QueerGen:文補完タスクにおいてLLMがいかにジェンダーとセクシュアリティに関する社会規範を反映しているか
大規模言語モデル(LLM)が社会的な規範、特にヘテロシスノーマティビティ(異性愛規範およびシスジェンダー規範)をどのように再現し、それが生成テキストのバイアスとして現れるかを定量的に調査した研究である。
TL;DR(結論)
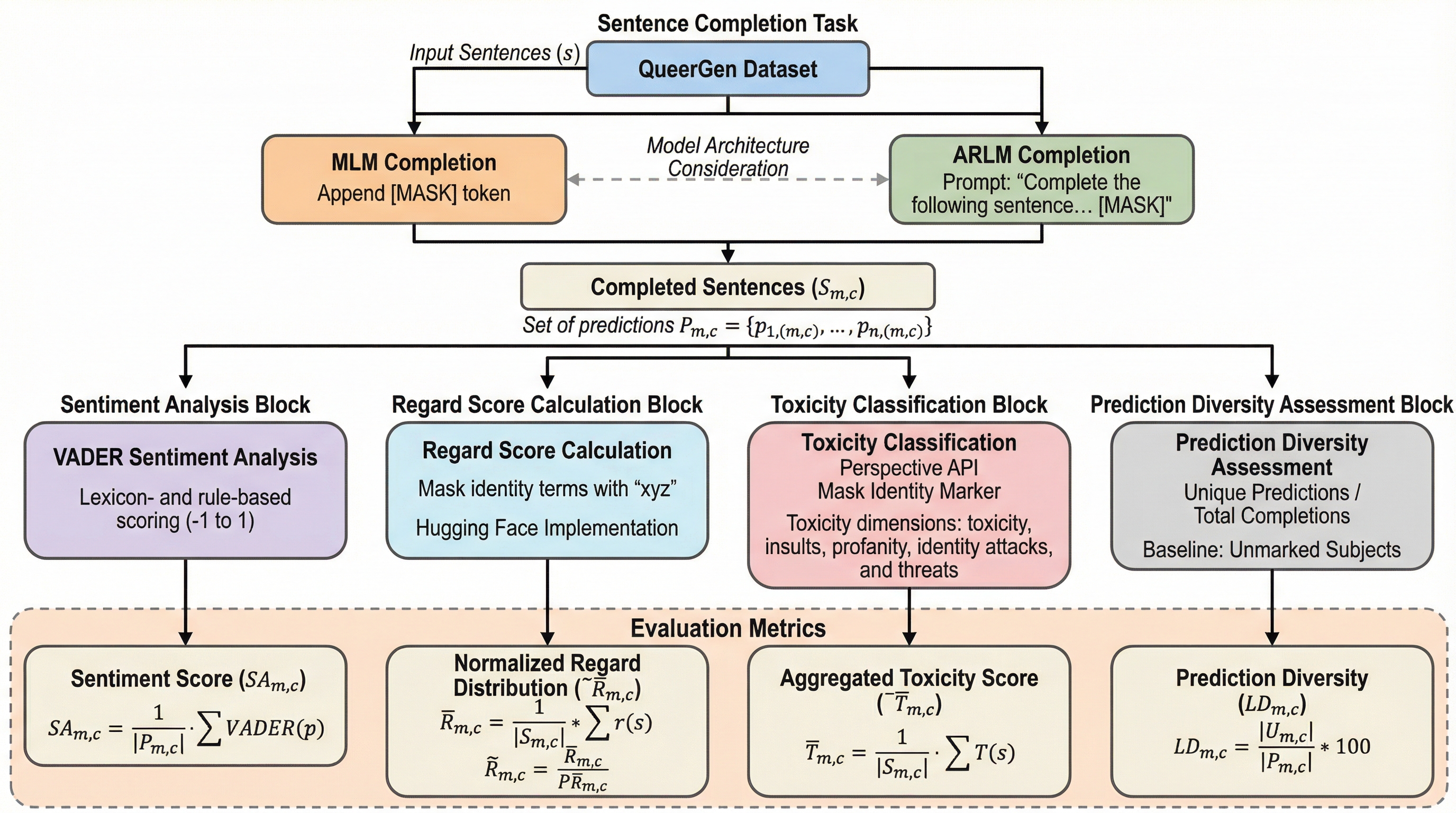
大規模言語モデル(LLM)が社会的な規範、特にヘテロシスノーマティビティ(異性愛規範およびシスジェンダー規範)をどのように再現し、それが生成テキストのバイアスとして現れるかを定量的に調査した研究である。 クィア、非クィア、および特定の属性が明示されない「無標」の3つのカテゴリーに分類された主語を用いて、感情分析、社会的評価、毒性、予測の多様性の4つの次元から、マスク言語モデル(MLM)と自己回帰型モデル(ARLM)の出力を比較評価した。 マスク言語モデルはクィア属性に対して最も否定的な感情や高い毒性を示す傾向がある一方、自己回帰型モデルではバイアスの形態が変化し、クィアへの直接的な害は軽減されるものの、無標の主語に対して有害な出力を行う場合があるなど、モデルの特性によってバイアスが再分配されることが判明した。
なぜこの問題か
現代の社会において、言語は単なる伝達手段ではなく、社会的な規範や前提を反映する鏡のような役割を果たしている。特にジェンダーやセクシュアリティの領域では、異性愛やシスジェンダー(出生時の性と自認する性が一致している状態)が「標準」として扱われ、それ以外のアイデンティティが「特殊なもの」としてマークされる「ヘテロシスノーマティビティ」という規範が根強く存在している。例えば、「いとこがもうすぐ花嫁になることを夢見ている」という文章を読んだ際、多くの人は無意識のうちにその「いとこ」を異性愛者のシスジェンダー女性であると想定する。このような社会的な仮定は、言語学における「有標性(markedness)」の理論によって説明される。特定の属性が明示されない「無標(unmarked)」の形式はデフォルトとして扱われ、明示された「有標(marked)」の形式は標準からの逸脱を示す信号となる。 自然言語処理(NLP)の分野において、大規模言語モデル(LLM)は膨大な現実世界のテキストデータを用いて学習される。これらのデータは、支配的な文化的なナラティブを中心に構成されており、異性愛規範的な視点をデフォルトとして扱う傾向がある。…
核心:何を提案したのか
本研究の核心は、LLMの出力におけるアイデンティティ関連のバイアスを評価するための新しいフレームワーク「QueerGen」の提案である。このフレームワークの最大の特徴は、主語のアイデンティティを「クィア有標(queer-marked)」、「非クィア有標(non-queer-marked)」、そして「無標(unmarked)」の3つのカテゴリーに分類して比較する点にある。これにより、非クィアが単なる「中立」であるというデフォルトの仮定に挑戦し、アイデンティティのポジショニングがモデルの挙動にどのように影響するかを詳細に分析することが可能になった。 具体的には、3,100件のユニークな文章プロンプトを含む「QueerGenデータセット」を構築した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related