変化する行動空間と報酬関数に対する強化学習エージェントの行動の適応
本研究は、報酬関数の変化や行動空間の拡大といった非定常な環境において、モデルを最初から再学習させることなくリアルタイムで適応可能な自己適応型強化学習フレームワーク「MORPHIN」を提案している。
TL;DR(結論)
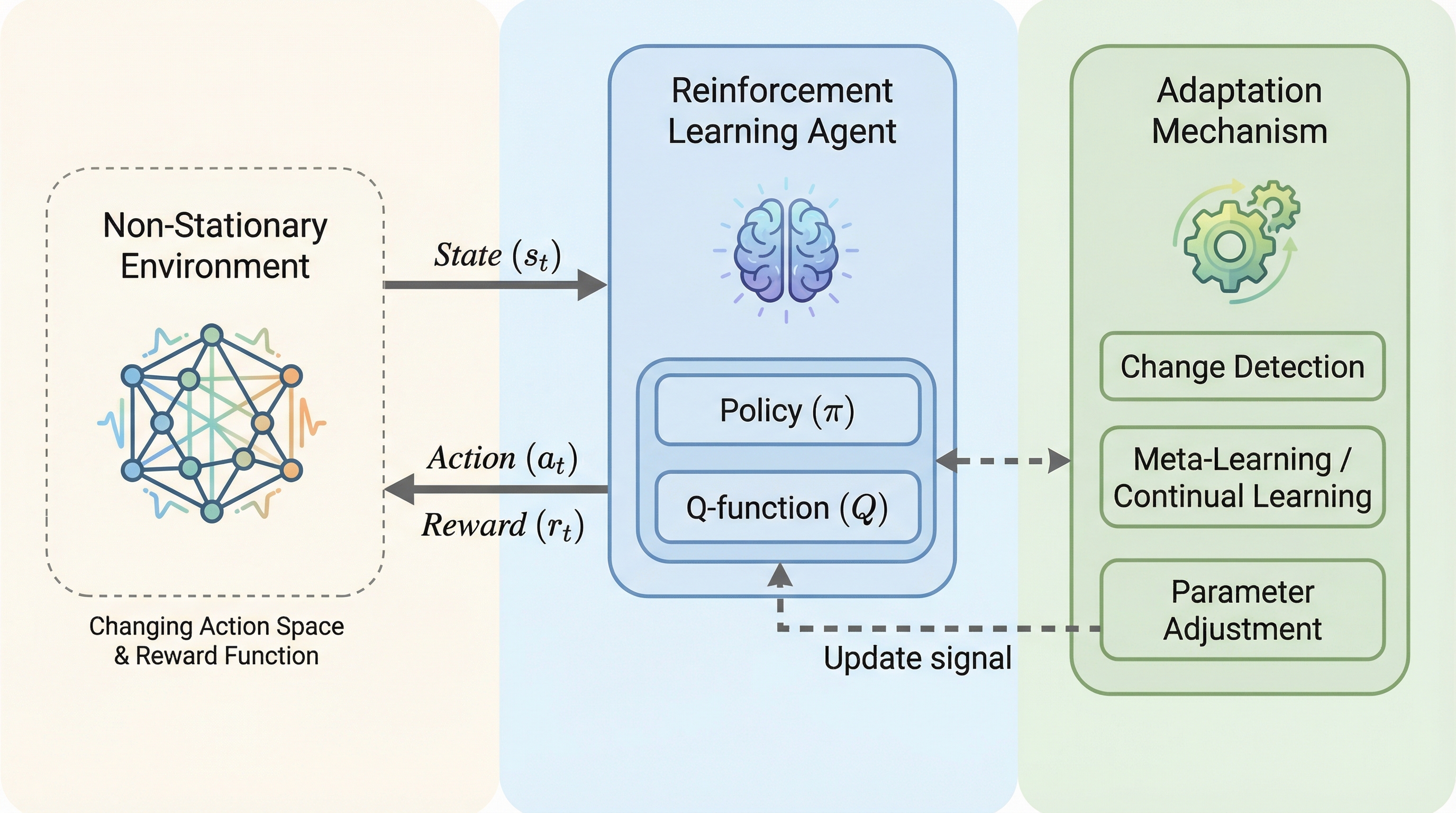
本研究は、報酬関数の変化や行動空間の拡大といった非定常な環境において、モデルを最初から再学習させることなくリアルタイムで適応可能な自己適応型強化学習フレームワーク「MORPHIN」を提案している。 この手法は、Page-Hinkleyテストを用いたコンセプトドリフト検出と、時間的差分(TD)誤差に基づく学習率および探索率の動的な調整を統合することで、過去の知識を保持しながら新しい状況へ迅速に適応し、破滅的忘却を防ぐ。 Gridworldと交通信号制御のシミュレーションによる検証の結果、標準的なQ学習と比較して学習効率が最大1.7倍向上し、環境の変化後も迅速に最適方策へ収束することを確認しており、実世界の動的なシステムへの適用可能性を示している。
なぜこの問題か
従来の強化学習アルゴリズムの多くは、環境の遷移確率や報酬関数が一定である「定常な」マルコフ決定過程を前提として設計されている。しかし、現実世界のアプリケーションにおいては、エージェントが置かれる環境条件が時間とともに変化する「非定常性」が極めて大きな課題となる。具体的には、エージェントが達成すべき目標が変わることで報酬関数がシフトしたり、利用可能な行動の選択肢が途中で増えたりする状況が頻繁に発生する。このような環境の変化は「コンセプトドリフト」と呼ばれ、エージェントがそれまでに学習した方策や行動価値(Q値)が、将来の報酬を最大化する上で最適ではなくなってしまうことを意味している。 既存のQ学習では、学習率や探索率が固定されているか、あるいは単純な時間経過による減衰スケジュールに従っている。そのため、一度学習が収束した後に環境が変化しても、新しい状況を十分に探索し直す柔軟性が不足しており、結果としてパフォーマンスが著しく低下し、回復に多大な時間を要する。また、新しい知識を取り込もうとしてモデルを単純に更新し続けると、過去に学んだ重要な情報を完全に上書きして失ってしまう「破滅的忘却」の問題も発生する。…
核心:何を提案したのか
本論文では、非定常な環境においてエージェントの行動を動的に適応させるための自己適応型Q学習フレームワークである「MORPHIN」を提案している。このフレームワークの核心は、能動的な環境監視によるドリフト検出と、それに応じた学習パラメータの反応的な調整を統合した点にある。MORPHINは、環境の変化に直面した際にモデルを最初から再学習させるのではなく、既存のQテーブルを保持したまま、その場でパラメータを最適化して新しい状況に適応させるアプローチを取る。 この提案手法の最大の特徴は、Page-Hinkleyテスト(PHテスト)と呼ばれる統計的な変化点検出手法を強化学習のループに組み込んだことである。これにより、エージェントは自身のパフォーマンスである累積報酬の変化を監視し、環境に何らかの変異が生じたことを自律的に認識できる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related