経験の時代において言語ベースの試行錯誤は遅れをとる
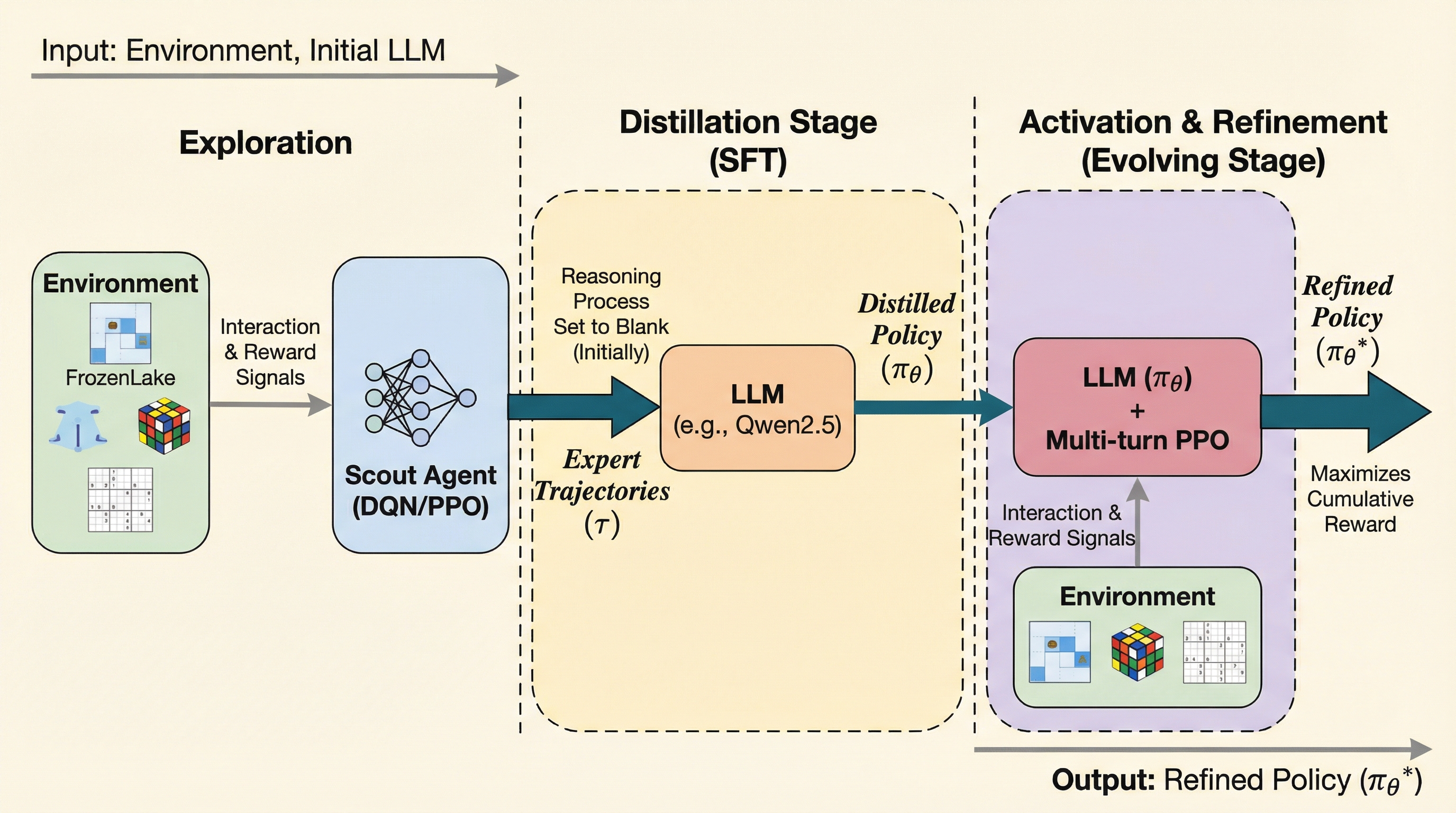
大規模言語モデル(LLM)は言語タスクには強いものの、記号的・空間的な未知のタスクでは膨大なパラメータによる探索コストが障壁となり、試行錯誤の効率が著しく低いという課題がある。 本研究が提案するSCOUTは、軽量なニューラルネットワーク(スカウト)に環境探索を任せて成功軌跡を生成し、それをテキスト化してLLMに蒸留した後、多ターン強化学習で能力を活性化させる新しいフレームワークである。 実証実験では、Qwen2.5-3Bモデルが平均スコア0.86を記録し、Gemini-2.5-Proなどの商用モデルを大幅に上回る性能を示しながら、計算リソースであるGPU時間を約60%削減することに成功した。
TL;DR(結論)
大規模言語モデル(LLM)は言語タスクには強いものの、記号的・空間的な未知のタスクでは膨大なパラメータによる探索コストが障壁となり、試行錯誤の効率が著しく低いという課題がある。 本研究が提案するSCOUTは、軽量なニューラルネットワーク(スカウト)に環境探索を任せて成功軌跡を生成し、それをテキスト化してLLMに蒸留した後、多ターン強化学習で能力を活性化させる新しいフレームワークである。 実証実験では、Qwen2.5-3Bモデルが平均スコア0.86を記録し、Gemini-2.5-Proなどの商用モデルを大幅に上回る性能を示しながら、計算リソースであるGPU時間を約60%削減することに成功した。
なぜこの問題か
大規模言語モデルは、高品質なテキストコーパスを用いた大規模な事前学習により、創造的な執筆や要約、推論、言語ベースのエージェントタスクにおいて優れたゼロショット一般化能力を獲得している。しかし、記号的なタスクや空間的なタスクといった、事前学習の分布に含まれない非言語的な未知の環境に展開された場合、その適用能力は依然として限定的である。先行研究では、この性能のギャップは事前学習の分布とテスト時の分布の不一致に起因するとされているが、本研究では根本的なボトルネックが「探索にかかる法外なコスト」にあることを指摘している。未知のタスクを習得するには広範な試行錯誤が必要であるが、数十億のパラメータを持つ重量級のLLMにとって、高次元のセマンティック空間で試行錯誤を繰り返すことは計算量的に持続不可能である。 具体的には、LLMが1つのトークンを生成するたびに膨大なパラメータを介したフォワードパスが必要であり、探索と活用の両面で効率が極めて低い。また、多くの推論や記号タスクが必要とするアクション空間は低次元で離散的であるにもかかわらず、LLMは3万トークンを超える広大な語彙空間から最適な行動を探索しなければならない。…
核心:何を提案したのか
本研究では、LLMエージェントによる世界知識の活用(Exploitation)と、軽量な「スカウト(Scout)」による探索(Exploration)の効率性を調和させる新しいエージェントフレームワーク「SCOUT(Sub-Scale Collaboration On Unseen Tasks)」を提案した。このフレームワークの鍵となる洞察は、LLMエージェントにとって重荷となる探索フェーズを、知識の活用フェーズから切り離すことにある。具体的には、多層パーセプトロン(MLP)や畳み込みニューラルネットワーク(CNN)などの軽量なニューラルネットワークを「スカウト」として採用し、環境のダイナミクスを高速かつ大規模に調査させる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related