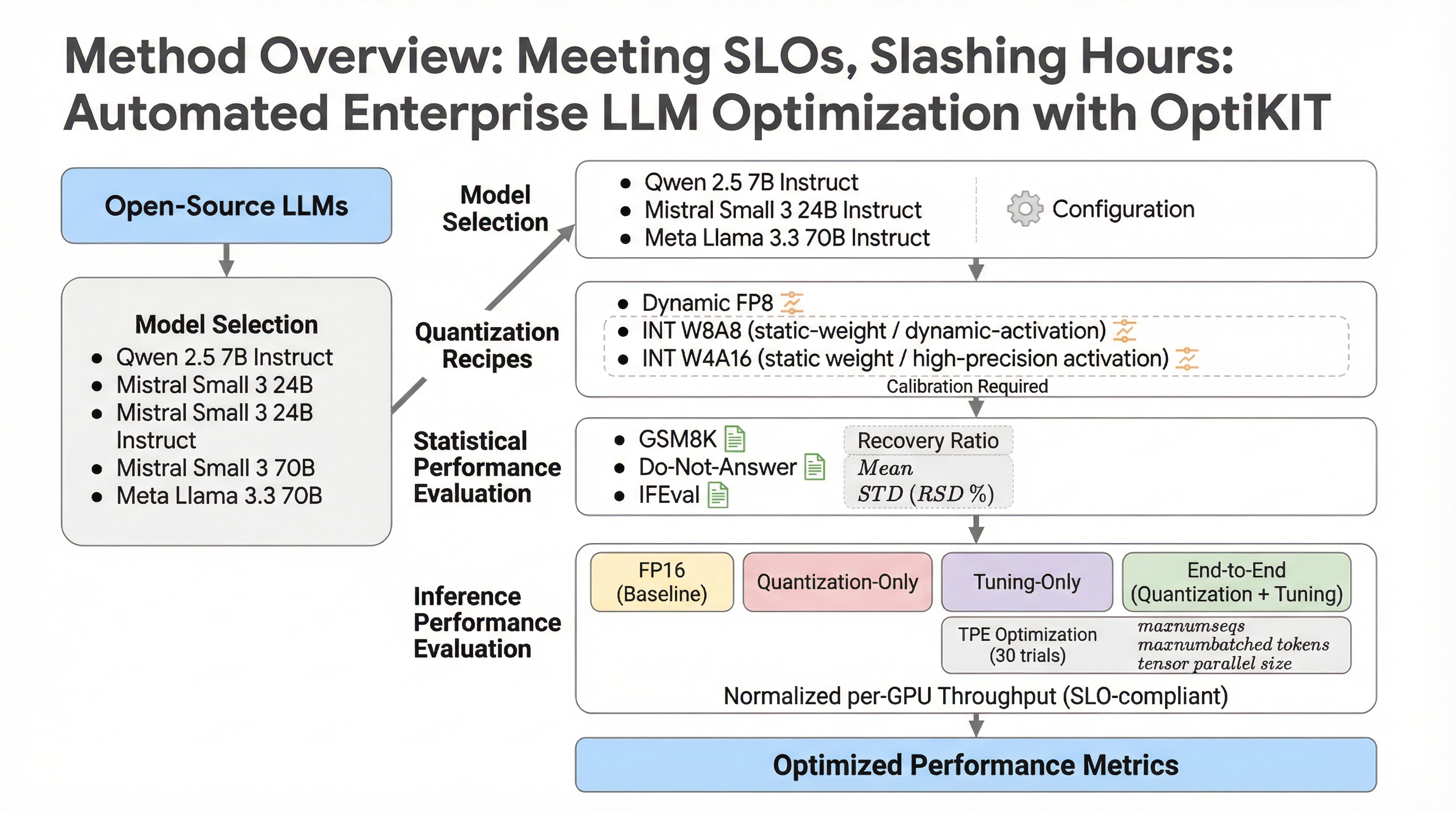
SLOの達成と時間の劇的削減:OptiKITによる自動化されたエンタープライズLLM最適化
企業が直面する大規模言語モデル(LLM)導入の最大の障壁である、限られたGPU予算内での効率的なスケーリングと、高度な専門知識を要する手動最適化のボトルネックを解消するため、分散型最適化フレームワーク「OptiKIT」を開発しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
