高度なTTSモデル時代における音声ディープフェイク検出:統合的アプローチの必要性
最新のText-to-Speech(TTS)技術であるDia2、Maya1、MeloTTSは、大規模言語モデルやフローマッチング、階層型コーデックを採用することで、従来の検出器では識別が困難な極めて自然な音声を生成する。
TL;DR(結論)
最新のText-to-Speech(TTS)技術であるDia2、Maya1、MeloTTSは、大規模言語モデルやフローマッチング、階層型コーデックを採用することで、従来の検出器では識別が困難な極めて自然な音声を生成する。 検証の結果、特定のアーキテクチャに特化した検出器は他の生成手法に対して脆弱であり、特にセマンティック(意味的)検出器はLLMベースの合成に、階層型モデルはフローマッチング方式に失敗する傾向がある。 未知の高度な音声偽造の脅威に対抗するためには、単一の検出手法に頼るのではなく、信号レベル、構造レベル、意味レベルの分析を組み合わせた統合的なマルチビュー検出戦略の構築が不可欠である。
なぜこの問題か
ニューラルネットワークを用いた音声合成技術(TTS)の急速な進歩は、アクセシビリティの向上やクリエイティブな表現の可能性を広げる一方で、音声ディープフェイクという新たな脅威を生み出している。かつてのTTSシステムは、ロボットのような独特の韻律や話者のバリエーションの少なさから比較的容易に識別が可能であった。しかし、2024年後半から2025年にかけて登場した最新のモデルは、大規模言語モデル(LLM)のアーキテクチャやフローマッチング生成アプローチを活用しており、人間と見分けがつかないほど自然で感情豊かな連続対話を生成できる。これにより、音声生体認証のセキュリティが脅かされ、誤情報の拡散リスクが増大し、証拠としての音声に対する信頼が損なわれる事態となっている。 音声ディープフェイクの検出は、長らくニューラルボコーダーが残す特定のアーティファクト(不自然な痕跡)や、時間周波数表現における不規則性の特定に依存してきた。…
核心:何を提案したのか
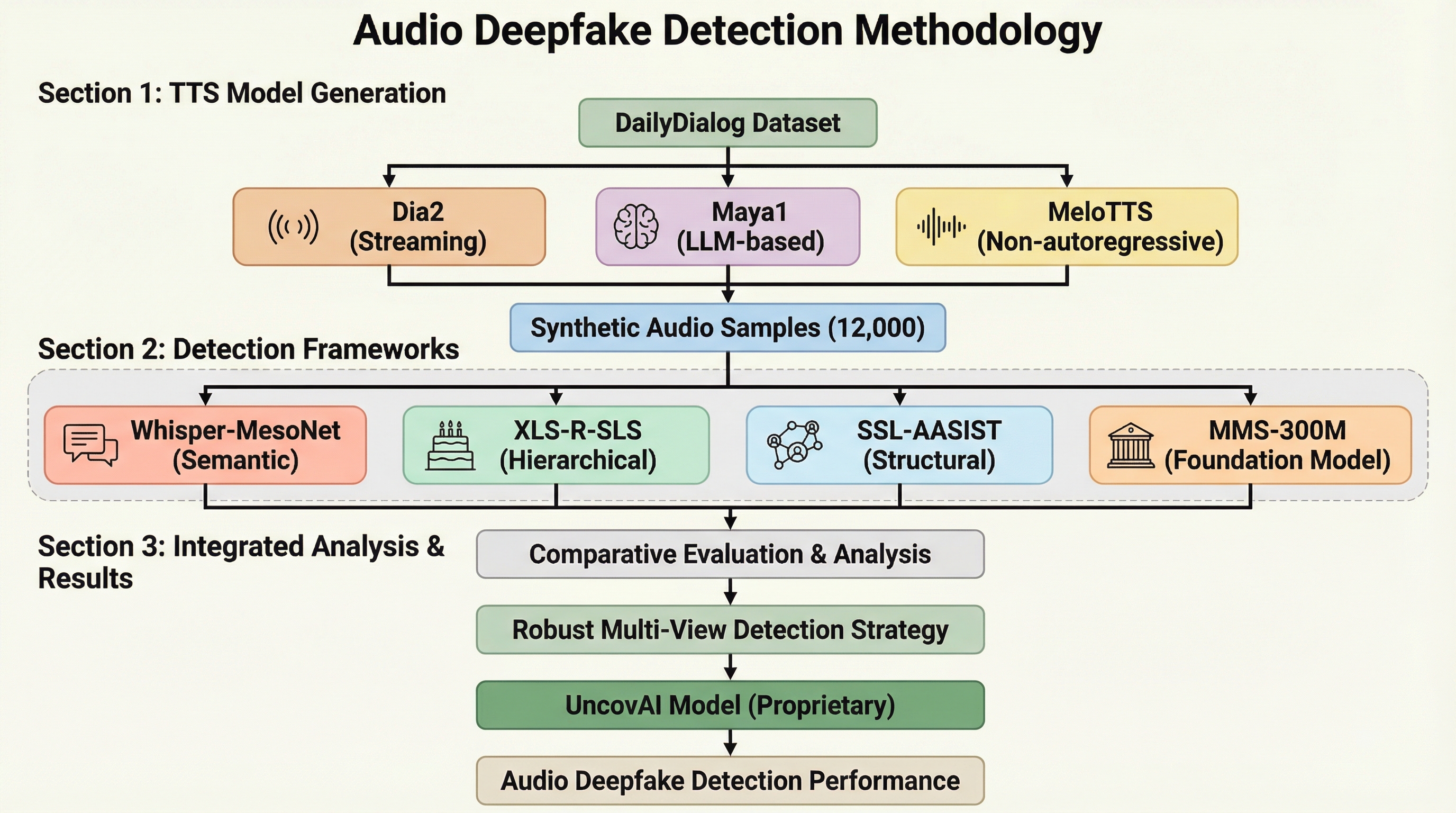
本研究では、現代のニューラル音声合成の多様性に対して検出アーキテクチャがどのように反応するかを明らかにするため、初めての経験的な特性評価を提案している。具体的には、2024年から2025年にリリースされた、それぞれ根本的に異なるアプローチを持つ3つの最先端TTSモデル(Dia2、Maya1、MeloTTS)を評価対象として選択した。これらのモデルは、ストリーミング最適化、LLMベースのニューラルコーデック生成、非自己回帰型フローマッチングという異なる生成メカニズムを代表している。 検証のために、DailyDialogデータセットから派生した12,000個の合成音声サンプルを含む新しいデータセットを構築した。このデータセットは、言語的および会話的なリアリズムを確保するように設計されている。そして、これらの多様な攻撃ベクトルに対し、4つの異なる検出フレームワークを用いて多角的な評価を実施した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related