Li-ViP3D++: クエリベースの変形可能フュージョンによるエンドツーエンドの認識と軌跡予測
Li-ViP3D++は、自動運転における物体認識と軌跡予測を統合するエンドツーエンドのフレームワークであり、カメラとLiDARの情報をクエリ空間で融合するQuery-Gated Deformable Fusion(QGDF)を導入しています。
TL;DR(結論)
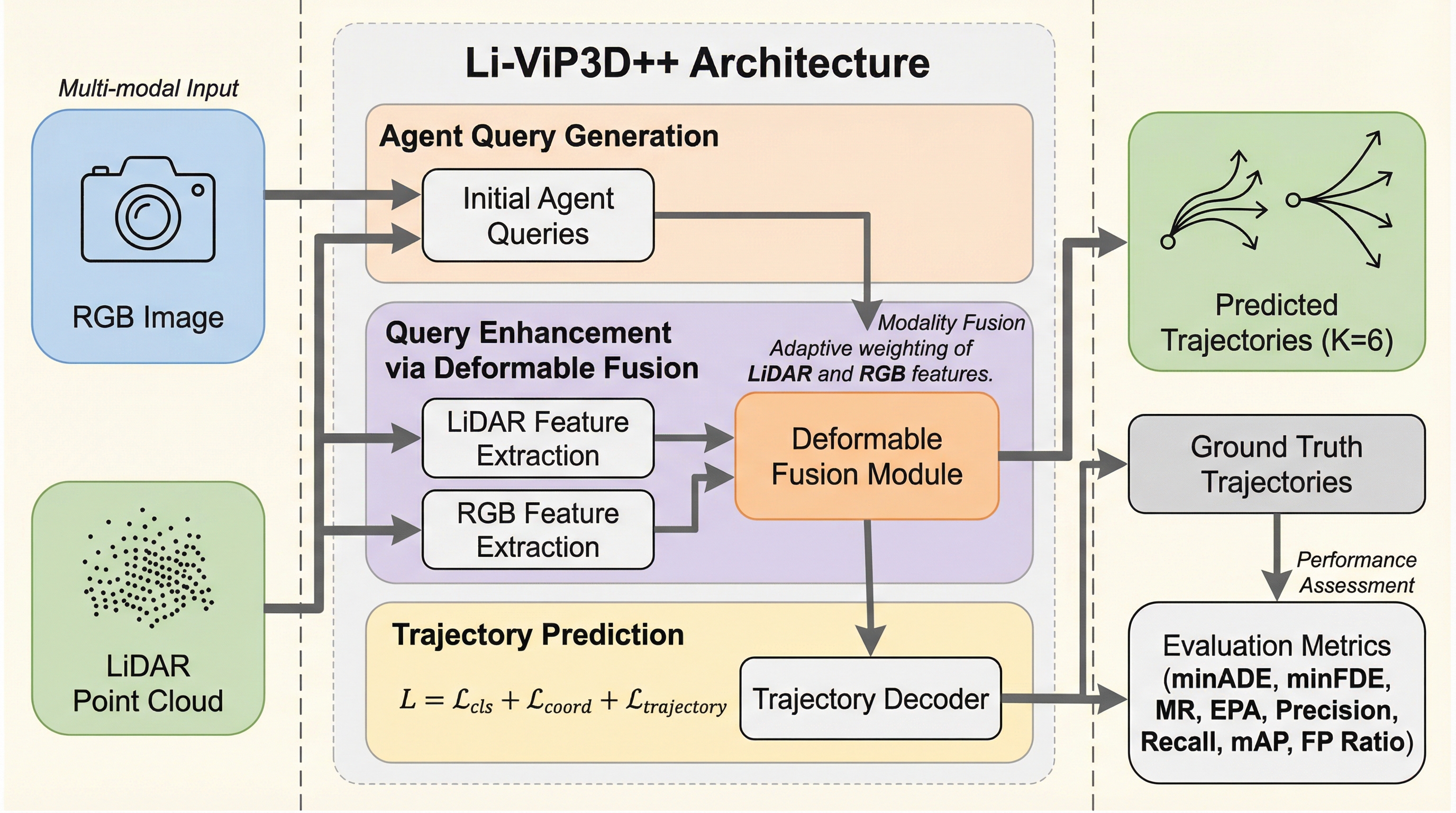
Li-ViP3D++は、自動運転における物体認識と軌跡予測を統合するエンドツーエンドのフレームワークであり、カメラとLiDARの情報をクエリ空間で融合するQuery-Gated Deformable Fusion(QGDF)を導入しています。 この手法は、複数のカメラ画像からの特徴抽出とLiDARのBEV空間でのサンプリングを微分可能な形で組み合わせ、エージェントごとに視覚情報と幾何情報の重みを動的に調整することで、情報の欠落や誤差の増幅を防ぎます。 nuScenesデータセットを用いた評価では、従来手法と比較してEPA(0.335)やmAP(0.502)が向上し、誤検出率(0.147)の大幅な低減と処理速度の改善(139.82ms)を同時に達成しており、実用性と精度の両立が示されています。
なぜこの問題か
自動運転システムにおいて、周囲のエージェントの現在位置を正確に把握し、将来の行動を予測することは、安全な走行と円滑な交通流の維持に不可欠な機能です。従来のシステムは、物体検出、物体追跡、軌跡予測といった各機能を個別のモジュールとして構築するパイプラインを採用することが一般的でしたが、この構造には情報の流れが制限されるという大きな課題があります。具体的には、上流のモジュールで発生した小さな誤差が下流へと伝播し、最終的な予測精度を著しく低下させるリスクが存在します。また、カメラのみ、あるいはLiDARのみといった単一のモダリティに依存する手法は、それぞれのセンサーが持つ固有の限界に直面しやすく、複雑な交通環境や多様な物体タイプへの対応が困難になることがあります。 例えば、LiDARは幾何学的な位置精度に優れますが、計算効率やコストに課題があり、一方でカメラは安価で視覚情報が豊富ですが、距離推定の不確実性が高いという特性があります。…
核心:何を提案したのか
本研究では、カメラとLiDARのデータをクエリ空間で統合する新しいエンドツーエンドのフレームワークであるLi-ViP3D++を提案しています。このモデルの核心となるのは、Query-Gated Deformable Fusion(QGDF)と呼ばれる革新的なモジュールであり、これによりマルチビューRGB画像とLiDARの情報を効率的かつ効果的に融合することが可能になりました。QGDFは、各エージェントに対応するクエリを用いて、複数のカメラ視点や異なる特徴レベルから視覚的な証拠を集約し、同時にLiDARのBEV(鳥瞰図)特徴から幾何学的なコンテキストを抽出します。 この際、クエリごとに学習されたオフセットを用いてサンプリングを行うことで、情報の位置合わせを柔軟に行うことができます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related