企業が直面する大規模言語モデル(LLM)導入の最大の障壁である、限られたGPU予算内での効率的なスケーリングと、高度な専門知識を要する手動最適化のボトルネックを解消するため、分散型最適化フレームワーク「OptiKIT」を開発しました。
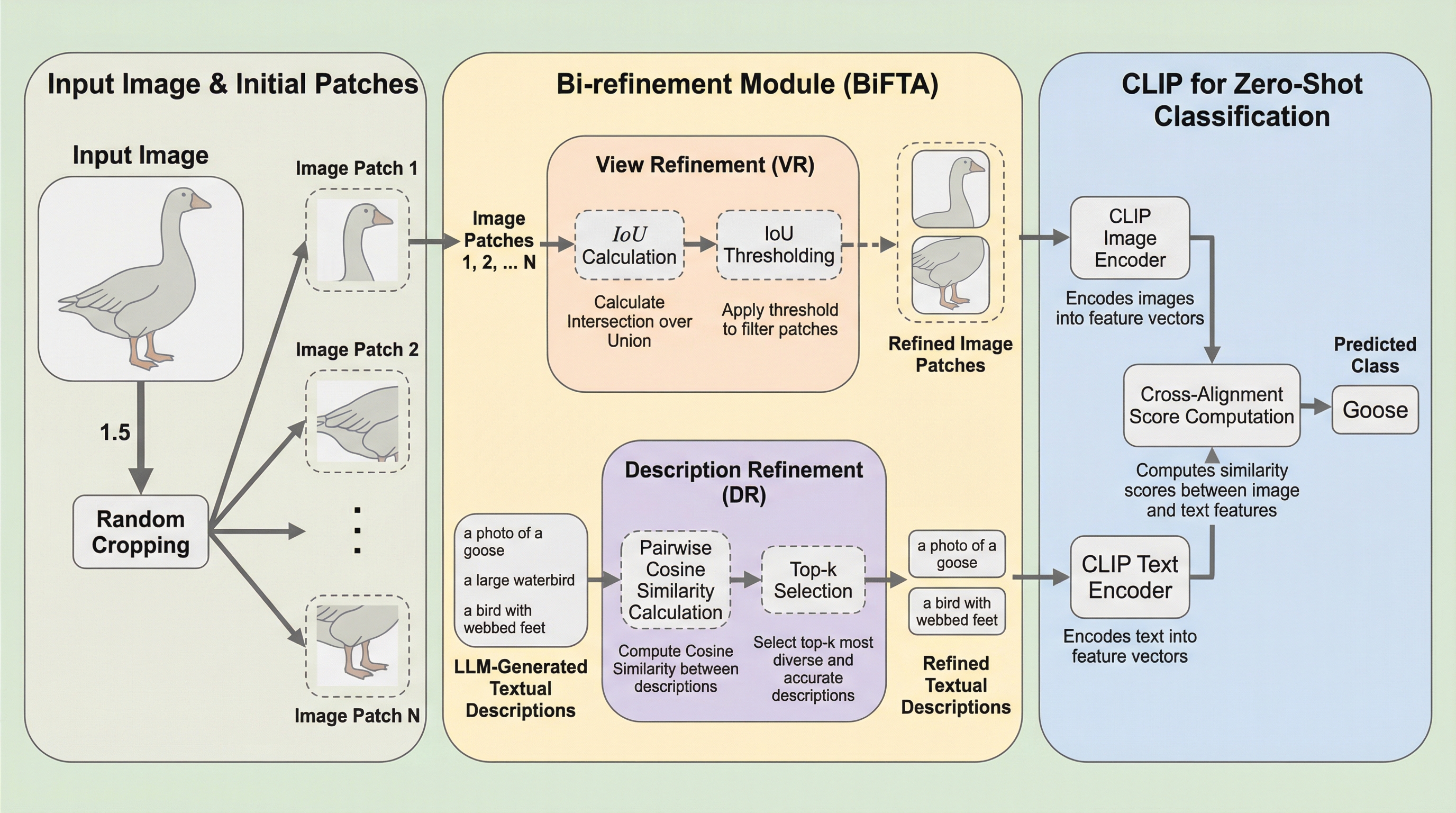
従来のビジョン言語モデルでは、画像パッチのランダムな切り出しや大規模言語モデルによるテキスト生成において、情報の重複(冗長性)が精度のボトルネックとなっていました。 本研究が提案するBiFTAは、画像パッチ間の重なりをIoUで評価して重複を省く「ビュー精緻化」と、テキスト間の類似度を計算して多様性を確保する「記述精緻化」を導入しました。 