大規模言語モデルにおける合成的推論のための再帰的概念進化
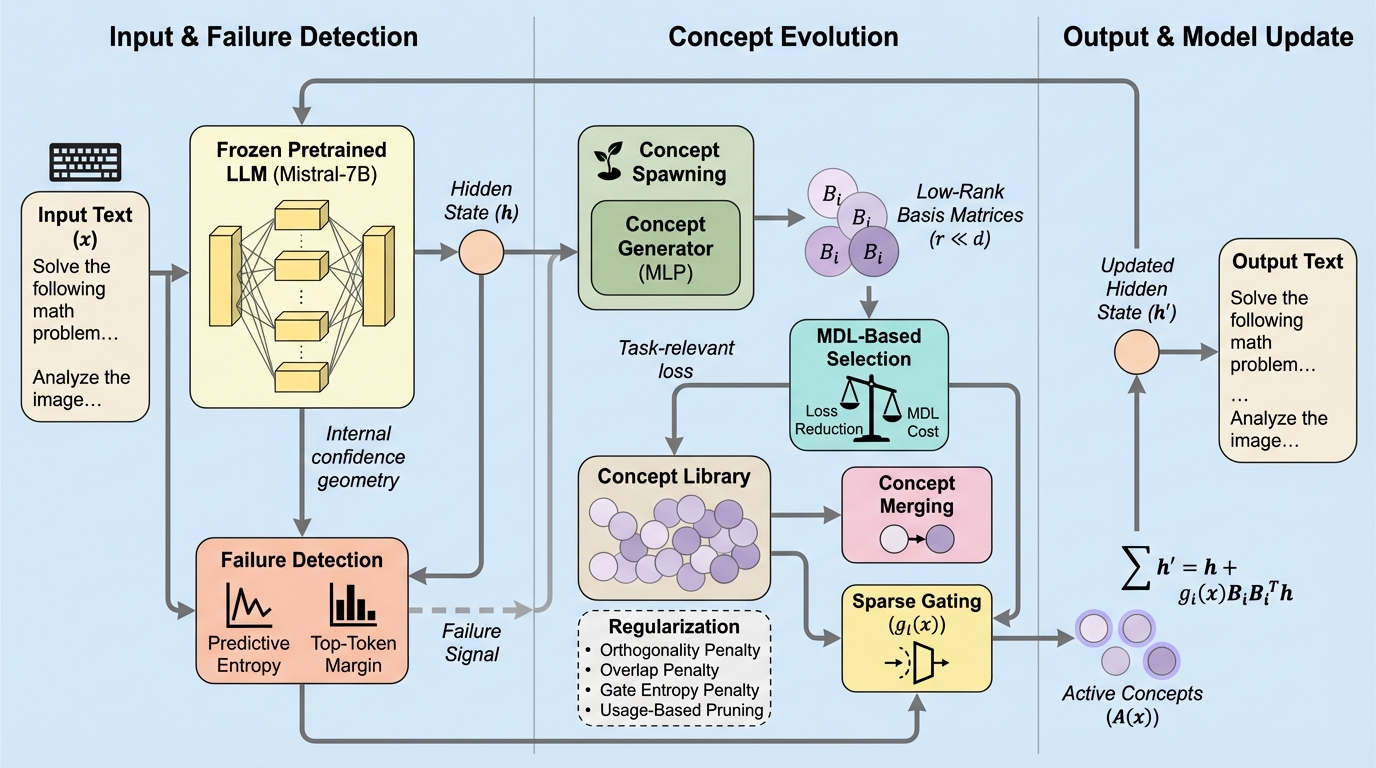
大規模言語モデルは多くの推論課題で強い一方、推論中に新しい抽象を組み立てる合成的推論では、内部表現空間が固定されていること自体がボトルネックになり、探索を増やしても精度が崩れやすいと位置づけられています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルは多くの推論課題で強い一方、推論中に新しい抽象を組み立てる合成的推論では、内部表現空間が固定されていること自体がボトルネックになり、探索を増やしても精度が崩れやすいと位置づけられています。
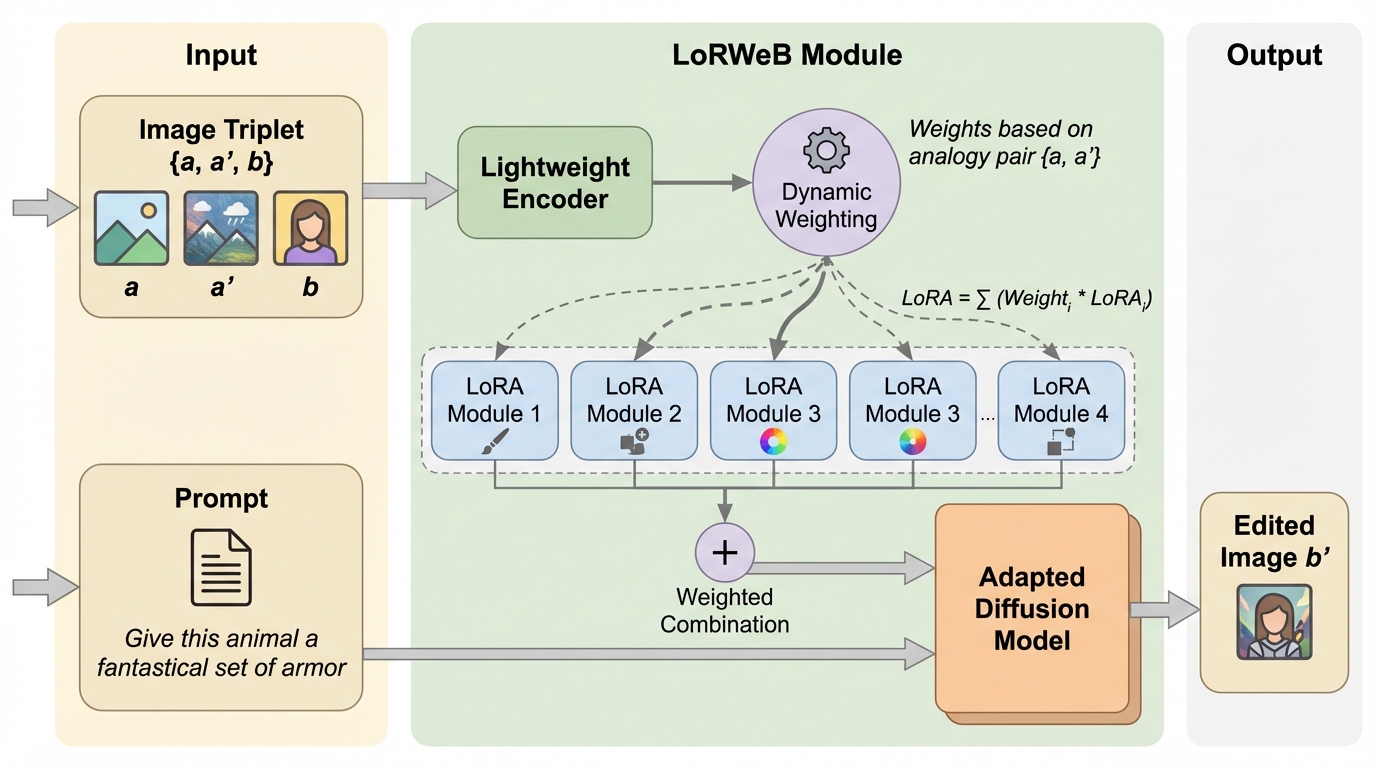
