BiFTAを回そう:ビジョン言語モデルにおける細粒度なテキスト・視覚アライメントのための双方向精緻化
従来のビジョン言語モデルでは、画像パッチのランダムな切り出しや大規模言語モデルによるテキスト生成において、情報の重複(冗長性)が精度のボトルネックとなっていました。 本研究が提案するBiFTAは、画像パッチ間の重なりをIoUで評価して重複を省く「ビュー精緻化」と、テキスト間の類似度を計算して多様性を確保する「記述精緻化」を導入しました。 この手法をCLIPに適用した結果、6つの主要ベンチマークにおいて従来の最高水準を上回るゼロショット分類精度を達成し、情報の量よりも質と多様性が重要であることを証明しました。
TL;DR(結論)
従来のビジョン言語モデルでは、画像パッチのランダムな切り出しや大規模言語モデルによるテキスト生成において、情報の重複(冗長性)が精度のボトルネックとなっていました。 本研究が提案するBiFTAは、画像パッチ間の重なりをIoUで評価して重複を省く「ビュー精緻化」と、テキスト間の類似度を計算して多様性を確保する「記述精緻化」を導入しました。 この手法をCLIPに適用した結果、6つの主要ベンチマークにおいて従来の最高水準を上回るゼロショット分類精度を達成し、情報の量よりも質と多様性が重要であることを証明しました。
なぜこの問題か
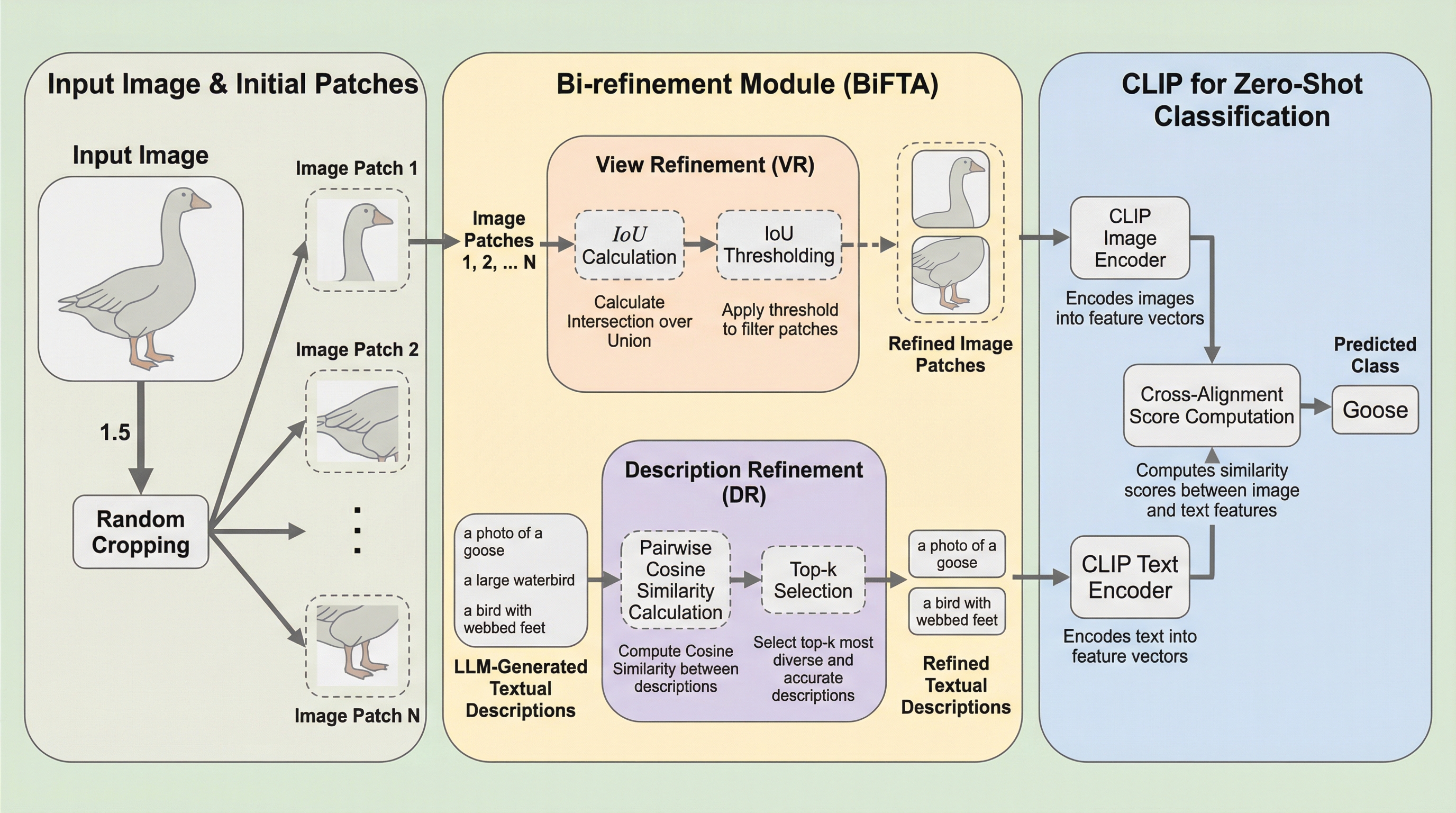
近年のビジョン言語モデル、特にCLIPのようなモデルは、膨大な画像とテキストのペアを共通の空間で整列させることで、未知のカテゴリに対しても優れたゼロショット分類能力を発揮してきました。この能力をさらに向上させるためのアプローチとして、大規模言語モデル(LLM)を用いてカテゴリごとの詳細なテキスト記述を生成し、それを画像からランダムに切り出した局所的なパッチと照合させる手法が注目されています。しかし、本論文の著者らは、このプロセスにおいて「情報の冗長性」という重大な問題が潜んでいることを詳細な分析によって明らかにしました。 具体的には、画像からランダムにパッチを切り出す際、同じような領域が何度も選ばれてしまい、それらが分類スコアの計算において過剰な影響を及ぼしてしまうという現象が発生しています。同様に、LLMによって生成されるテキスト記述も、プロンプトのテンプレートが固定されているために、意味的に重複した内容が多く含まれ、情報の多様性が著しく制限されていることが分かりました。…
核心:何を提案したのか
本研究は、視覚とテキストの両面から冗長性を排除し、より効果的な整列を実現する新しいフレームワーク「BiFTA(Bi-refinement for Fine-grained Text-visual Alignment)」を提案しました。BiFTAの核心は、その名の通り「ビュー精緻化(View Refinement: VR)」と「記述精緻化(Description Refinement: DR)」という二つの独立した精緻化プロセスを統合し、相互に補完させる点にあります。この手法の大きな特徴は、既存のCLIPモデルのアーキテクチャや重みを一切変更することなく、推論時のデータ処理を工夫するだけで適用可能な、効率的かつ強力なプラグイン的役割を果たす手法として設計されていることです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related