この手法をCLIPに適用した結果、6つの主要ベンチマークにおいて従来の最高水準を上回るゼロショット分類精度を達成し、情報の量よりも質と多様性が重要であることを証明しました。
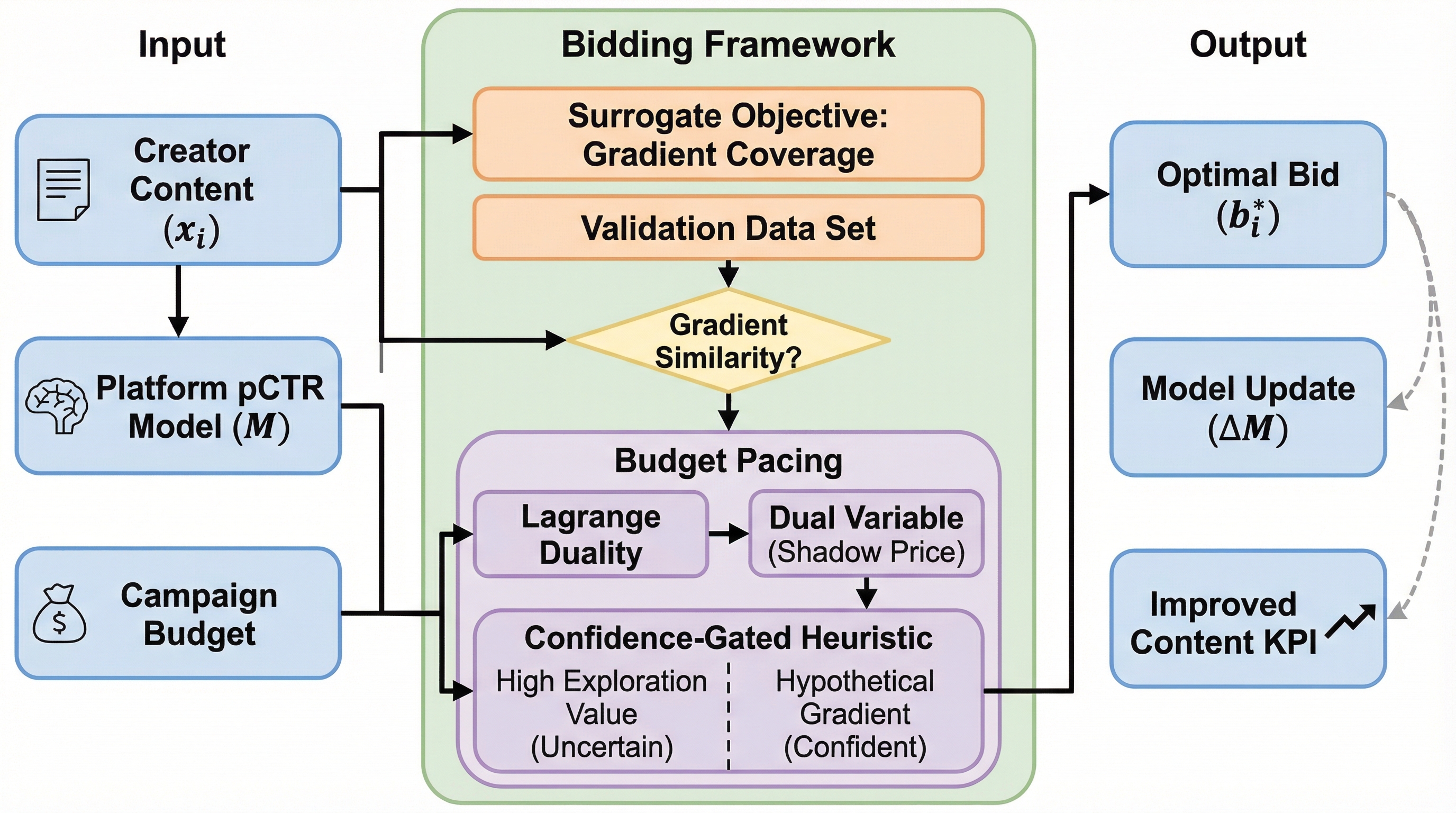
現代のコンテンツプラットフォームでは、新規投稿の露出を確保するために有料プロモーションが活用されていますが、実証分析の結果、この仕組みには直感に反する欠陥があることが判明しました。質の高いコンテンツに対して不適切なオーディエンスへの露出を強制すると、エンゲージメント信号が汚染され、将来的な推薦アルゴリズムによる評価が低下してしまいます。 