言葉では説明しにくい編集でも、見本の「前→後」画像から変換を読み取り別画像へ移す視覚アナロジーは有用ですが、単一のLoRAに多様な変換を詰め込む設計は未知の変換への一般化を妨げやすいです。 / LoRWeBは、複数のLoRAを「変換の部品」として学習可能な基底にしておき、入力された三つ組(a, a′, b)を手がかりに軽量エンコーダが混合係数を推定して、推論時に1つのMixed LoRAとして動的に合成して注入します。 / 包括的な評価により最先端の性能が示され、学習時に見ていない視覚変換への一般化も大きく改善したと報告されており、LoRAを基底分解して混ぜる方針が柔軟な例示ベース編集に有望だと示唆されます。
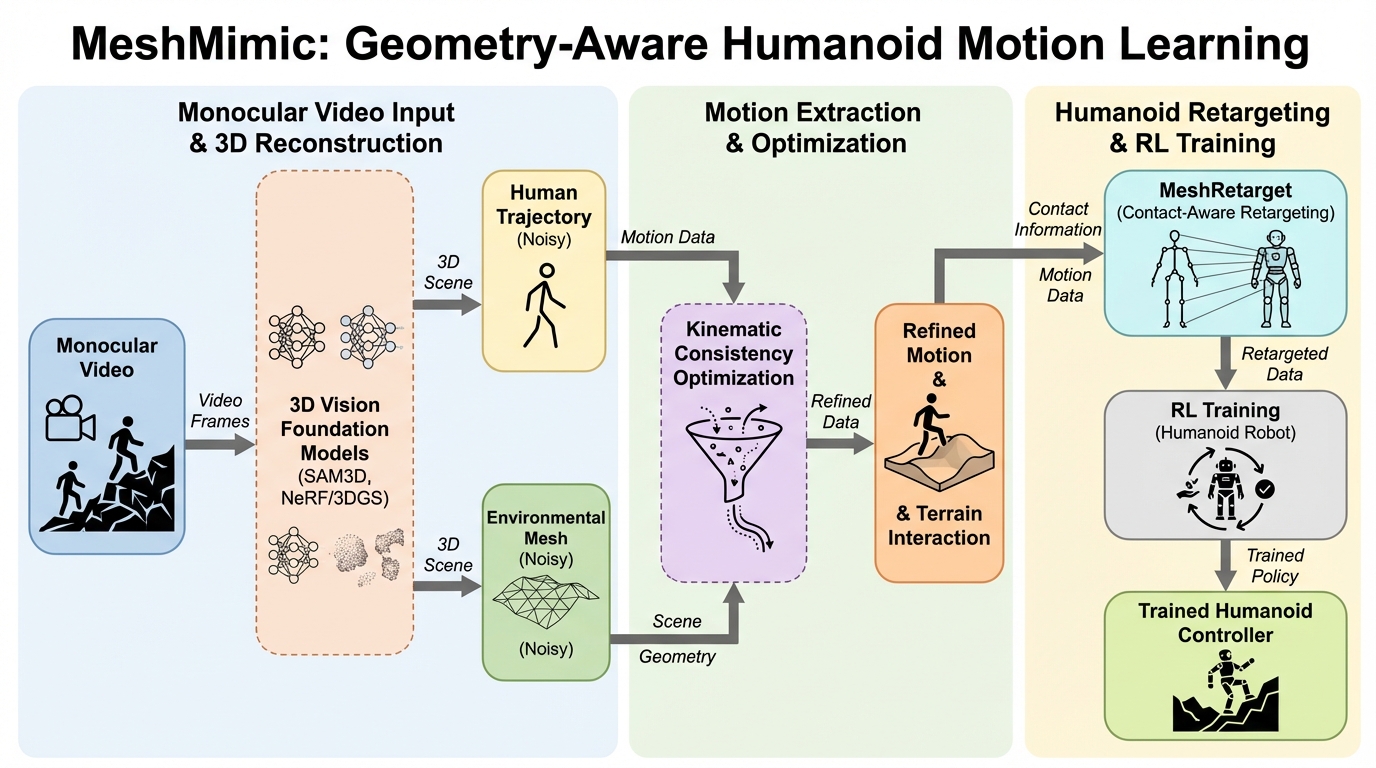
