CtrlCoT: 推論の質を保ちつつCoTを圧縮する二重粒度フレームワーク
大規模言語モデルの思考の連鎖(CoT)における冗長性を排除するため、意味レベルの要約とトークンレベルの削減を統合した二重粒度フレームワーク「CtrlCoT」を提案し、推論精度を維持しながら計算コストを大幅に削減することに成功した。
TL;DR(結論)
大規模言語モデルの思考の連鎖(CoT)における冗長性を排除するため、意味レベルの要約とトークンレベルの削減を統合した二重粒度フレームワーク「CtrlCoT」を提案し、推論精度を維持しながら計算コストを大幅に削減することに成功した。 論理構造を保護する蒸留プロセス(LPD)や生成分布を整合させる手法(DAG)を導入することで、MATH-500において既存手法より30.7%少ないトークン数で7.6ポイント高い精度を達成し、情報の欠落を防ぎつつ極めて高いトークン効率を実現している。 ユーザーが計算リソースに応じてトークン予算を指定できる「予算制御型推論器(BCR)」と、最適な長さを自動的に選択する「予算フリー推論器(BFR)」の両方を構築したことで、実用的な利便性と柔軟なリソース管理の両立を可能にした。
なぜこの問題か
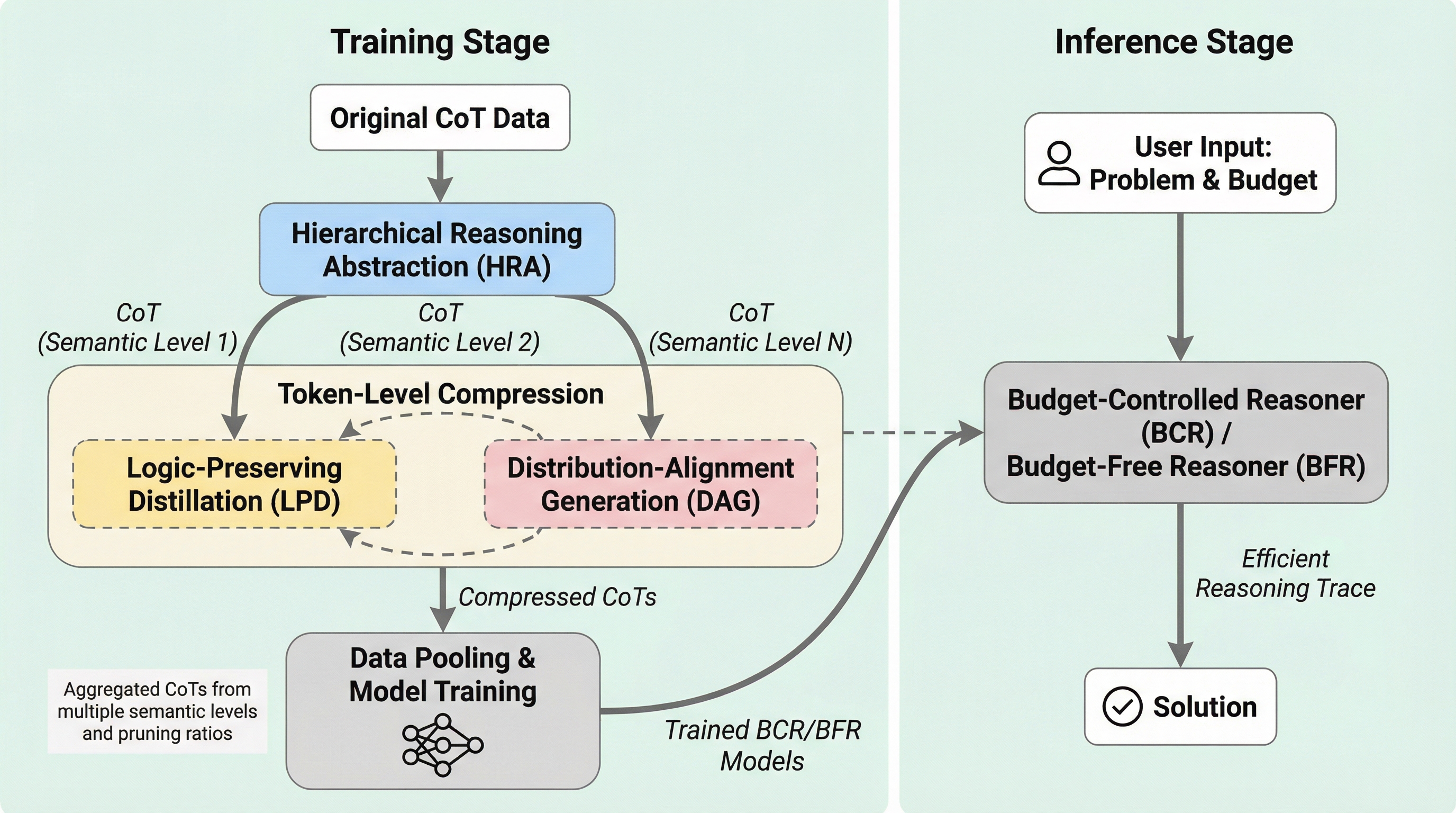
大規模言語モデル(LLM)において、思考の連鎖(CoT)プロンプティングは複雑な推論タスクの精度を向上させる強力な手法として広く普及している。しかし、この手法は中間的な推論プロセスを詳細に出力するため、生成されるトークン数が膨大になり、デコードの遅延、メモリ使用量の増大、そして運用コストの上昇という深刻な効率性の課題を引き起こしている。この問題に対し、推論の正確性を保ちつつCoTを圧縮する研究が進められているが、既存の手法にはそれぞれ大きな限界が存在する。意味レベルの圧縮手法は、推論の軌跡を書き換えて簡略化するが、意味の整合性を重視するあまり圧縮率が限定的になりがちである。一方で、トークンレベルの削減手法は高い圧縮率を実現できるものの、文脈の理解が不足しているために数値や演算子といった推論に不可欠な情報を誤って削除してしまい、精度が著しく低下する傾向がある。 これら二つのアプローチを単純に組み合わせることは、技術的にいくつかの困難な障壁がある。第一に「逐次依存性」の問題である。意味的な凝縮によってトークンの形式が変化すると、トークン削減器が依存していたパターンが無効化され、判断が不安定になる。…
核心:何を提案したのか
本研究では、意味レベルの凝縮とトークンレベルの削減を調和させた二重粒度のCoT圧縮フレームワーク「CtrlCoT」を提案している。このフレームワークの核心は、前述の課題を克服するために設計された「階層的推論抽象化(HRA)」、「論理保存蒸留(LPD)」、「分布整合生成(DAG)」という3つの主要コンポーネントの統合にある。HRAは、異なる意味的粒度を持つ複数のCoTを生成することで、後のトークン削減による情報損失を補完する役割を果たす。LPDは、数学的な推論において不可欠な数値や演算子、論理的な接続詞を優先的に保持するようにトークン削減器を訓練し、重要な情報を守る。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related