本研究では、コンテンツプロモーションを「短期的な価値獲得」と「長期的なモデル改善」の二重目的最適化問題として再定義し、モデルの不確実性を低減するための計算可能な指標として「勾配カバレッジ」を導入しました。これは統計学におけるフィッシャー情報量や最適計画法との理論的な関連性を持ち、リアルタイムの入札環境でも実行可能な設計となっています。 ラグランジュ双対性に基づく二段階の自動入札アルゴリズムを開発し、ラベルが不明な入札時点でも学習信号を推定できる信頼性ゲート付きのヒューリスティックを提案し、実際のデータセットを用いた検証で、従来の戦略を上回るモデル精度とオーガニックな成果の向上を確認しました。
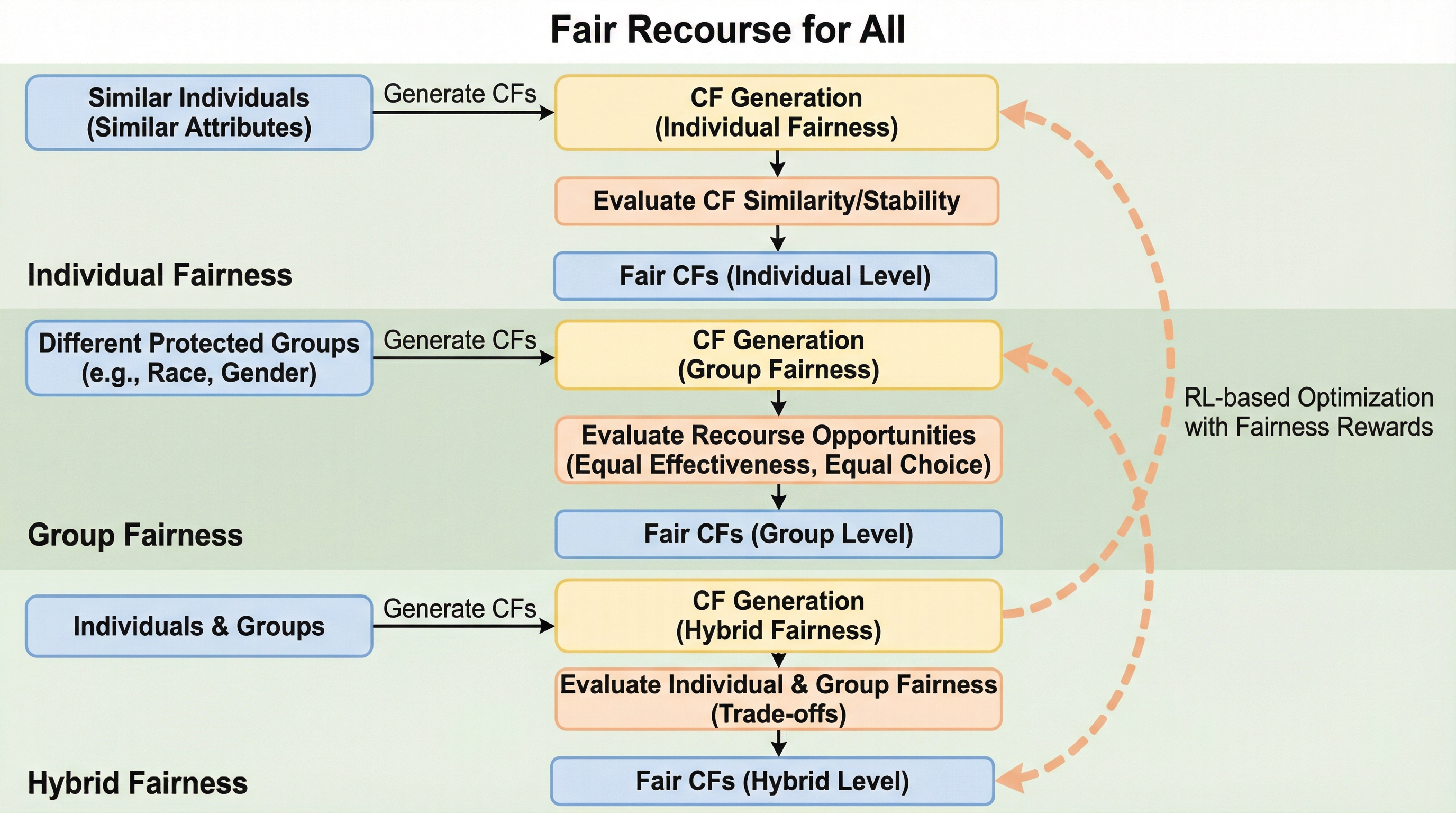
機械学習の意思決定を説明する反実仮想説明(CF)において、似た属性の個人に同様の改善策を出す「個人の公平性」と、保護属性グループ間で機会を均等にする「集団の公平性」を両立する「ハイブリッド公平性」を定義した。
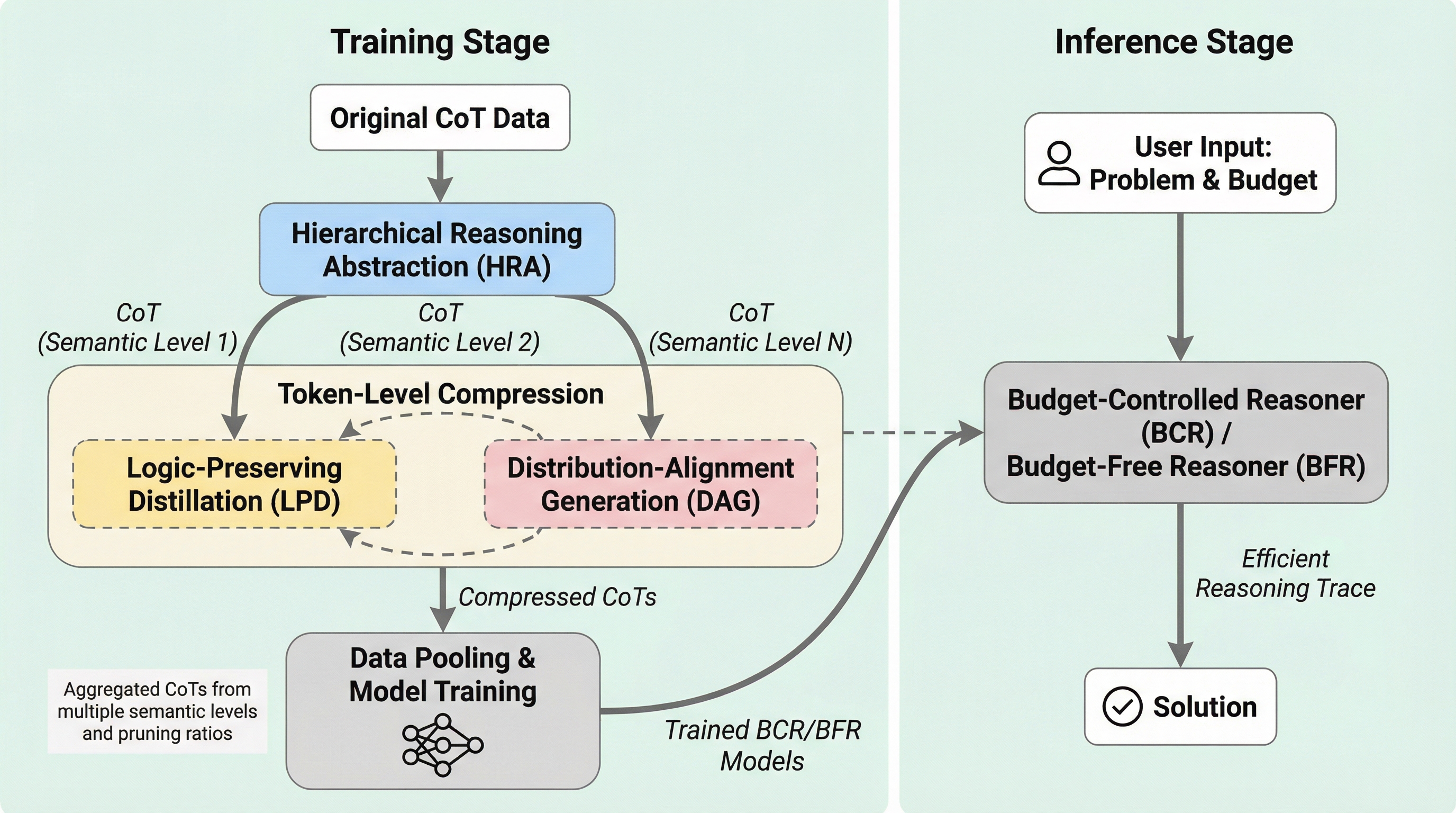
大規模言語モデルの思考の連鎖(CoT)における冗長性を排除するため、意味レベルの要約とトークンレベルの削減を統合した二重粒度フレームワーク「CtrlCoT」を提案し、推論精度を維持しながら計算コストを大幅に削減することに成功した。
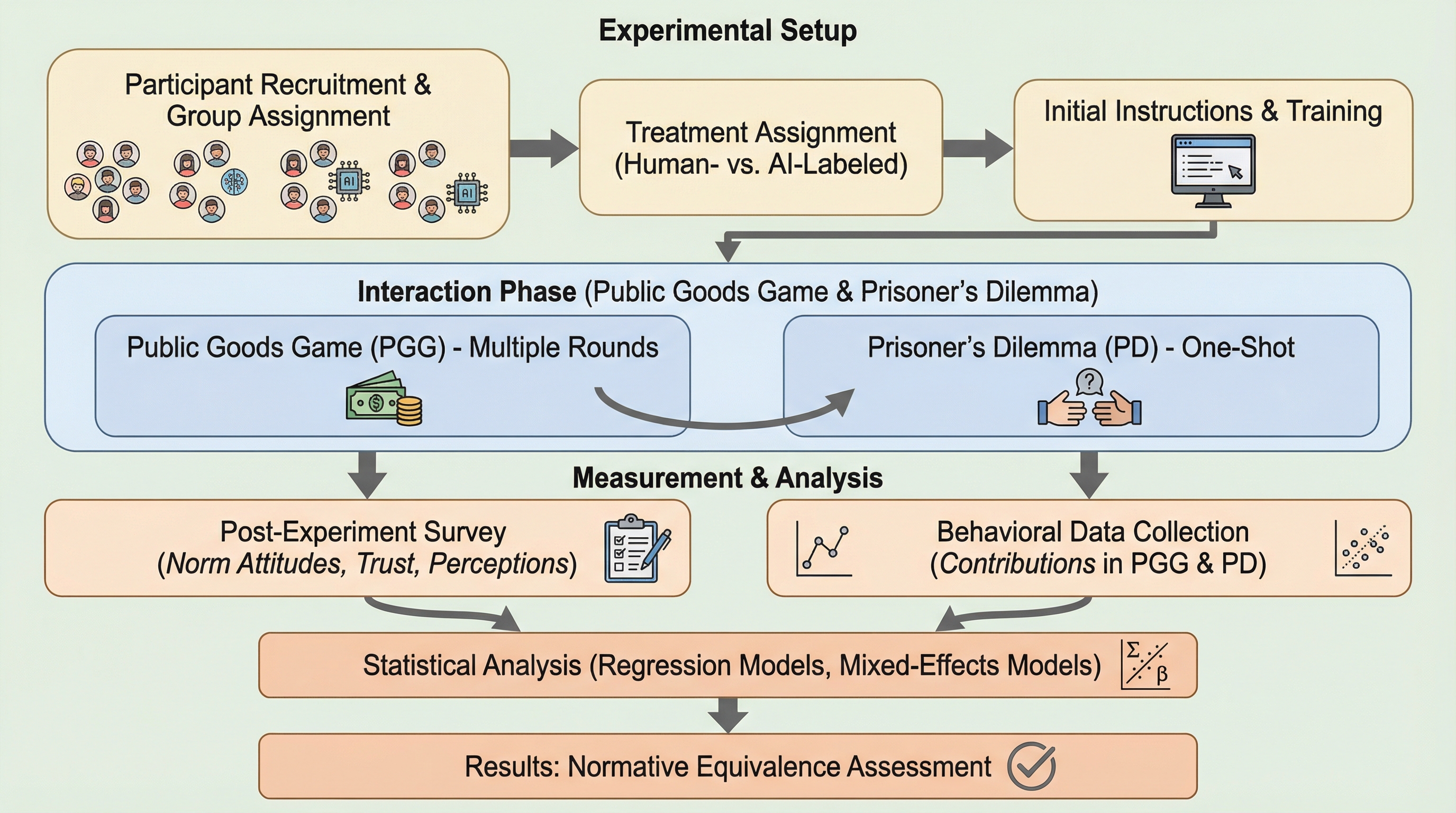
3人の人間と1つの自律的エージェント(人間またはAIと表示)で構成されるグループにおいて、公共財ゲームを通じた協力行動の検証が行われました。その結果、参加者の協力レベルは相手が人間かAIかというラベルによって左右されず、グループ全体の振る舞いや過去の行動を維持しようとする慣性によって決定されることが明らかになりました。
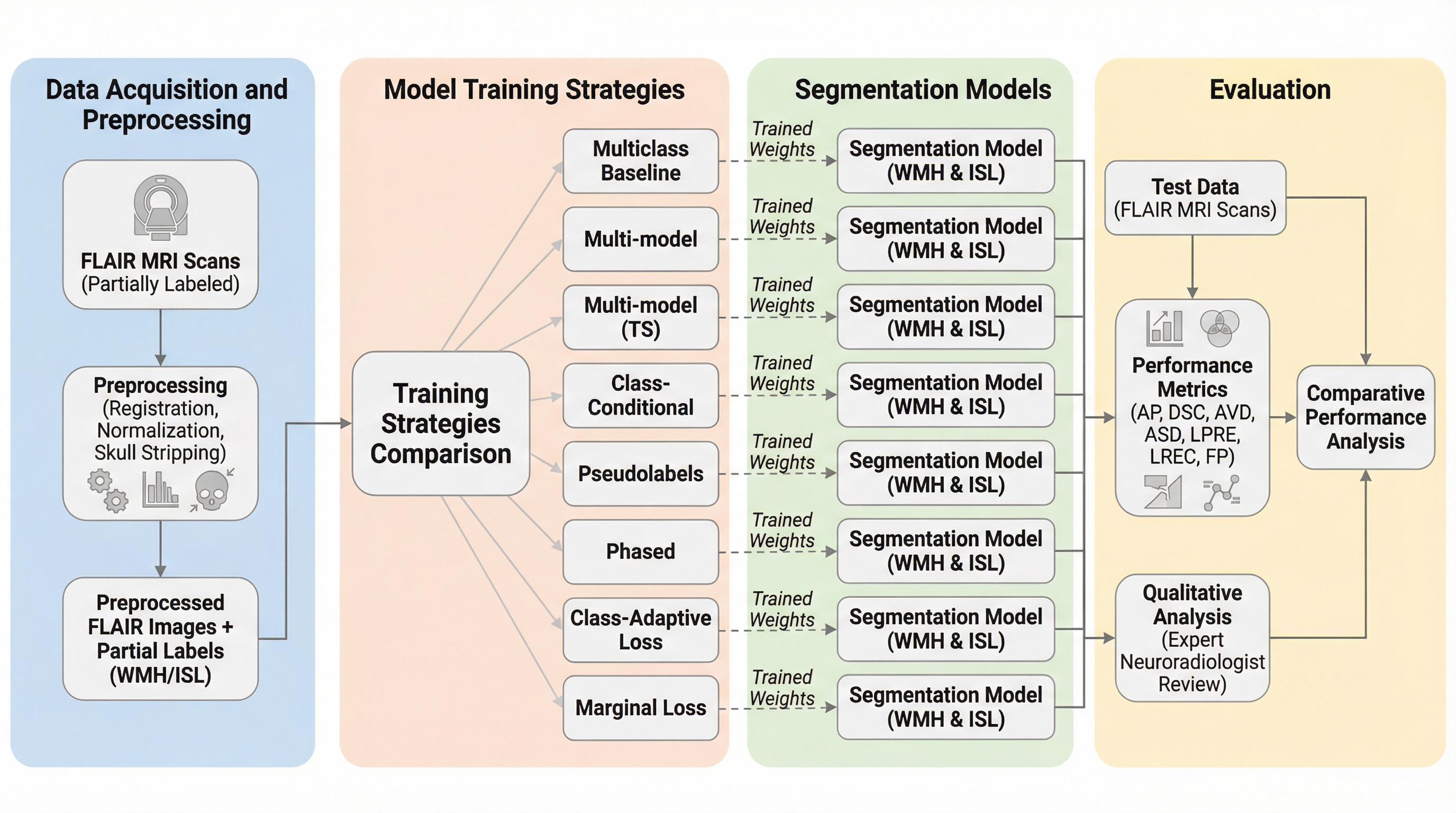