MeshMimicは、単眼の動画から人の動きだけを取り出すのではなく、その動きが成立している地形や物体の三次元形状も同時に復元し、動作と地形の相互作用を結び付けた参照データとしてヒューマノイドの学習に使う枠組みです。
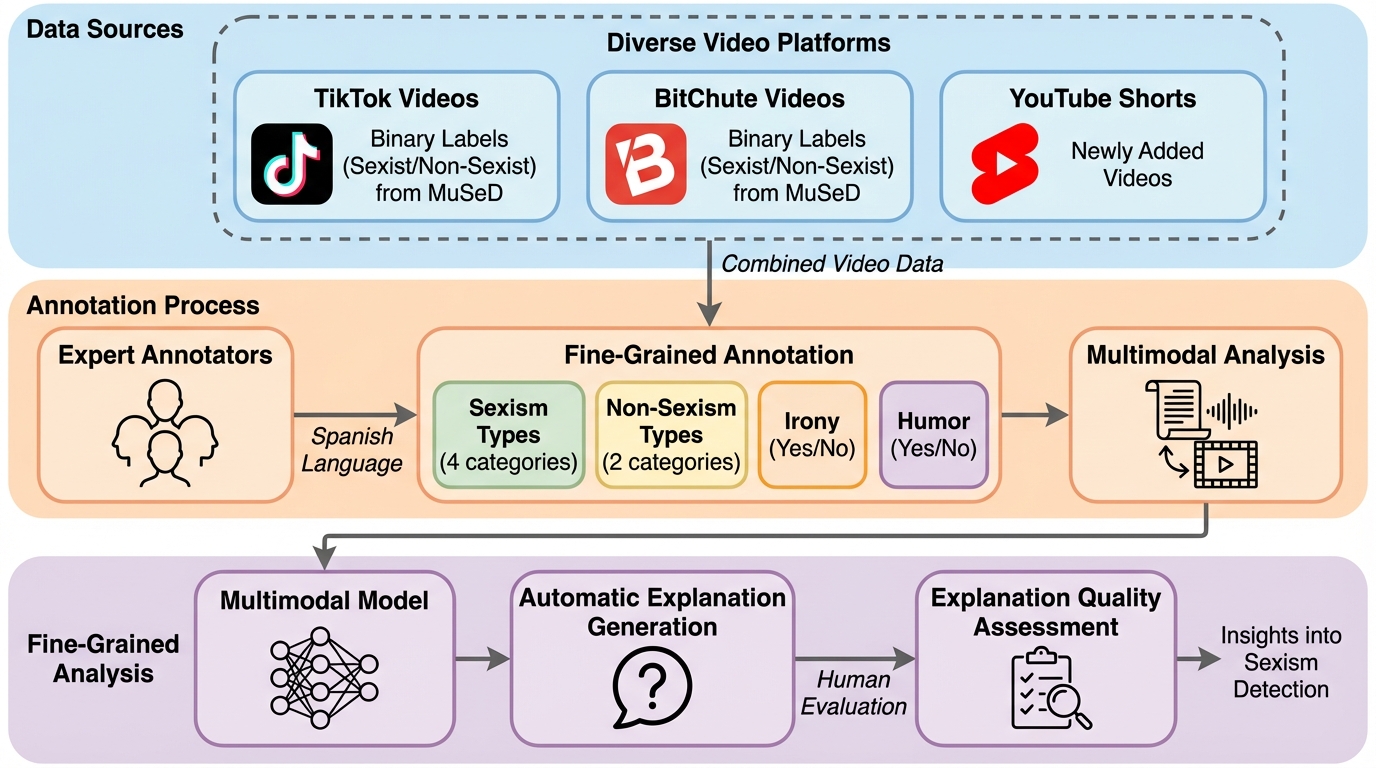
オンライン上の性差別は形が複数あり、性差別か非性差別かの二値だけでは、文脈に依存する微妙で暗黙的な表現が見落とされやすく、説明がない自動フラグは透明性の面でも課題になり得ます。 / そこで、スペイン語のソーシャルメディア動画を対象に、二値注釈と詳細注釈を併せ持つFineMuSeと、性差別・非性差別に加えて皮肉とユーモアも扱える三層の階層タクソノミーを提示し、二値検出と詳細検出の両方で多数の大規模言語モデルを評価しています。 / その結果、マルチモーダル大規模言語モデルはニュアンスのある性差別の同定で人手注釈者と競争的な性能を示す一方、視覚的手掛かりで伝わる「複数タイプの併発」を捉える点には難しさが残ると報告されています。
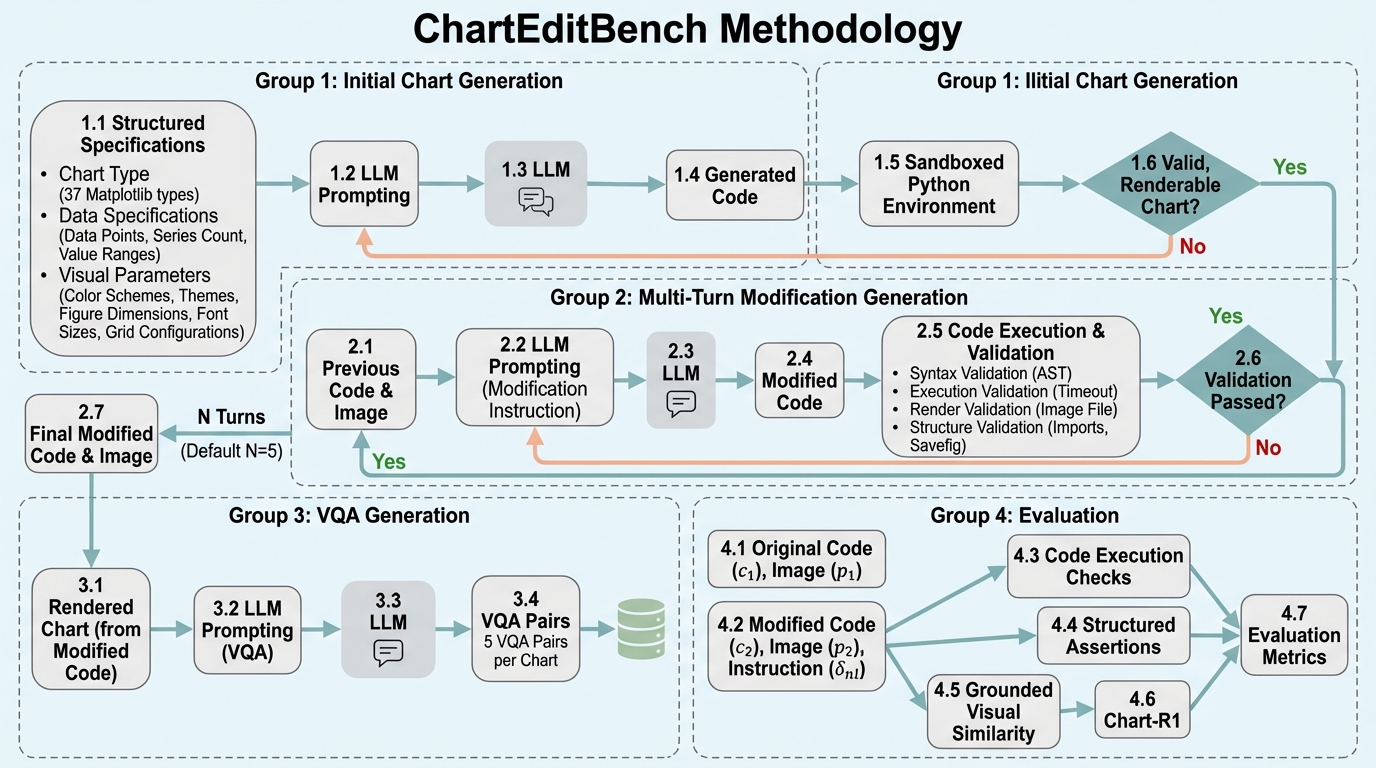
マルチモーダル言語モデルは単発のチャート生成では高い性能を示しやすい一方で、実務のように既存の図を何度も直しながら仕上げる場面で必要な「共通理解の維持」と「過去の編集の追跡」を、長い会話の中で安定して行えるかは十分に測れていません。
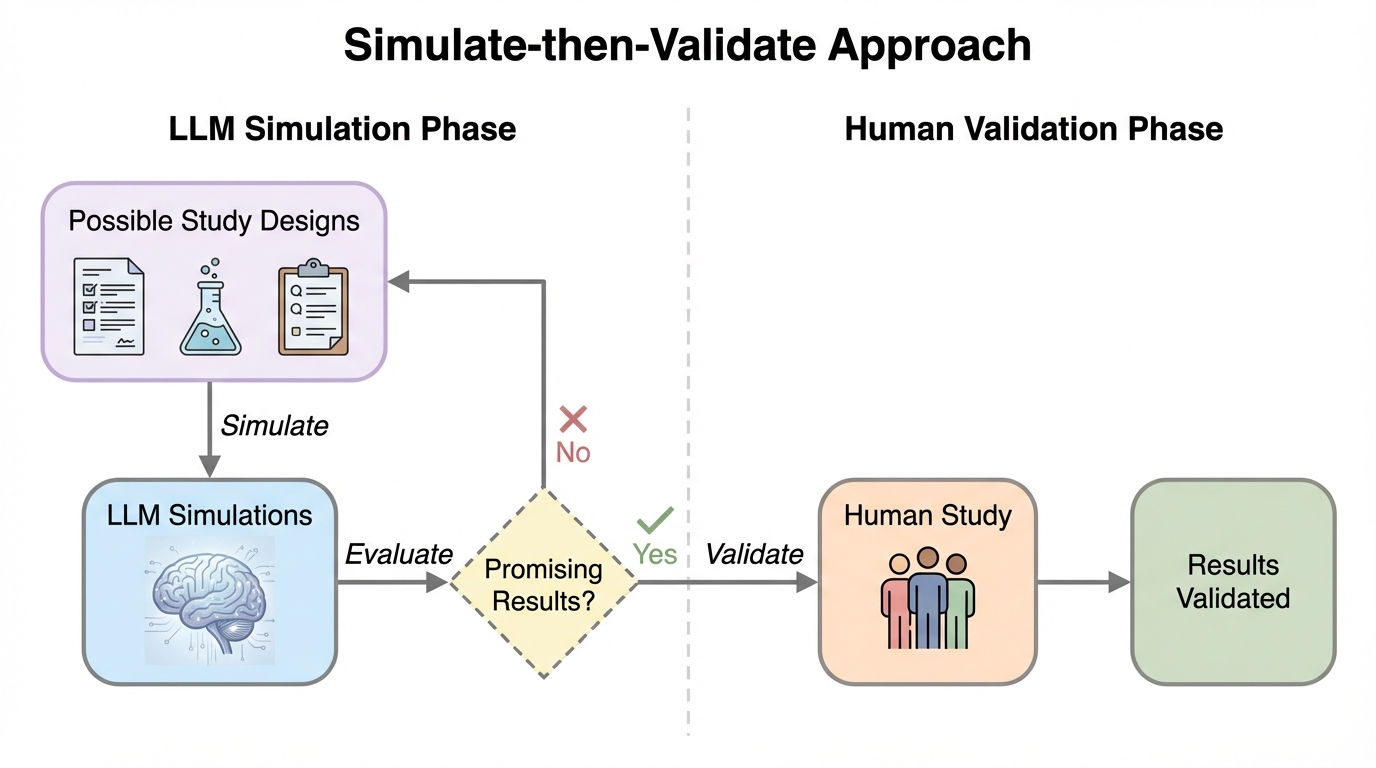
社会科学の調査や実験でLLMを「合成参加者」として使う動きが広がっていますが、その出力を人間行動の証拠として扱える条件は十分に整理されていません。 / 本論文は、プロンプト工夫や微調整などで人間と入れ替え可能だと示そうとする方法と、人間データを少量集めて統計的にずれを調整する方法を対比し、探索的研究と確認的研究で求められる前提の違いを明確にしています。 / 統計的な調整は明示的な仮定のもとで妥当性を保ちながら因果効果推定を精密化し得ますが、両方法とも「LLMが対象集団をどれだけ近似できるか」に制約され、置き換えだけに注目すると見落とす活用機会があると論じています。
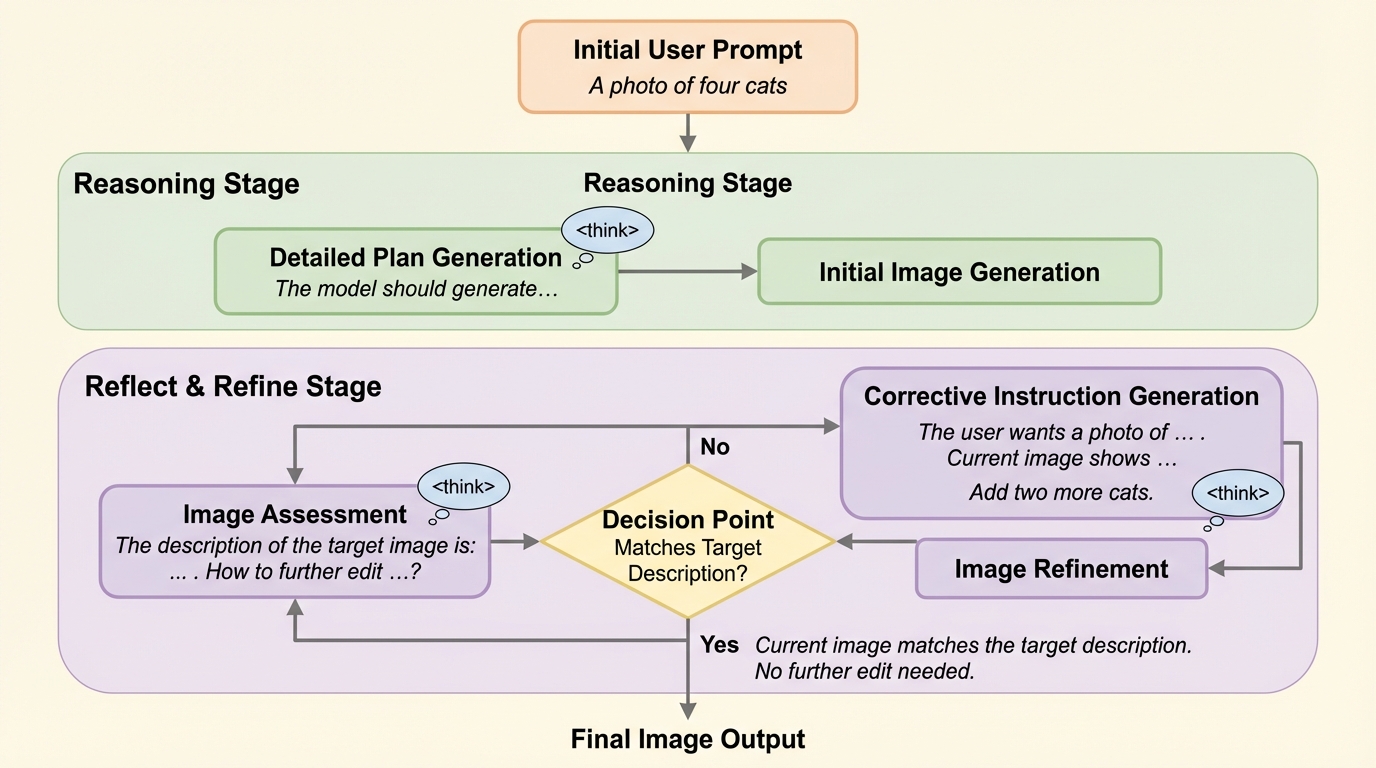
