが可能になり、皮肉特有の複雑な不一致を捉えることができる。 大規模なベンチマークであるMMSD2.0を用いた実験において、GDCNetは既存のマルチモーダル手法や、GPT-4oなどの最新モデルを用いた直接的な推論手法を大幅に上回る最高精度を達成した。適応的なゲート付き融合メカニズムを導入することで、画像、テキスト、および差異情報の各モダリティの寄与を動的にバランスさせ、特定の情報の偏りを防ぎながら、頑健な皮肉検出を実現している。
なぜこの問題か
皮肉は、発言の表面的な意味が話し手の意図するメッセージから大きく逸脱する言語現象であり、ユーモアや批判、微妙な社会的論評のための強力なツールとして日常的に使われている。近年、ソーシャルメディアにおけるマルチモーダルなコンテンツの急増に伴い、画像とテキストの両方を考慮したマルチモーダル皮肉検出(MSD)の重要性が高まっている。しかし、テキストのみの検出からマルチモーダルな文脈への移行は、タスクの難易度を著しく高める。なぜなら、皮肉は画像とテキストの相互作用によって生じ、どちらか一方のモダリティを単独で見るだけでは理解できない意味を生成することが多いためである。 MSDの本質は、画像とテキストの間の「不一致」を特定することにある。これまでの研究では、アテンションメカニズムやグラフニューラルネットワーク、外部知識の活用、動的ルーティングなどの技術を用いて、マルチモーダルな表現を整列させることでこの課題に取り組んできた。しかし、既存の手法は依然として分布外の汎化性能に課題があり、表面的な手がかりに依存しすぎる傾向がある。…
核心:何を提案したのか
本研究では、MLLMを「主観的な皮肉の生成器」としてではなく、「客観的なクロスモーダル・セマンティック・コネクタ」として利用することを提案している。この着想に基づき開発されたのが、生成的差異比較ネットワーク(GDCNet)である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related