FLAIR MRI画像において、見た目が酷似し混同されやすい白質高信号域(WMH)と虚血性脳梗塞病変(ISL)を正確に分離・抽出するため、完全なラベルが揃っていない不完全なデータセットを有効活用する6つの学習戦略を比較検証した。
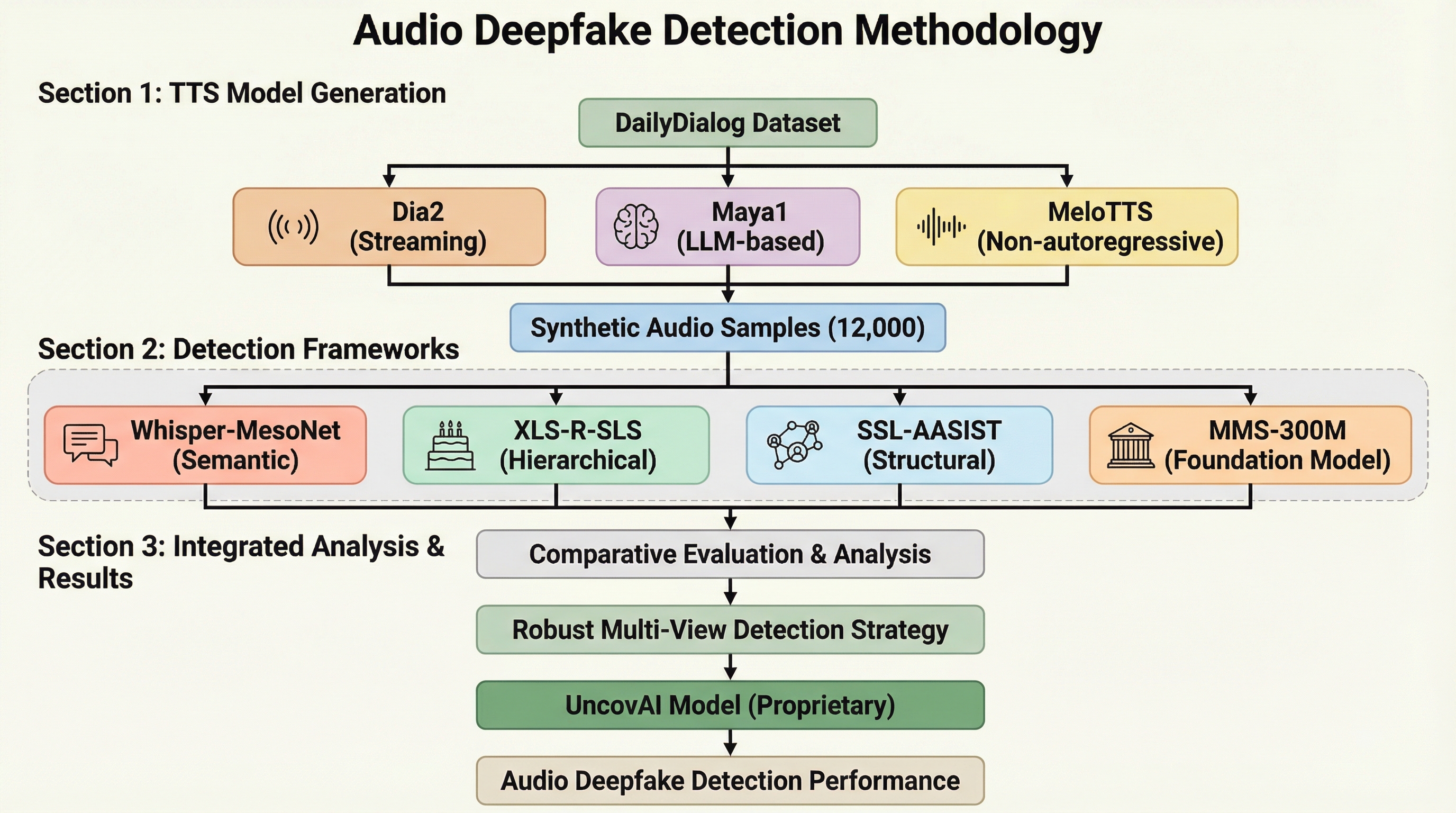
最新のText-to-Speech(TTS)技術であるDia2、Maya1、MeloTTSは、大規模言語モデルやフローマッチング、階層型コーデックを採用することで、従来の検出器では識別が困難な極めて自然な音声を生成する。
