オフライン強化学習のための多様体制約付きエネルギーベース遷移モデル(MC-ETM)
オフライン強化学習における分布シフトと価値の過大評価を解決するため、多様体制約付きエネルギーベース遷移モデル(MC-ETM)が提案され、低次元多様体近傍での負例生成によりエネルギー地形を鋭敏化し、分布外への逸脱を正確に検知する手法が確立されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
オフライン強化学習における分布シフトと価値の過大評価を解決するため、多様体制約付きエネルギーベース遷移モデル(MC-ETM)が提案され、低次元多様体近傍での負例生成によりエネルギー地形を鋭敏化し、分布外への逸脱を正確に検知する手法が確立されました。
都市部の交通信号制御を「条件付きシーケンス生成問題」として再定義し、グラフアテンションによる空間協調と時系列トランスフォーマーを統合した新アーキテクチャ「MADT」を提案した。 従来の強化学習のような膨大な試行錯誤を必要とせず、オフラインの履歴データから学習が可能であり、目標とする報酬(Return-to-go)を指定することで、状況に応じた柔軟かつ効率的な信号制御を実現する。 アトランタやボストンの実データを用いた検証では、既存の最先端手法と比較して平均旅行時間を5〜6%短縮し、隣接する交差点間での高度な協調(グリーンウェーブ)を達成できることを証明した。
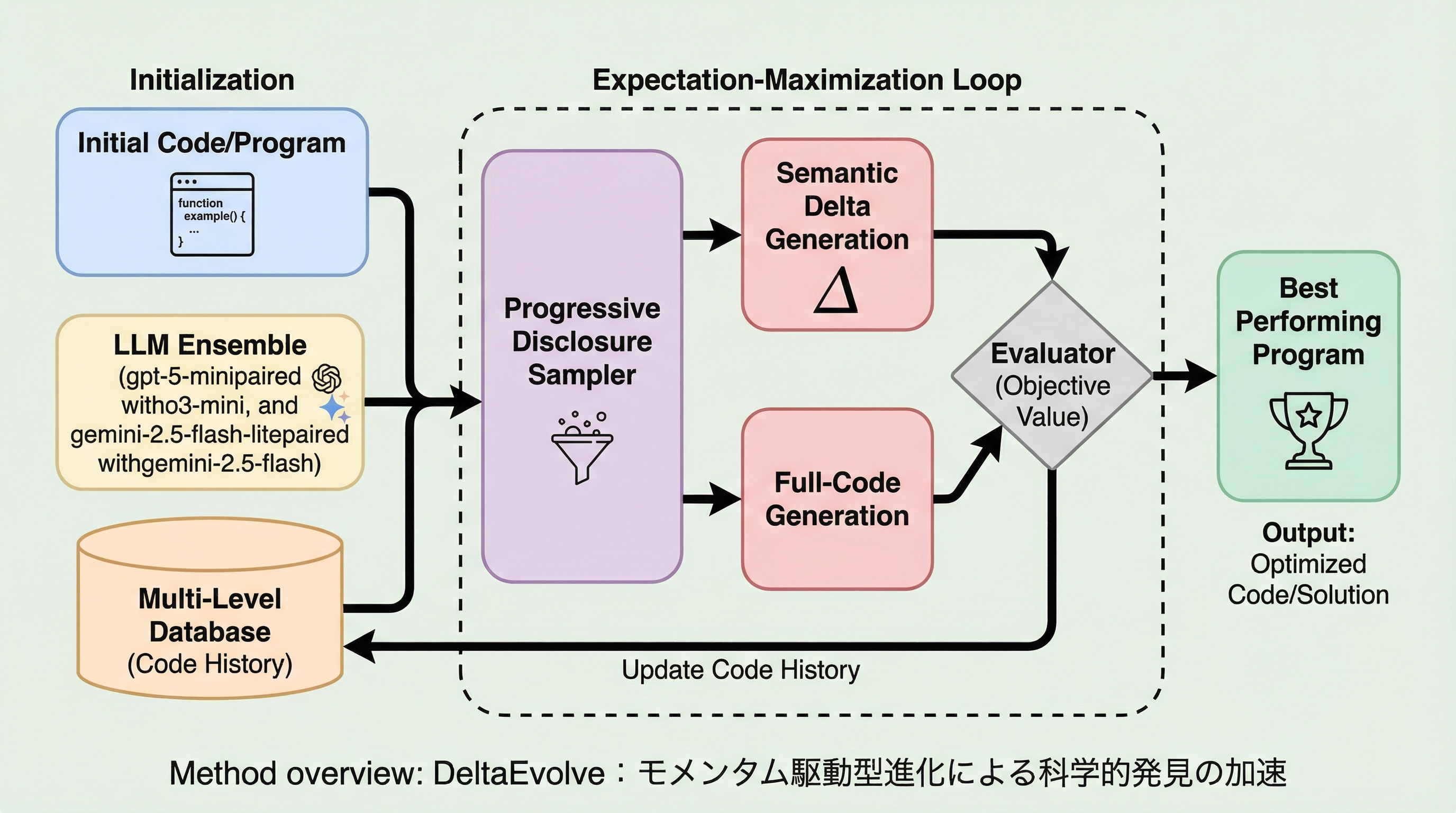
大規模言語モデル(LLM)を用いた従来の進化型エージェントは、過去の全コード履歴をコンテキストに詰め込むため、トークン消