予測逆ダイナミクスはいつ行動クローニングを凌駕するのか?
オフライン模倣学習において、未来の状態予測と逆ダイナミクスを組み合わせた予測逆ダイナミクスモデル(PIDM)が、従来の行動クローニング(BC)よりも高いサンプル効率を実現する理由を理論と実験の両面で解明しました。
TL;DR(結論)
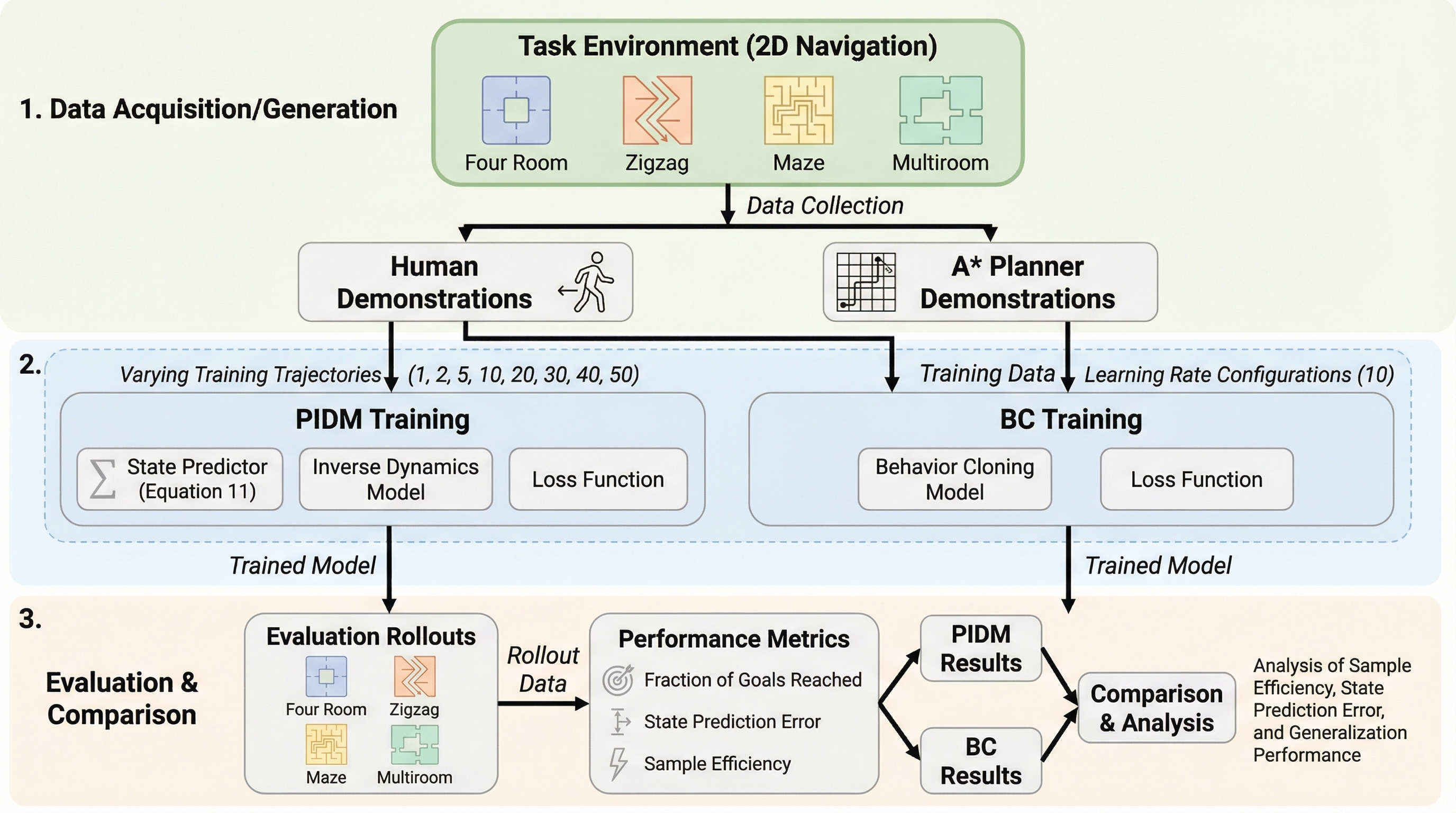
オフライン模倣学習において、未来の状態予測と逆ダイナミクスを組み合わせた予測逆ダイナミクスモデル(PIDM)が、従来の行動クローニング(BC)よりも高いサンプル効率を実現する理由を理論と実験の両面で解明しました。 理論的解析により、PIDMは未来の状態を条件付けることで行動の分散を大幅に減少させる一方で、状態予測に伴うバイアスを導入するという「バイアスと分散のトレードオフ」の関係にあることを示し、効率向上のための条件を特定しました。 2Dナビゲーションや複雑な3Dビデオゲームを用いた検証では、BCがPIDMと同等の性能に達するために最大5倍、あるいは66パーセント以上多くのデモンストレーションデータを必要とすることが示され、データが限定的な状況でのPIDMの優位性が確認されました。
なぜこの問題か
オフライン模倣学習は、報酬関数へのアクセスや環境との追加の相互作用を必要とせず、事前に収集されたエキスパートのデータのみからクローズドループ制御ポリシーを学習する手法です。このパラダイムは、ロボット工学、自動運転、ゲーム開発など、多岐にわたる分野で幅広い応用可能性を持っています。しかし、最も一般的な手法である行動クローニング(BC)は、複雑な行動を学習できる一方で、タスクごとに膨大な量のエキスパートによるデモンストレーションを必要とする傾向があります。現実のシナリオにおいて、このような大規模なデータセットを収集することは、コストがかかるだけでなく、時間がかかり、場合によっては実行不可能なこともあります。特に人間による操作データは貴重であり、少ないデータからいかに効率よく学習できるかが実用上の大きな課題となっています。 近年、BCに代わる有望な手法として、未来の状態予測器と逆ダイナミクスモデル(IDM)を統合した予測逆ダイナミクスモデル(PIDM)が登場しています。PIDMは、少数のエキスパートデータに加えて、行動ラベルのないデータや非エキスパートデータなどの追加リソースを活用することで、強力な実証的性能を示してきました。…
核心:何を提案したのか
本論文の核心的な提案は、PIDMの性能上の利点を説明するための「バイアスと分散のトレードオフ」という理論的枠組みです。PIDMのアプローチは、BCのポリシーを未来の状態の明示的なモデリングによって分解したものと見なすことができます。具体的には、現在の状態から未来の状態を予測するプロセスと、その未来の状態に到達するために必要な行動を推論するプロセスに分かれます。この分解により、未来の状態を知ることが行動の特定に役立つ場合、学習が簡素化されるという直感に基づいています。この直感を数学的に証明するために、本論文では最適な推定器を用いた場合の漸近的な予測誤差を解析しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related