マルチモーダルモデルは、画像の「生成」を伸ばすと「理解」が落ちたり、その逆が起きたりする同時改善の難しさがあり、原因として学習目標の違いがモデル容量の競合を生みうる点が整理されています。 / この論文は単発の画像生成を、意図を推論して下書きを作り、出来栄えを自己評価し、修正指示で編集していく多段の手続きへ組み替えるReason-Reflect-Refine(R3)を提案しています。 / 最終画像の品質に基づく結果志向の報酬で一連のループを学習させ、GenEval++で生成指示追従を強化しつつ、生成内容に結び付いた理解評価(例としてカウントなど)も改善したと報告されています。
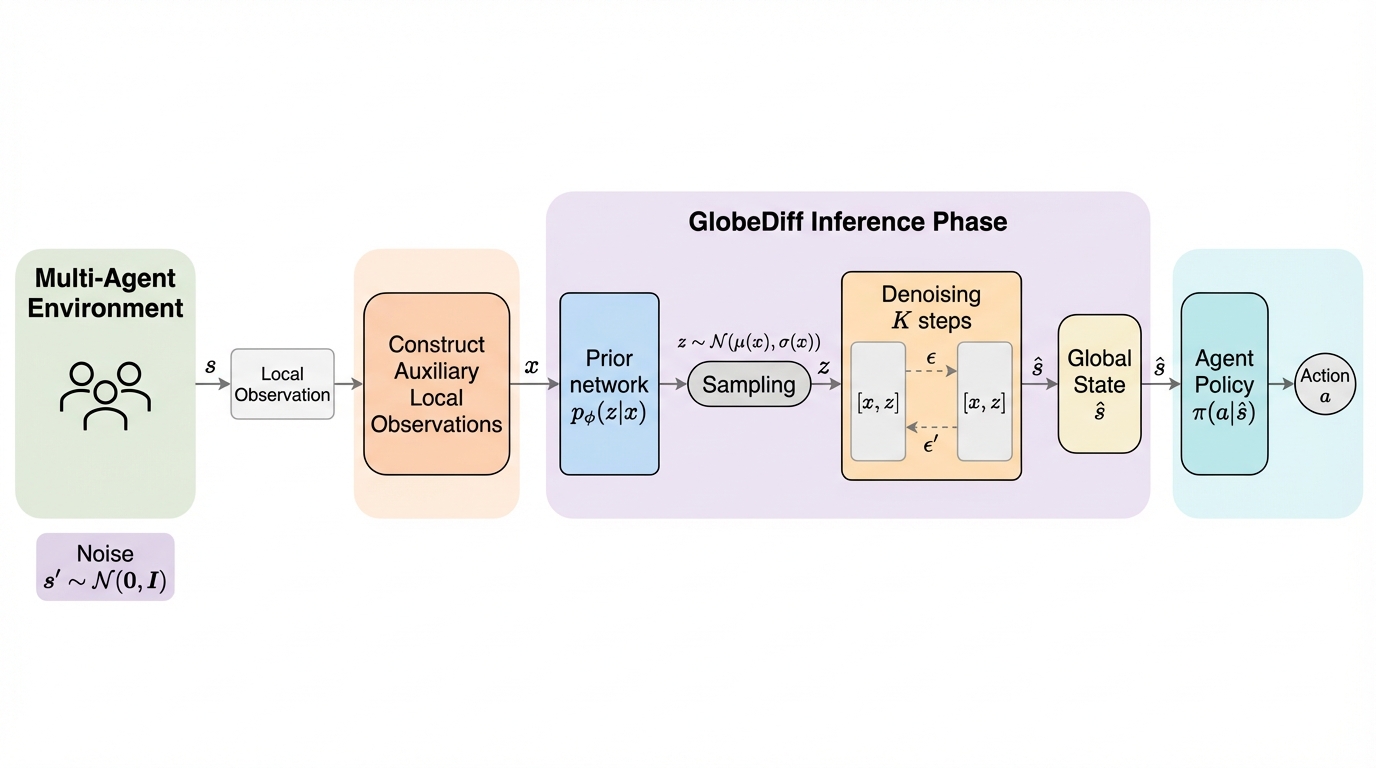