費が膨大になり、重要なアルゴリズムの核となるアイデアが実装の詳細に埋もれてしまうという課題を抱えていた。
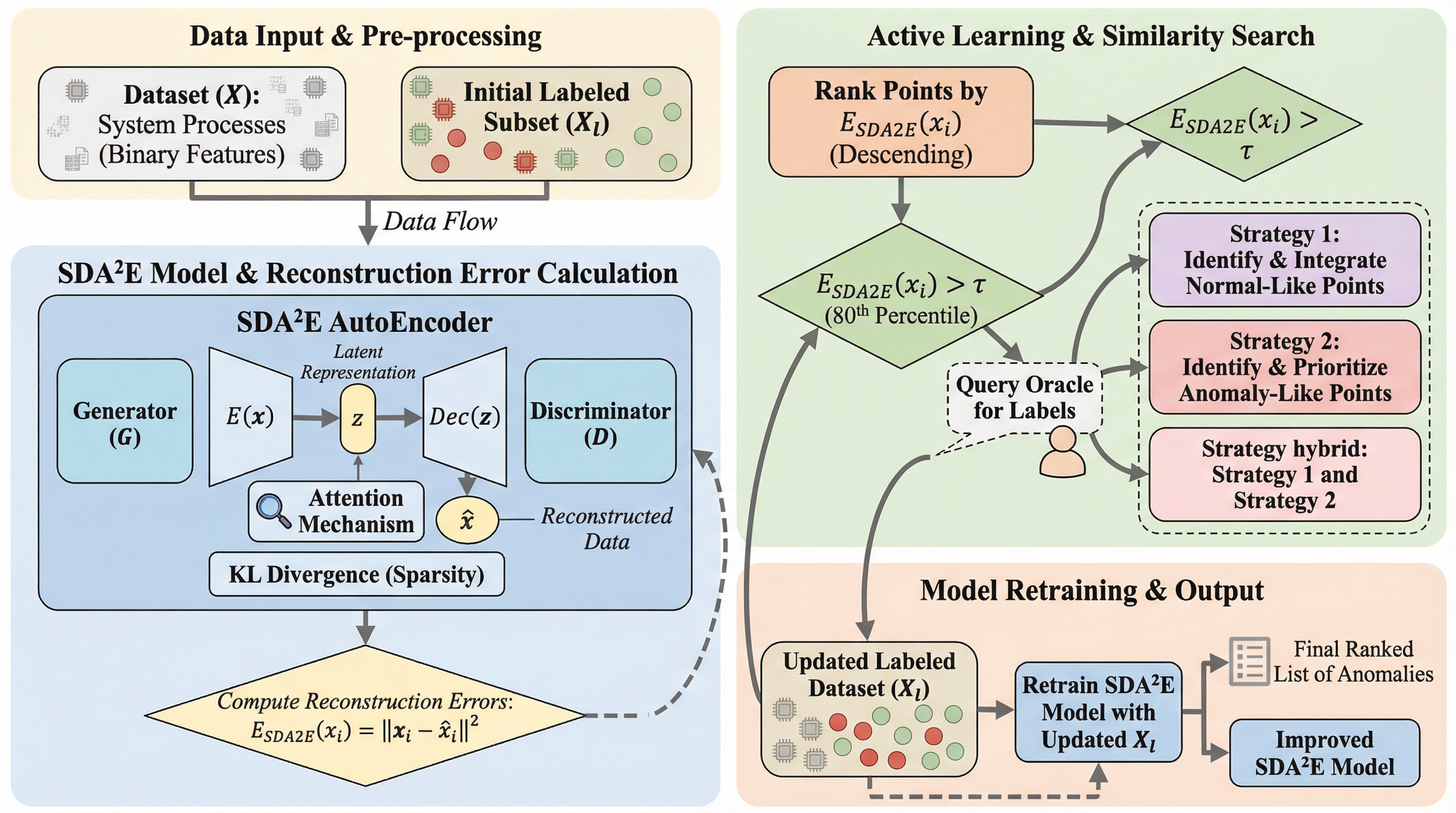
本研究では、スパース制約、アテンション機構、敵対的学習を統合した深層学習モデル「SDA²E」を開発し、サイバーセキュリティ等の極めて不均衡なデータから異常を識別する頑健な潜在表現の獲得に成功した。
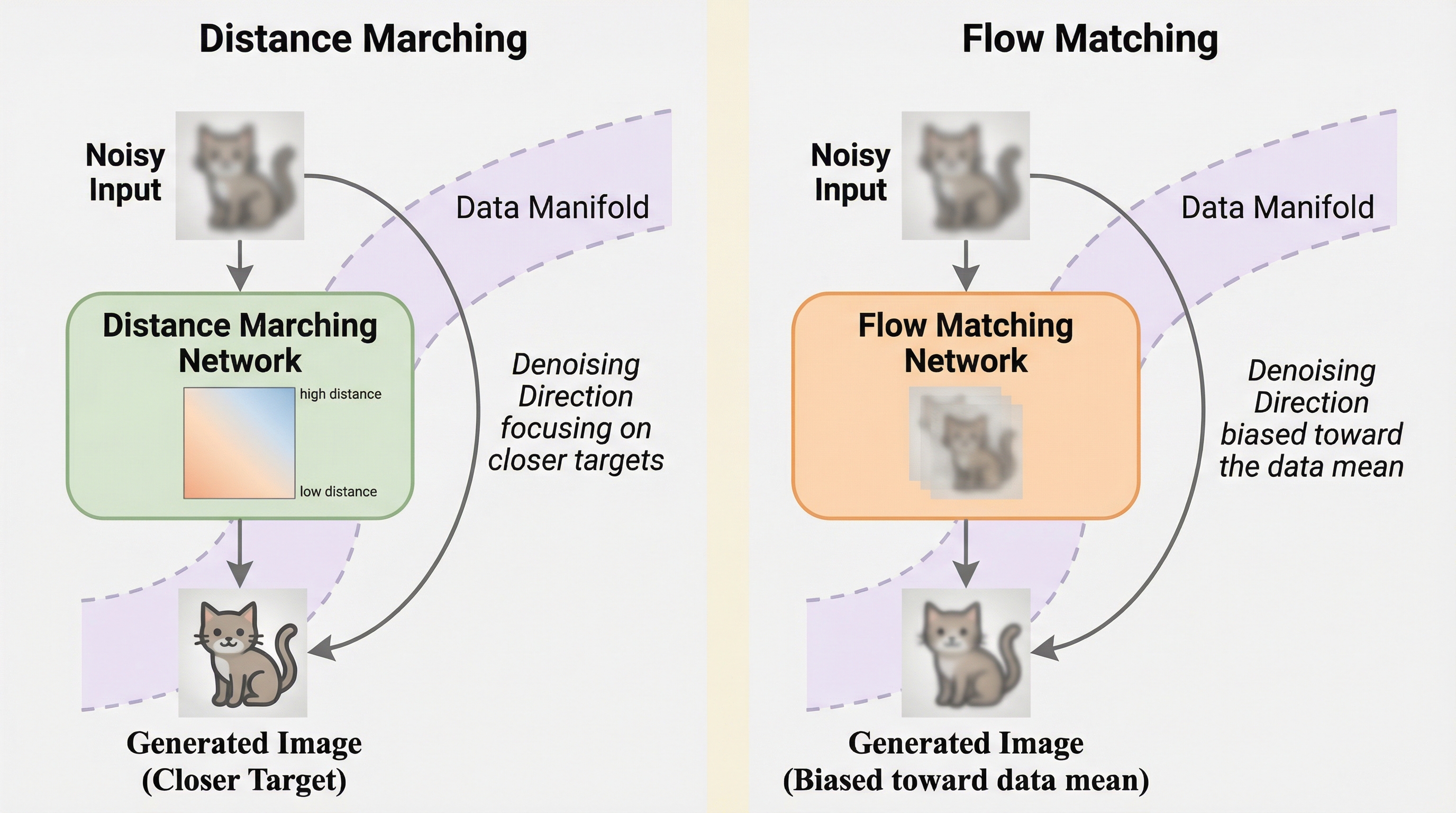
