TACLer:効率的な推論のための調整されたカリキュラム強化学習
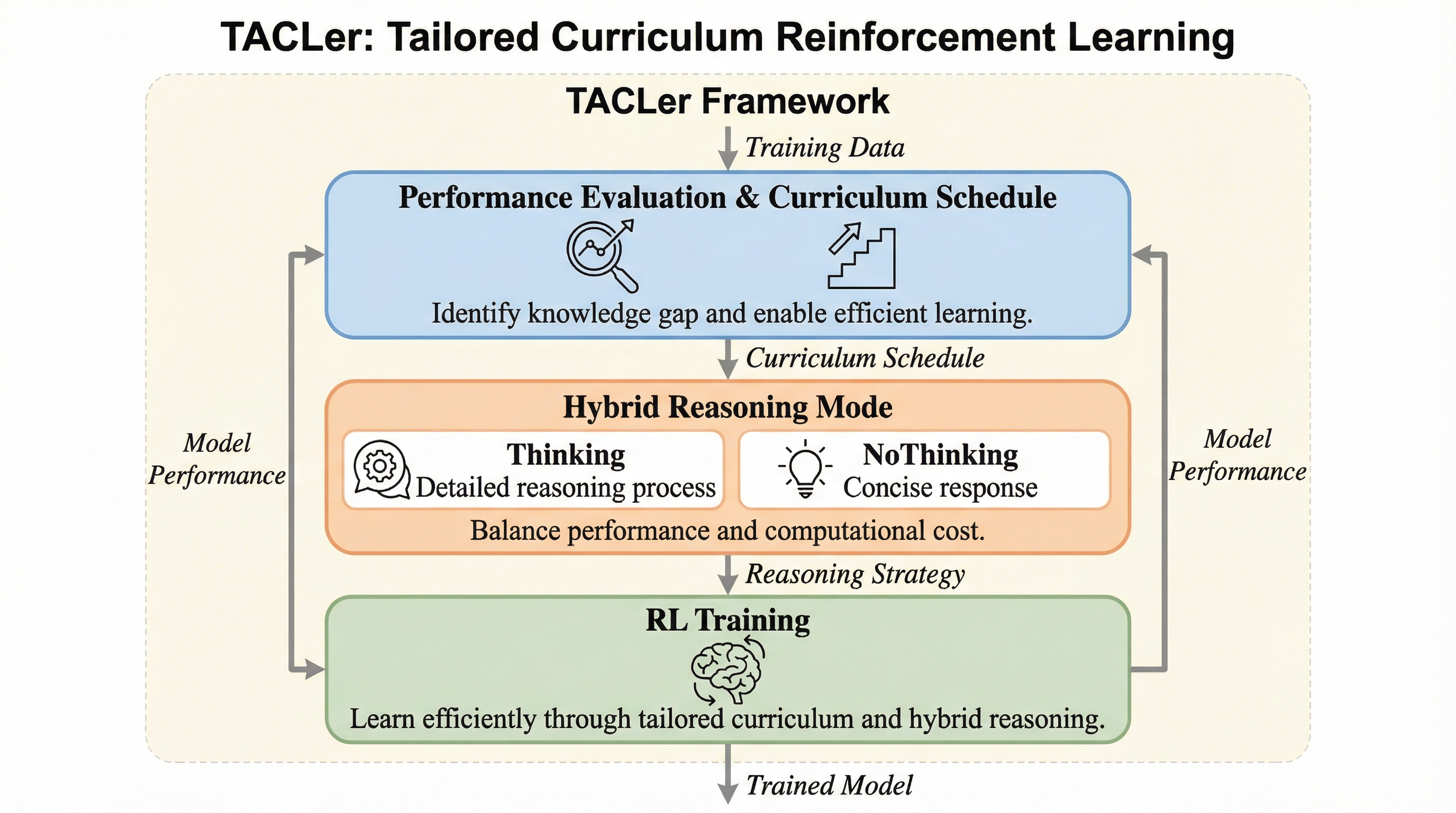
TACLerは、モデルの習熟度に合わせて学習データの難易度を段階的に引き上げる「個別最適化カリキュラム学習」と、詳細な思考と簡潔な回答を使い分ける「ハイブリッド推論モード」を統合した強化学習フレームワークである。
TL;DR(結論)
TACLerは、モデルの習熟度に合わせて学習データの難易度を段階的に引き上げる「個別最適化カリキュラム学習」と、詳細な思考と簡潔な回答を使い分ける「ハイブリッド推論モード」を統合した強化学習フレームワークである。 この手法により、従来の長考型モデルと比較して学習時の計算コストを50%以上削減し、推論時のトークン使用量を42%以上節約しながら、数学的推論タスクにおける正解率をベースモデルから9%以上向上させることに成功した。 実験ではMATH 500やAIMEなどの難関数学ベンチマークにおいて、既存の最先端モデルを上回る精度と効率性を両立しており、ユーザーの目的に応じて推論の深さを制御できる柔軟性と、学習プロセスの圧倒的な効率化を同時に実現している。
なぜこの問題か
大規模言語モデル(LLM)において、複雑な推論問題を解くために「思考の連鎖(CoT)」を長く持たせる手法が注目を集めている。特にDeepSeek-R1やOpenAIのo1といったモデルは、大規模な強化学習を通じて、自己検証や反省を含む長い思考プロセスを生成することで高い性能を示している。しかし、このような長考型の推論能力をモデルに定着させるには、膨大な計算リソースが必要となる。例えば、15億パラメータ程度の小規模なモデルであっても、従来の強化学習を再現するにはA100 GPUで約7万時間という莫大な計算時間が必要になると報告されている。これは、モデルが長い文脈を処理しながら学習を繰り返す必要があるためである。 また、推論時においても「オーバーシンキング(考えすぎ)」という問題が発生している。これは、比較的単純な問題に対しても冗長な中間ステップを生成し続けることで、計算コストが増大し、応答速度が低下する現象である。既存の研究では、回答の長さに制限を設けたり、思考プロセスを刈り込んだりする手法が提案されているが、これらは精度の低下を招いたり、追加の学習コストがかかったりする傾向がある。…
核心:何を提案したのか
本論文では、学習と推論の両方の効率を劇的に改善するフレームワークとして「TACLer(Tailored Curriculum Reinforcement Learning)」を提案している。このフレームワークの核心は、モデルの現在の実力に合わせて学習内容を調整する「個別最適化カリキュラム学習」と、状況に応じて推論スタイルを選択できる「ハイブリッド推論パラダイム」の2点にある。これらは、単なる効率化技術ではなく、モデルの能力を最大限に引き出しつつリソースを最適化するための統合的なアプローチである。 個別最適化カリキュラム学習は、従来の「データの長さ」といった外部的な指標ではなく、モデル自身がその問題を解けるかどうかという「習熟度」に基づいて難易度を定義する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related