部分観測の協調タスクでは、同じローカル観測でも整合するグローバル状態が複数あり得るため、最もありそうな状態を1つに決め打つ推定は不確実性を潰してモード崩壊を起こしやすく、意思決定の不安定さにつながります。
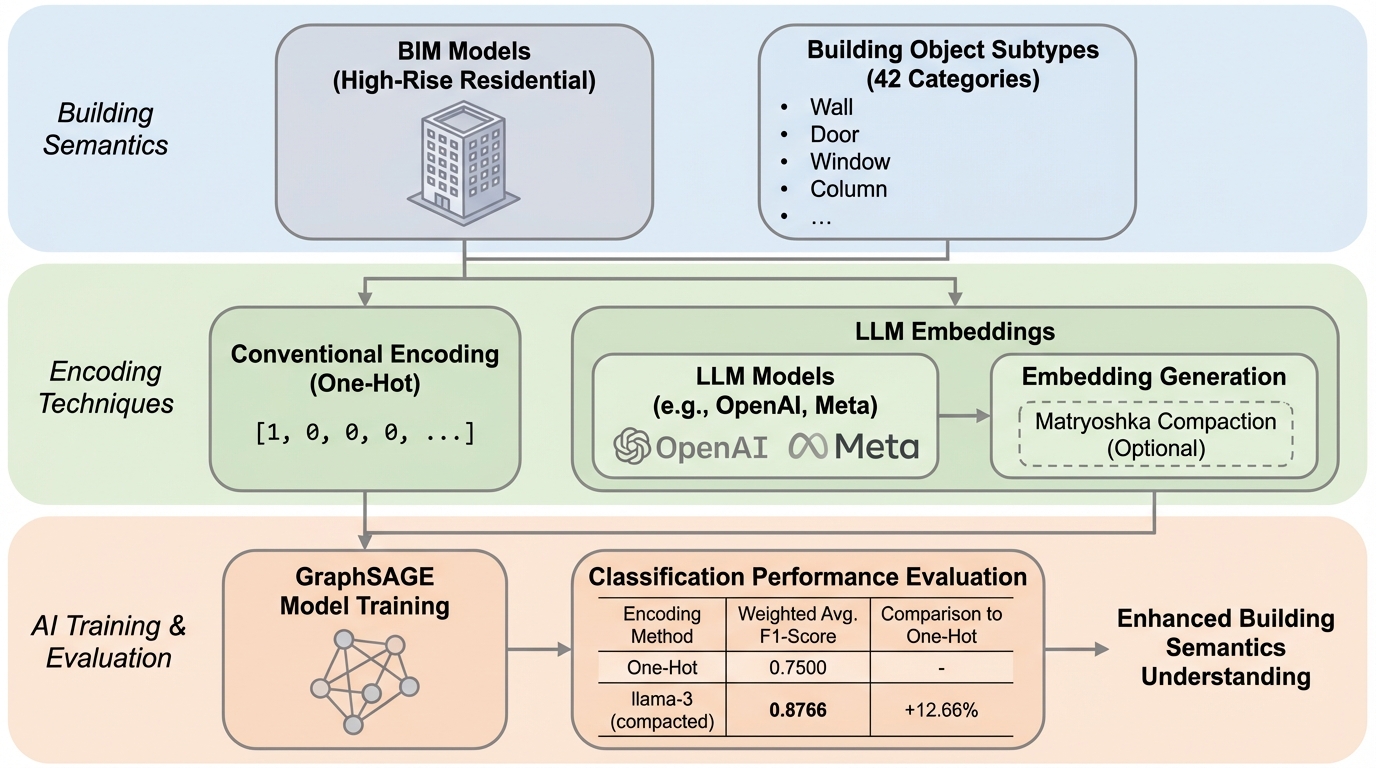
近い概念が多い建物オブジェクトのサブタイプ分類では、ワンホットのように全クラスを等距離として扱う符号化では、微妙な関係性が落ちて意味理解が進みにくいです。 / クラス名をOpenAIやMetaの大規模言語モデル埋め込みに置き換え、GraphSAGEの出力を同じ次元のベクトルとして学習し、コサイン類似度にもとづく損失で「正解ラベルの埋め込み」に近づけます。 / 高層住宅BIM 5件で42サブタイプを評価したところ、LLM埋め込みの符号化がワンホットを上回り、特にllama-3の1,024次元圧縮版で加重平均F1が0.8766(ワンホットは0.8475)でした。

整列済み言語モデルは、有害なデータを含まない良性タスクで微調整しても、開発者に敵対的意図がなくても、安全ガードレールが予測しにくい形で劣化し得ると説明されています。 / 「安全に重要な方向と直交する更新なら安全」という直観は、勾配降下の時間発展の中で直交性が崩れるため当てにならず、損失地形の曲率が軌道を整列に敏感な低次元部分空間へ押し込む仕組みが定式化されています。 / 3つの幾何学的性質からなるAlignment Instability Conditionの下で、整列損失が訓練時間の4乗で増えるスケーリング則が導かれ、一次情報だけに依存する安全な微調整観に構造的な見落としがあると示されています。