DISTANCEMARCHINGは、コンピュータグラフィックスの距離場モデリングに着想を得た、時間条件を必要としない新しい生成モデルの枠組みである。従来のモデルが抱えていた「同じノイズ入力に対して複数のノイズレベルや方向が対応してしまう」という曖昧さを、近いターゲットを優先的に学習する設計によって解決している。
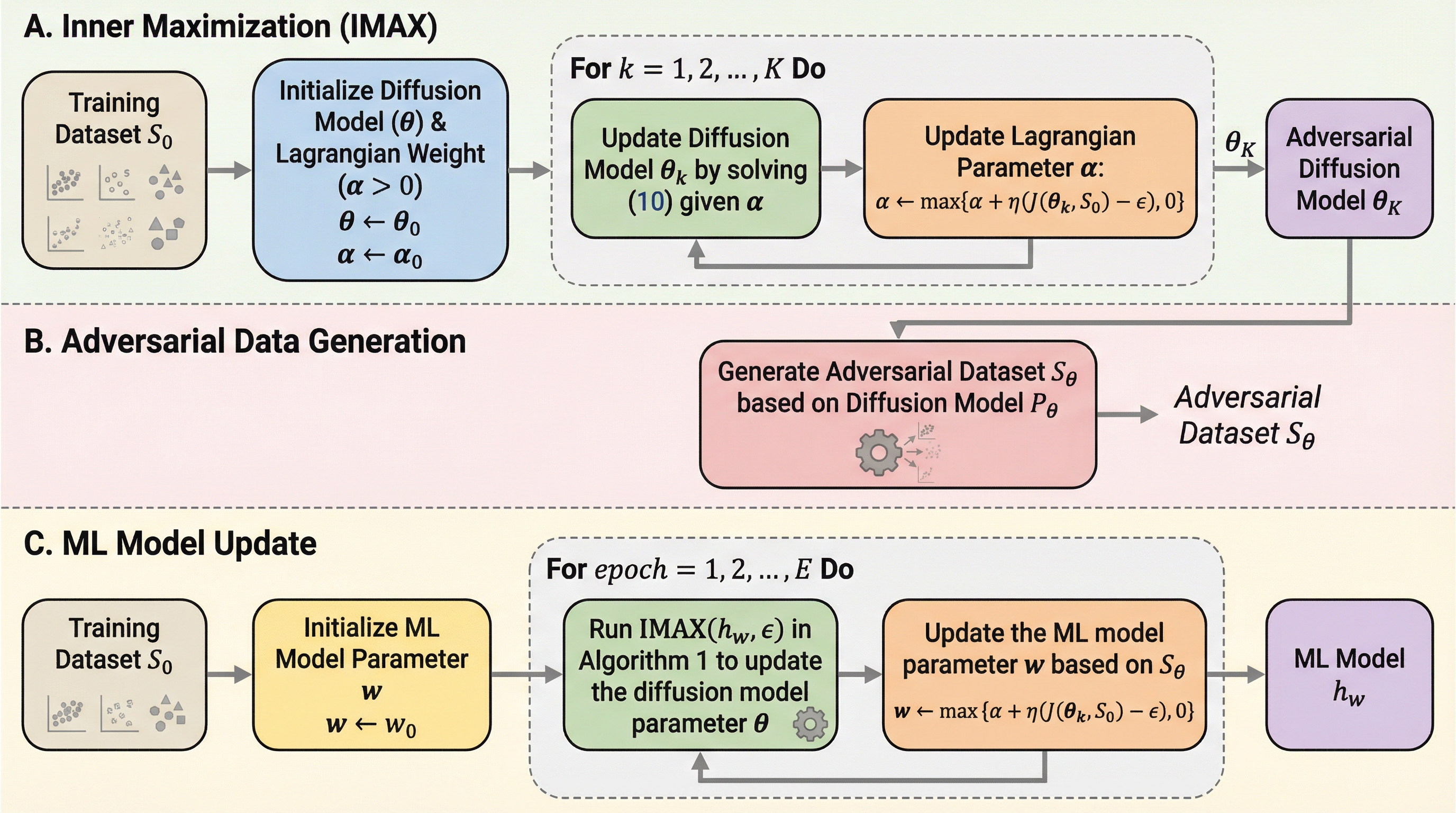
機械学習による予測を意思決定に活用するPredict-then-Optimize(PTO)において、テスト時のデータ分布の変化(OOD)による性能劣化を防ぐため、拡散モデルを用いて最悪のシナリオを想定し学習する「3D-Learning」フレームワークを提案した。
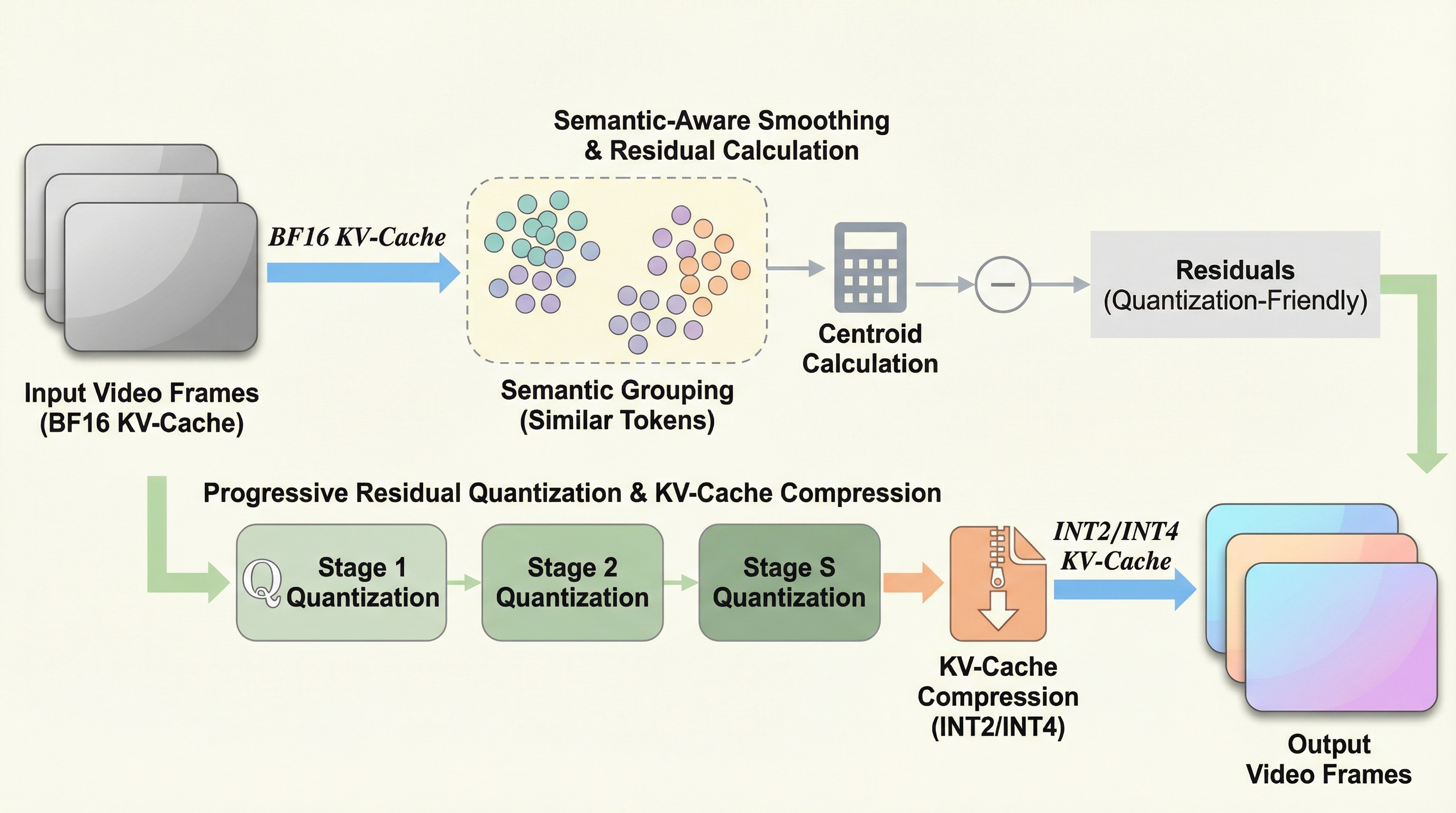
自己回帰型動画生成モデルにおいて、生成時間の経過とともに線形増大し、GPUメモリを占有して長時間生成を阻害する「KVキャッシュ」の肥大化問題を、システムとアルゴリズムの両面から解決する新しいフレームワークを提案しました。