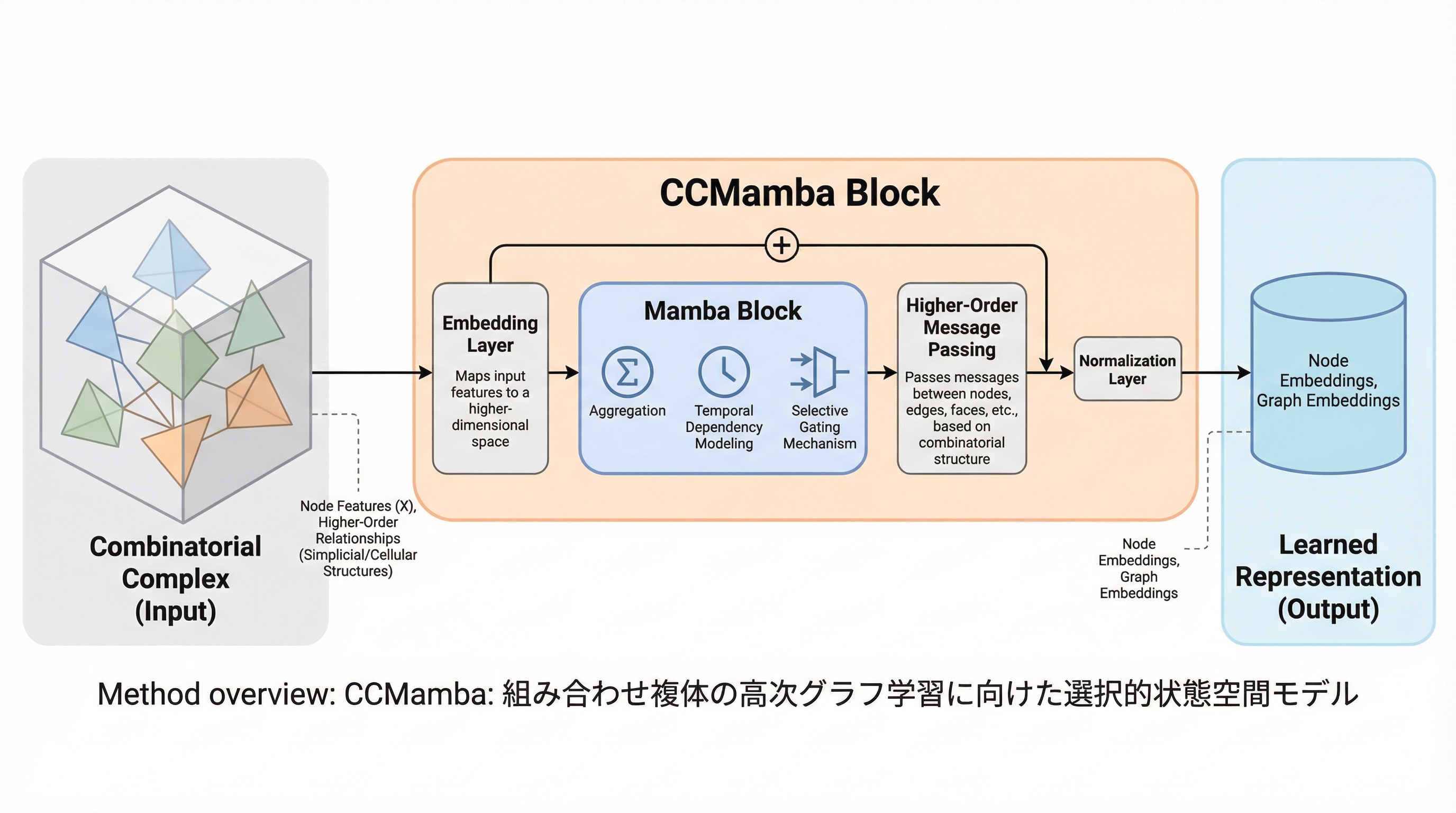
現実世界の複雑なデータ構造を扱うため、グラフやハイパーグラフを包括する「組み合わせ複体」という統一的なトポロジカル枠組みを採用し、線形時間で動作する初のMambaベースの学習モデルであるCCMambaを提案した。
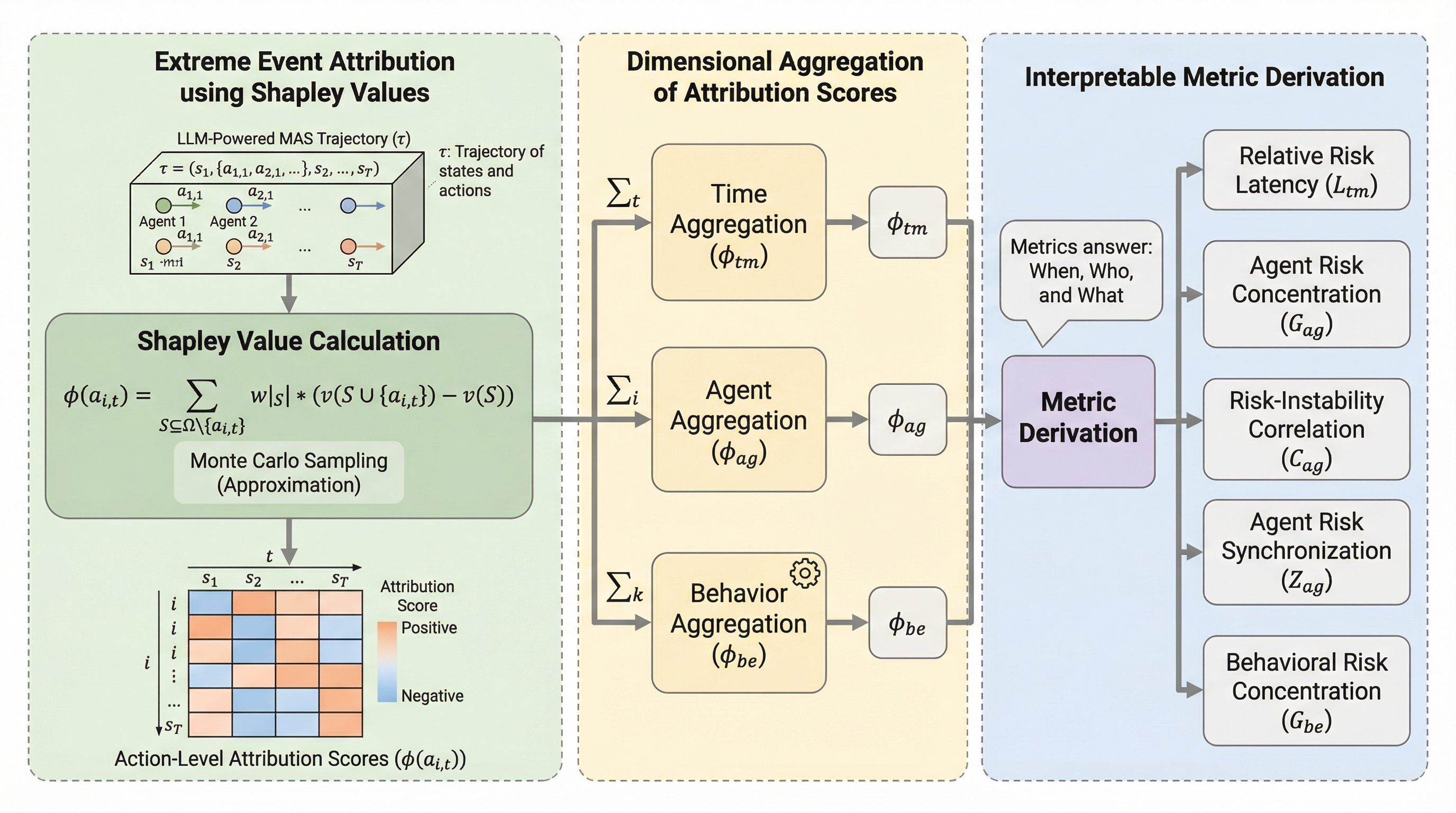
大規模言語モデル(LLM)を用いたマルチエージェントシステムで発生する、予測困難な「ブラックスワン」現象を解明するため、世界で初めて「時間・個人・行動」の3次元からリスクを定量化する解釈フレームワークを提案しました。