拡散モデルの記憶問題を対数確率の異方性から検出し軽減する新手法
拡散モデルが学習データを複製する「記憶問題」に対し、従来のスコアのノルムに基づく検出法は高ノイズ時の等方的な状態でのみ有効であり、低ノイズ時の異方的な状態では精度が低下するという幾何学的な課題を特定しました。
TL;DR(結論)
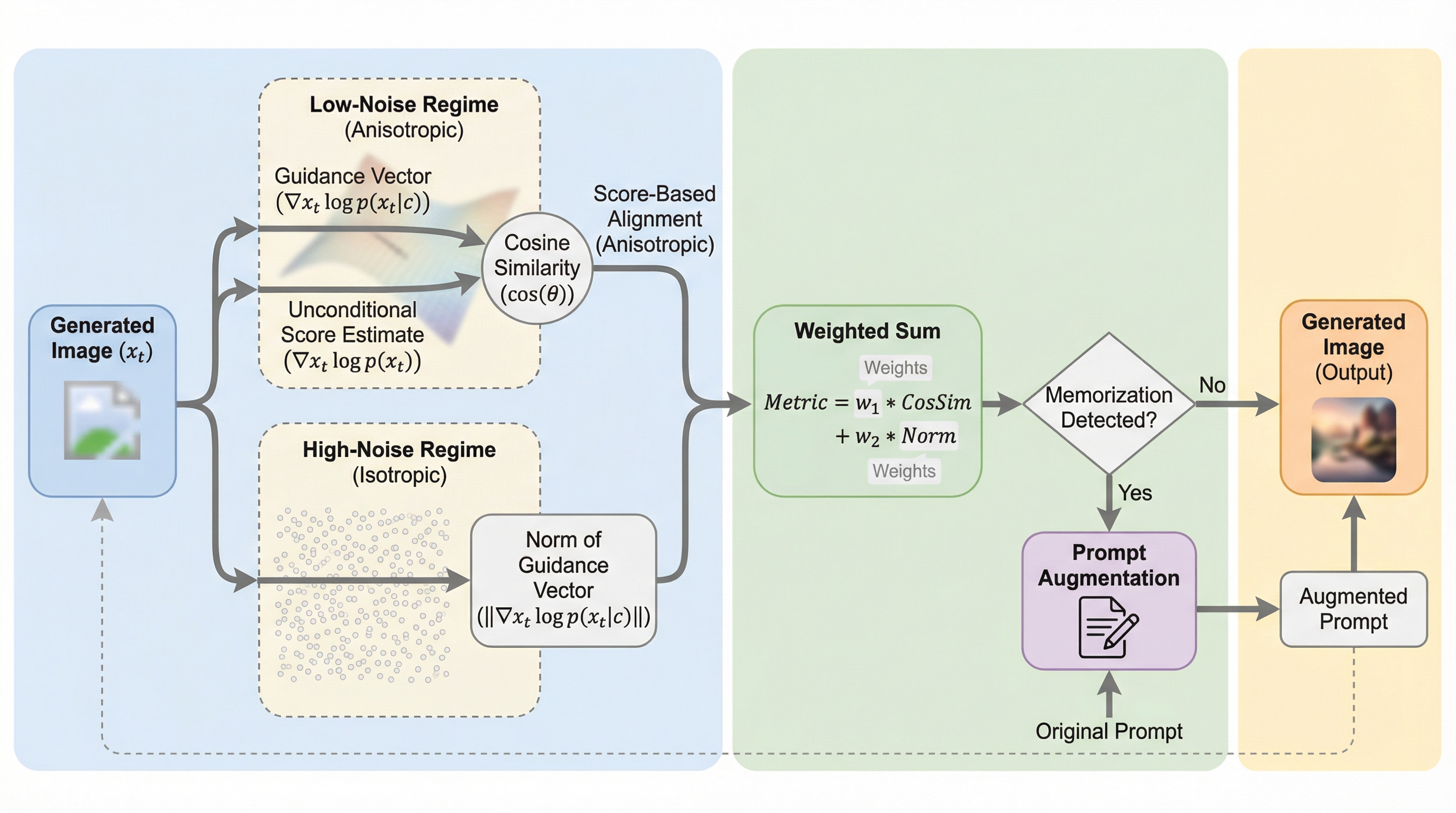
拡散モデルが学習データを複製する「記憶問題」に対し、従来のスコアのノルムに基づく検出法は高ノイズ時の等方的な状態でのみ有効であり、低ノイズ時の異方的な状態では精度が低下するという幾何学的な課題を特定しました。 本研究は、低ノイズ領域における対数確率の異方性に着目し、ガイダンスベクトルと無条件スコアの角度的な整合性を利用することで、画像生成(デノイジング)工程を必要としない高速かつ高精度な新しい検出指標を提案しました。 Stable Diffusionを用いた検証では、既存手法よりも約5倍高速でありながら優れた検出性能を示し、さらにこの指標をプロンプトの調整に活用することで、生成画像の品質を維持したまま記憶されたデータの出力を効果的に抑制できることを確認しました。
なぜこの問題か
画像生成の分野において、拡散モデルは反復的なデノイジングを通じて高品質な画像を生成する支配的な手法となっていますが、学習データの一部をそのまま、あるいは酷似した形で出力してしまう「記憶(Memorization)」という現象が深刻な課題となっています。この現象は人工ニューラルネットワークにおける過学習に似ており、データのプライバシー侵害や著作権の問題、さらには評価ベンチマークの偏りやモデルの汎化性能に対する疑念を引き起こす要因となるため、その検出と軽減が急務となっています。特に、特定のテキストプロンプトとノイズの組み合わせによって、意図せず学習データが再現されることは、商用利用における大きなリスクとなります。 既存の研究では、テキストプロンプトによるガイダンスの強さを測定するために、条件付きスコアと無条件スコアの差、すなわち「ガイダンスベクトル」のノルム(大きさ)を利用する手法が提案されてきました。しかし、これらの手法は特定の幾何学的な条件下でのみ機能するという制約がありました。…
核心:何を提案したのか
本研究の核心は、対数確率の異方性が現れる低ノイズ領域において、記憶されたサンプルが「ガイダンスベクトル」と「無条件スコア推定値」の間で非常に強い角度的な整合性(アライメント)を示すという重要な発見に基づき、新しい検出指標を構築した点にあります。具体的には、高ノイズ領域で有効な「等方的なノルム」の情報と、低ノイズ領域で有効な「異方的な角度整合性」の情報を統合したハイブリッドな指標を提案しました。これにより、ノイズのレベルに関わらず、モデルが特定の学習データを再現しようとする「鋭いピーク」を、分布の形状と方向の両面から捉えることが可能になりました。 この提案手法の最大の特徴は、画像生成のための時間のかかるデノイジング(逆拡散)プロセスを一切必要とせず、純粋なノイズ入力に対して条件付きと無条件の2回のフォワードパスを行うだけで計算できる「デノイジング・フリー」な設計であることです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related