Seg-MoE: 時系列予測のためのセグメント単位の混合エキスパートモデル
従来の時系列予測向け混合エキスパート(MoE)モデルは、各時間ステップを独立して処理するトークン単位のルーティングを採用していたが、データの連続性や局所的な構造を十分に活用できていないという課題があった。
TL;DR(結論)
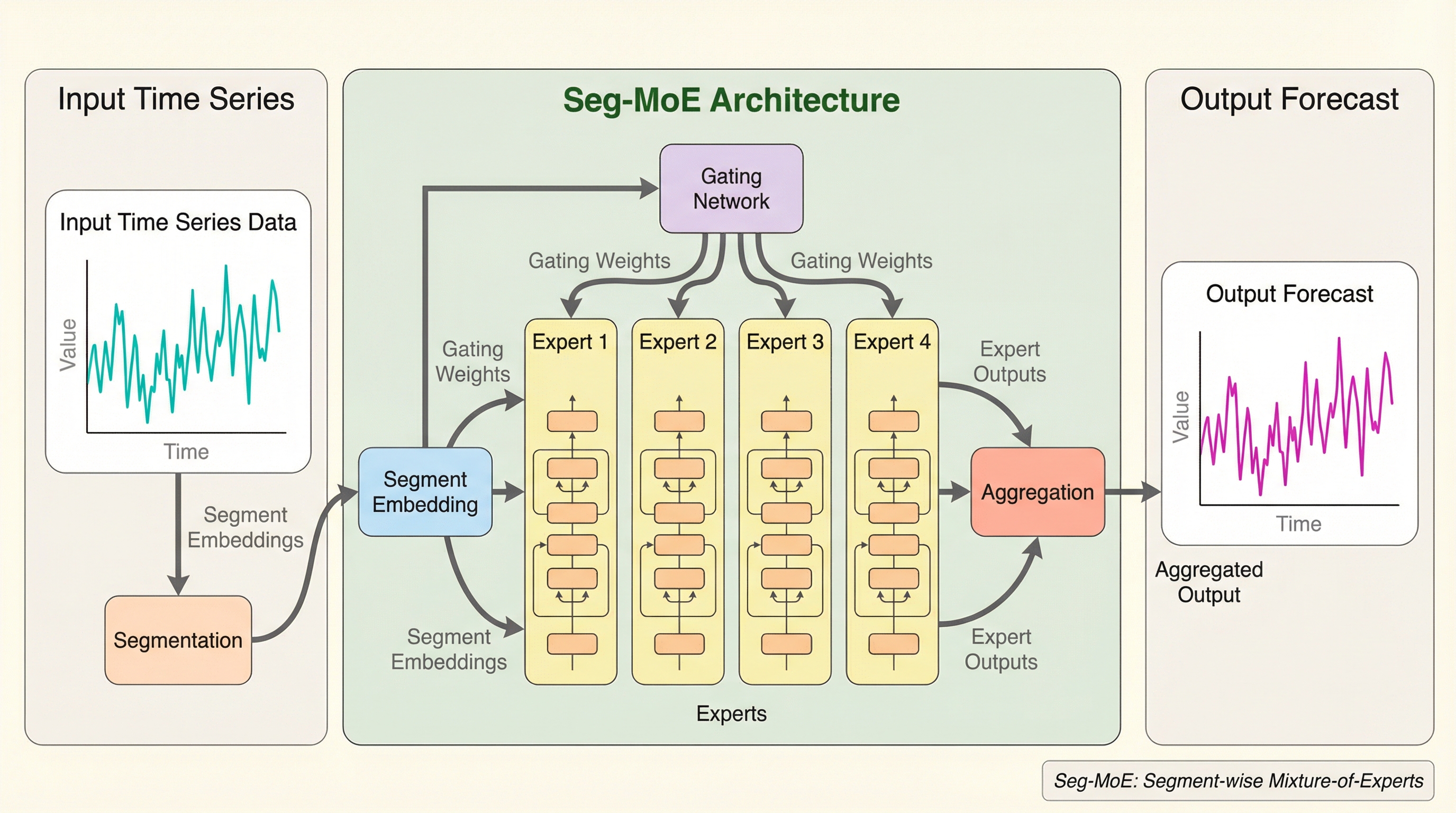
従来の時系列予測向け混合エキスパート(MoE)モデルは、各時間ステップを独立して処理するトークン単位のルーティングを採用していたが、データの連続性や局所的な構造を十分に活用できていないという課題があった。 本研究で提案されたSeg-MoEは、連続する時間ステップをセグメントとしてまとめ、ユニット単位でエキスパートに割り当てることで、セグメント内の相互作用を直接モデル化し、時系列特有のパターンを効率的に捉える。 多変量の長期予測ベンチマークにおいて、Seg-MoEは従来の密なTransformerやトークン単位のMoEモデルを上回る精度を達成し、セグメントレベルのルーティングが予測精度の向上に不可欠な要素であることを実証した。
なぜこの問題か
時系列予測は、金融、エネルギー管理、ヘルスケア、気候モデリングなど、多くの分野において意思決定を支える重要なタスクである。近年、Transformerベースのモデルが長期予測の精度向上において大きな進歩を遂げているが、これらのモデルは密なアーキテクチャであるため、シーケンスが長くなるにつれて計算コストとメモリ使用量が急増するという課題を抱えている。特にアテンション・メカニズムはシーケンス長に対して二次の計算複雑性を持ち、長期的なパターンをモデル化する際に効率性のボトルネックとなる。このスケーリングの問題を解決するために、自然言語処理の分野で成功を収めている混合エキスパート(MoE)レイヤーの導入が検討され始めている。 MoEは、入力ごとにモデルパラメータのサブセット(エキスパート)のみを動的に活性化させることで、計算コストを抑えつつモデルの容量を拡大できる手法である。しかし、既存の時系列予測向けMoEモデルの多くは、言語モデルから継承したトークン単位のルーティングに依存している。これは各時間ステップを独立してエキスパートに割り当てる方式であるが、時系列データが持つ自然な局所性や連続性を無視してしまう可能性がある。…
核心:何を提案したのか
本研究では、時系列データのための新しい疎なMoE設計である「Seg-MoE」を提案している。Seg-MoEの最大の特徴は、従来のトークン単位のルーティングから脱却し、セグメント単位のルーティングと処理を導入した点にある。具体的には、入力シーケンスを重複しない連続した時間ステップのセグメントに再構成し、それらを一つのユニットとしてエキスパートに割り当てる。これにより、各エキスパートはセグメント内の相互作用を直接モデル化できるようになり、時系列データに内在する時間的パターンと自然に整合させることが可能になる。 この設計は、時系列のパターンがしばしば局所的かつ構成的であるという「帰納バイアス」に基づいている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related