深層学習におけるトレーニングメモリ:メカニズム、証拠、および測定のギャップ
深層学習のトレーニングプロセスは、現在のパラメータとミニバッチのみに依存するメモリレスな過程ではなく、過去の勾配履歴、データの提示順序、非凸な損失関数上の経路、外部バッファ、および教師モデルの統計量といった多層的な「トレーニングメモリ」に強く依存して進行する。
TL;DR(結論)
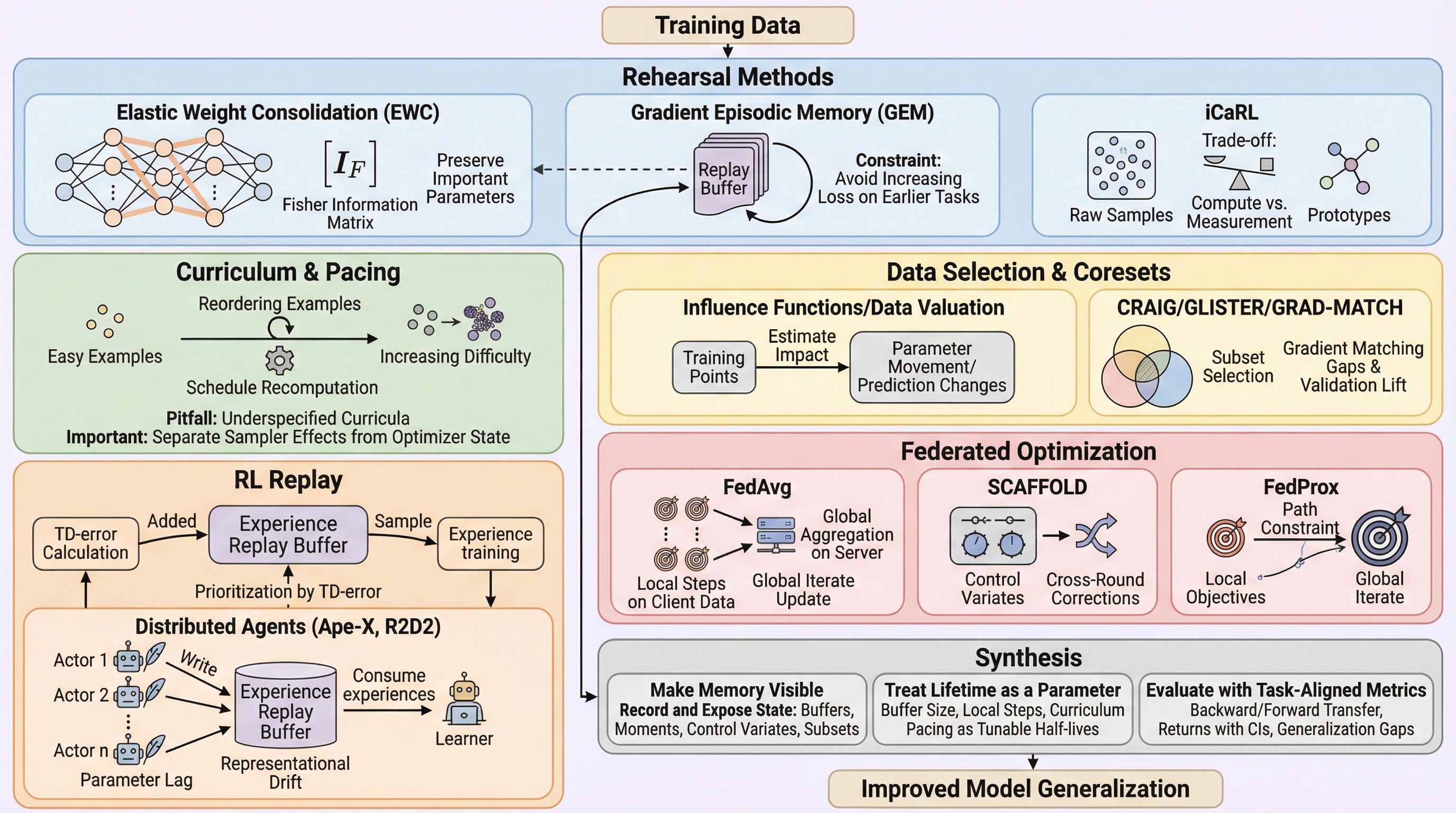
深層学習のトレーニングプロセスは、現在のパラメータとミニバッチのみに依存するメモリレスな過程ではなく、過去の勾配履歴、データの提示順序、非凸な損失関数上の経路、外部バッファ、および教師モデルの統計量といった多層的な「トレーニングメモリ」に強く依存して進行する。 本研究では、これらのメモリを「発生源(Source)」「持続期間(Lifetime)」「可視性(Visibility)」という3つの主要な軸で整理する新しい分類法を提案し、オプティマイザのバッファやデータのシャッフル順序が最終的な解の性質や汎化性能に与える影響を体系的に整理した。 さらに、メモリの影響を定量化するための因果的介入プロトコルと、再現性を担保するための報告チェックリストや監査アーティファクト(順序ハッシュやチェックサムなど)を導入することで、これまでブラックボックスであった学習プロセスの透明性と属性化を可能にする標準的な枠組みを提示している。
なぜこの問題か
現代の深層ニューラルネットワークの学習において、多くの研究者や開発者はそのプロセスを単純なマルコフ過程として扱いがちである。つまり、次の学習ステップの状態は現在の重みと入力されたミニバッチのみによって決定されるという前提に立っている。しかし、実際には過去の勾配の履歴やデータの提示順序が複雑に絡み合っており、これらがモデルの最終的な性能や汎化性能に決定的な影響を及ぼしていることが経験的に知られている。この「トレーニングメモリ」の存在は無視できないものであるにもかかわらず、既存の研究報告では最終的な精度や損失の値のみが強調され、学習過程でどのような内部状態が保持され、それが結果にどう寄与したかという詳細なプロトコルが不透明なままにされていることが多い。例えば、学習の特定のフェーズ間でオプティマイザのバッファがリセットされたのか、あるいはデータの順序付けポリシーがどのように設定されていたのかといった情報は、実験の再現性や異なる手法間の公平な比較を著しく阻害する要因となっている。…
核心:何を提案したのか
本研究は、深層学習におけるトレーニングメモリのメカニズムと証拠を統合し、測定のギャップを埋めるための包括的なフレームワークを提案している。具体的には、メモリを「発生源(Source)」「持続期間(Lifetime)」「可視性(Visibility)」という3つの主要な軸で整理する新しい分類法を導入した。発生源としては、オプティマイザの内部状態(S1)、サンプラーによるデータの順序(S2)、パラメータの移動経路(S3)、建築的な外部メモリ(S4)、そして教師モデルなどのメタ状態(S5)の5つを定義している。これにより、これまで曖昧だった「学習の履歴」という概念を、具体的なコンポーネントに分解して議論することが可能になった。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related