経験の時代において、言語ベースの試行錯誤は遅れをとる
大規模言語モデル(LLM)は言語タスクには強いものの、記号や空間を扱う未知の非言語タスクでは、膨大なパラメータによる試行錯誤の計算コストが極めて高く、効率的な探索が困難であるという根本的な課題を抱えている。
TL;DR(結論)
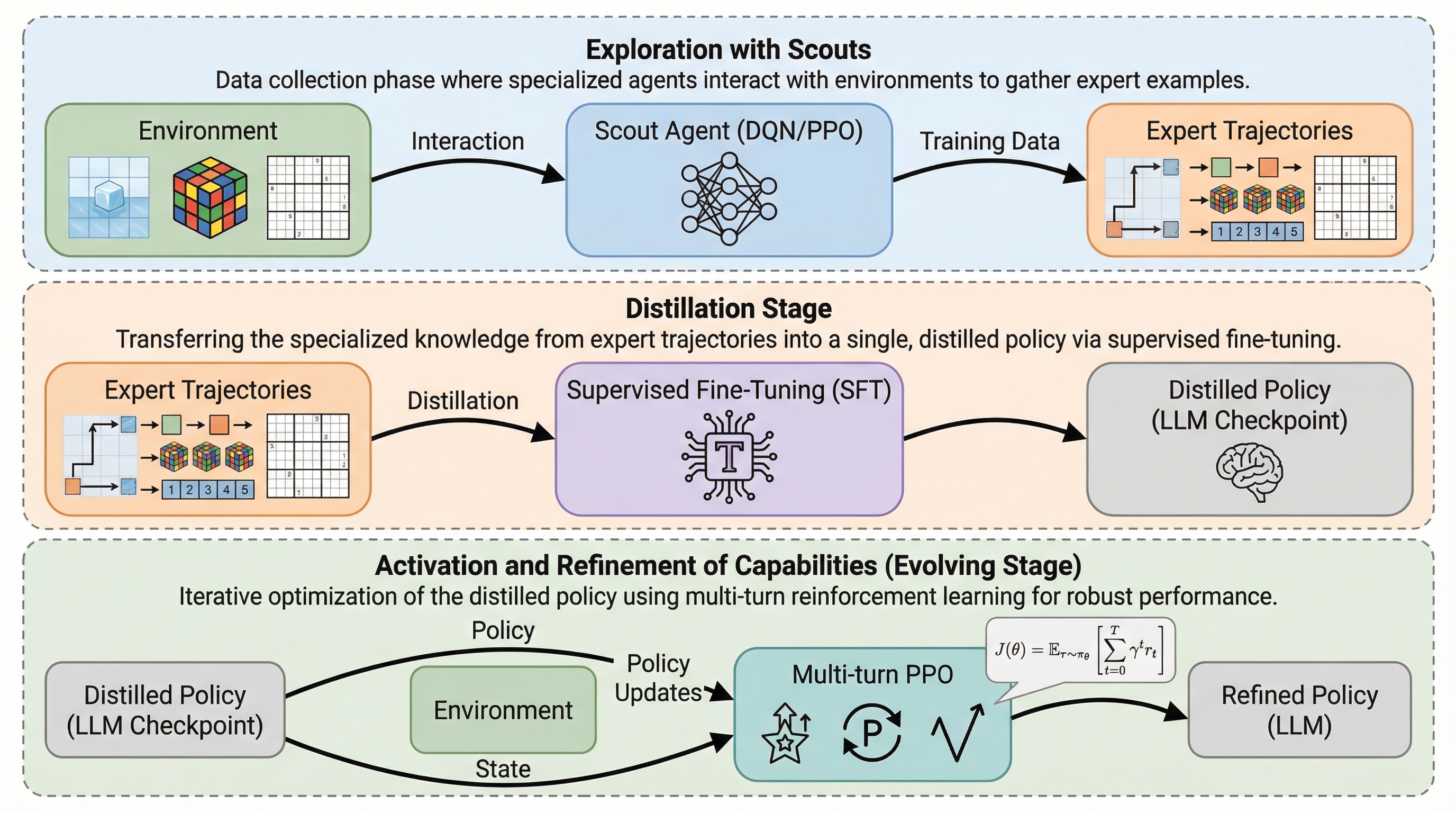
大規模言語モデル(LLM)は言語タスクには強いものの、記号や空間を扱う未知の非言語タスクでは、膨大なパラメータによる試行錯誤の計算コストが極めて高く、効率的な探索が困難であるという根本的な課題を抱えている。 本研究が提案するSCOUTフレームワークは、軽量な「スカウト」モデルに環境動態を高速かつ大規模に探索させ、得られた成功軌跡をテキスト化してLLMに教師あり微調整(SFT)と多段階強化学習(RL)を施すことで、探索と活用のプロセスを完全に分離する。 実証実験では、Qwen2.5-3B-Instructを用いたSCOUTが平均スコア0.86を記録し、Gemini-2.5-Proなどの強力な商用モデルを大幅に上回る性能を示しただけでなく、GPUの消費時間を約60%削減することに成功し、未知の領域における高い適応能力と効率性を証明した。
なぜこの問題か
大規模言語モデルは、高品質なテキストコーパスを用いた大規模な事前学習によって、創造的な執筆や要約、推論、言語ベースのエージェントタスクにおいて優れたゼロショット一般化能力を獲得している。しかし、記号的な状態に基づくタスクや空間的な把握が求められるタスク、あるいは複雑な長期スパンのタスクなど、事前学習の分布に含まれない未知の非言語環境に配備された場合、その適用能力は著しく制限される。現実世界は無限の複雑さを持っており、事前学習ですべてのタスクを網羅することは困難であるため、モデルは事前学習済みの知識を直接利用するのではなく、環境の動態を一から内面化する必要に迫られる。既存の研究では、この性能の差は、LLMが自然言語ベースの状態タスクと比較して、記号的な状態ベースのタスクに不慣れであることに起因すると分析されている。 本研究では、LLMエージェントがこれらの新しいタスクを習得できない根本的な原因として、2つのミスマッチを指摘している。第一に、アクション空間と生成空間のミスマッチである。トークンの生成には数十億のパラメータを介したフォワードパスが必要であり、探索と活用の両面で効率が低い。…
核心:何を提案したのか
本研究は、LLMエージェントの「世界知識の活用」と、軽量なモデルによる「探索の効率性」を調和させる新しいエージェントフレームワーク「SCOUT(Sub-Scale Collaboration On Unseen Tasks)」を提案している。このフレームワークの核心的な洞察は、LLMエージェントが行う重い探索フェーズを、活用フェーズから切り離すことにある。具体的には、多層パーセプトロン(MLP)や畳み込みニューラルネットワーク(CNN)などの軽量なニューラルネットワークを「スカウト」として採用し、LLMの代わりに環境の動態を調査させる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related