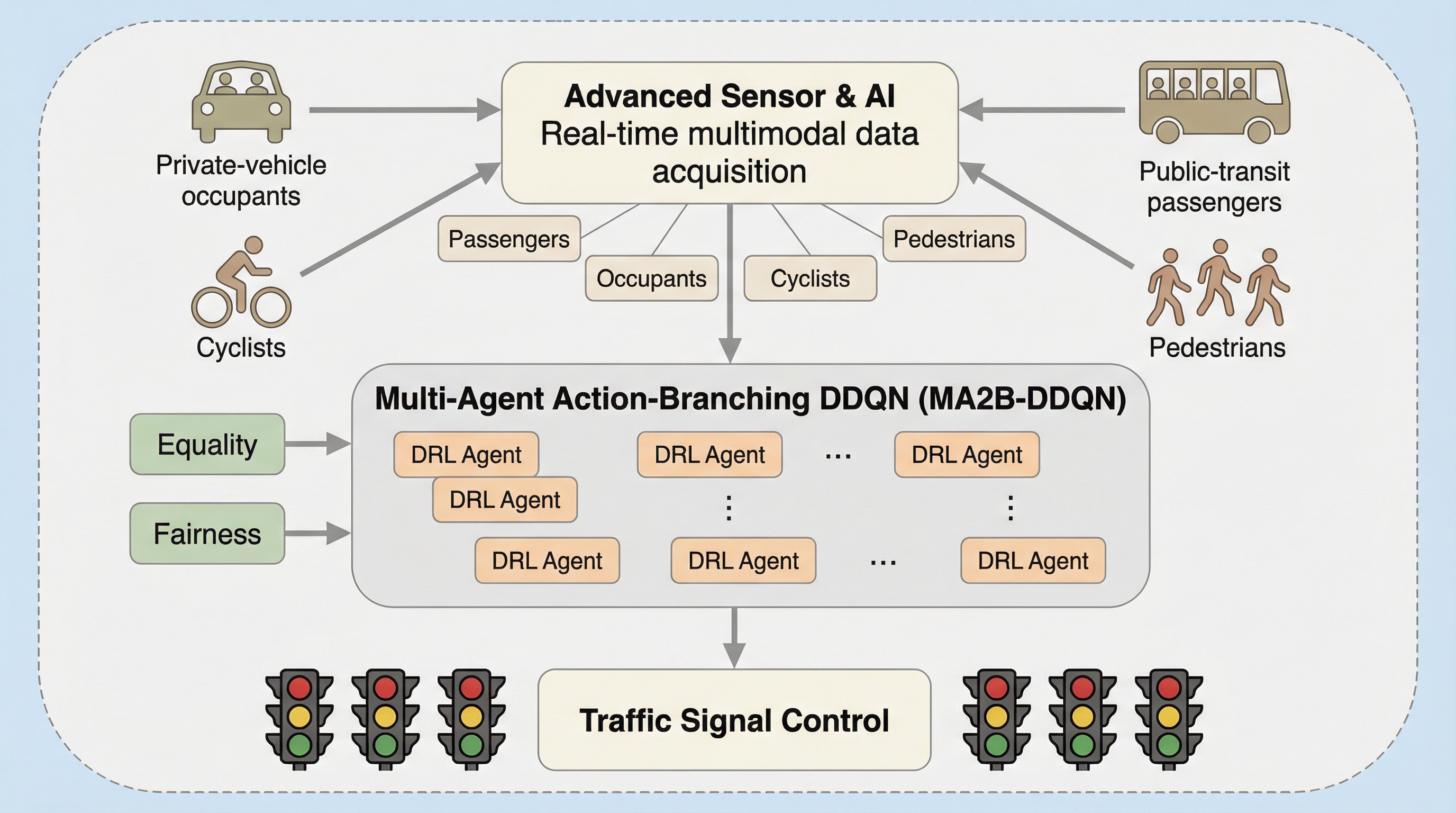
従来の車両台数や待ち時間を優先する「車両中心」の信号制御から、歩行者や公共交通機関の利用者を含むすべての移動者の公平性を最適化する「人間中心」のフレームワーク「MA2B-DDQN」を提案し、都市交通における公平性と持続可能性の両立を目指しました。
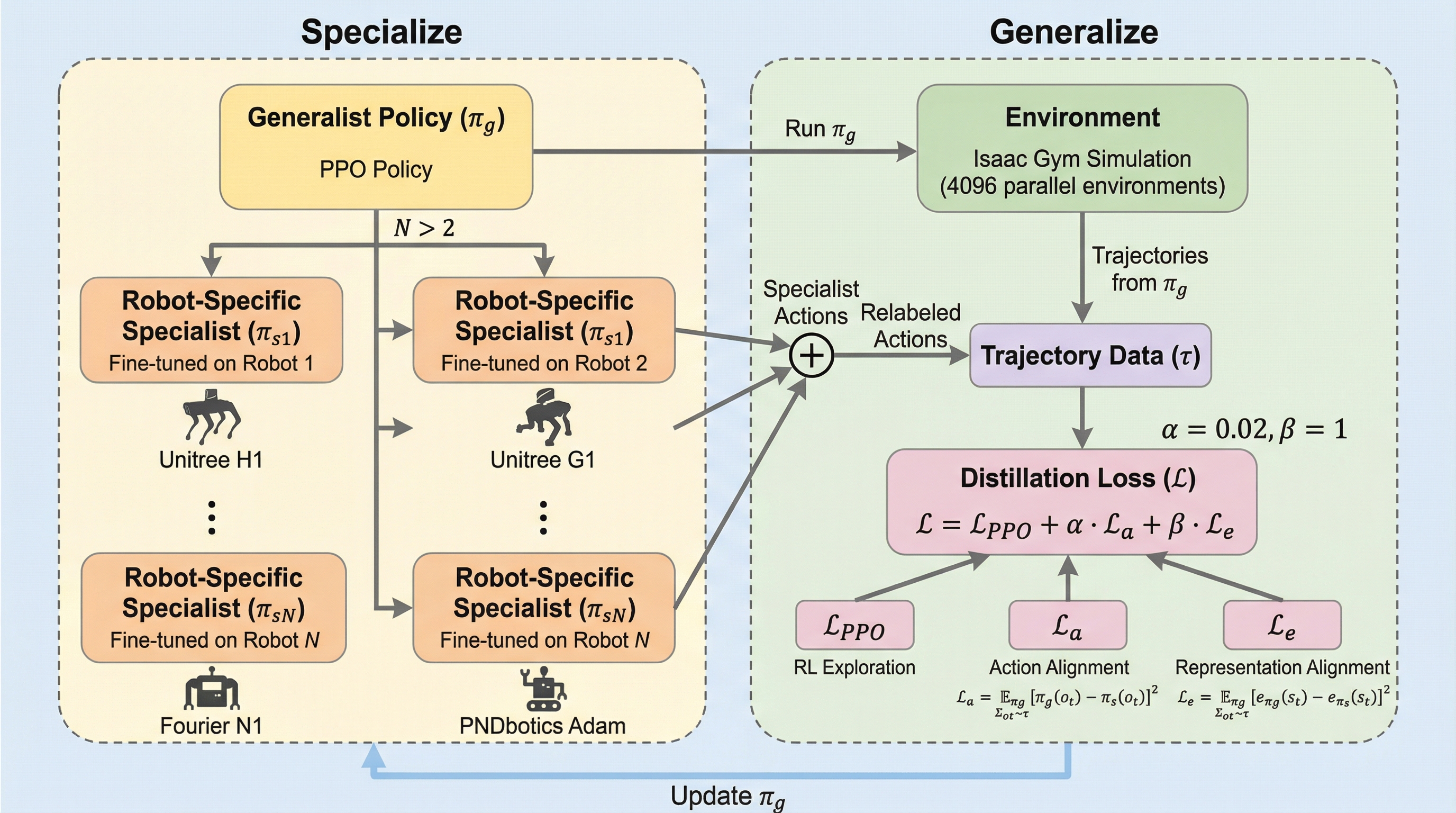
本研究は、構造の異なる複数のヒューマノイドを単一のポリシーで制御する学習フレームワーク「EAGLE」を開発し、歩行だけでなく、しゃがむ、傾くといった多様な全身動作を、ロボットごとの報酬調整なしで実現した。
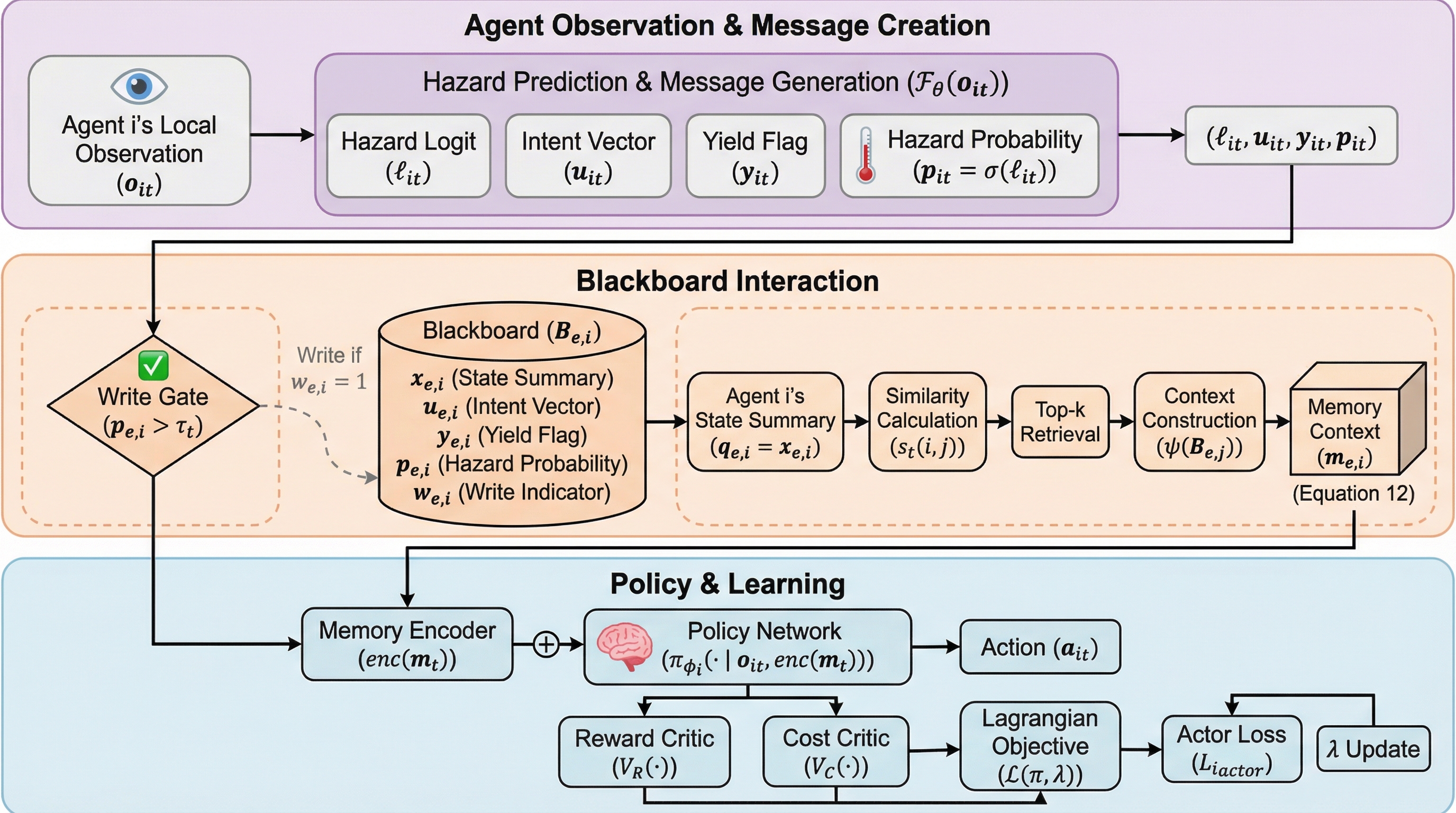
マルチエージェント強化学習(MARL)において、報酬の最大化と安全制約の遵守を両立させることは極めて困難な課題である。本研究で提案された「Co2PO」は、エージェントがリスクを事前に予測し、必要な時だけ情報を共有する「選択的かつリスク認識型の協調」を導入することで、この問題を解決する。