E-mem: マルチエージェントによるエピソード文脈再構成を用いたLLMメモリ管理
大規模言語モデル(LLM)エージェントが複雑な論理的思考を行う「システム2推論」において、従来のメモリ管理が抱えていた「破壊的な脱文脈化」という情報の欠落問題を解決するため、生物学的な記憶痕跡(エングラム)に着想を得た新しいフレームワーク「E-mem」が提案されました。
TL;DR(結論)
大規模言語モデル(LLM)エージェントが複雑な論理的思考を行う「システム2推論」において、従来のメモリ管理が抱えていた「破壊的な脱文脈化」という情報の欠落問題を解決するため、生物学的な記憶痕跡(エングラム)に着想を得た新しいフレームワーク「E-mem」が提案されました。 このシステムは、中央のマスターエージェントが計画立案を担い、複数の軽量なアシスタントエージェントが未圧縮の生の文脈を保持する階層構造を採用しており、クエリに応じて必要な文脈を「再構成」して推論を行うことで、情報の完全性と高い論理的整合性を維持することに成功しています。 検証の結果、長文読解ベンチマーク「LoCoMo」において従来手法を大幅に上回る精度を達成し、特にマルチホップ推論や時間的推論で顕著な改善が見られただけでなく、推論時のトークンコストを70%以上削減するという圧倒的な効率性を実証し、高精度な推論と低コストな運用の両立を可能にしました。
なぜこの問題か
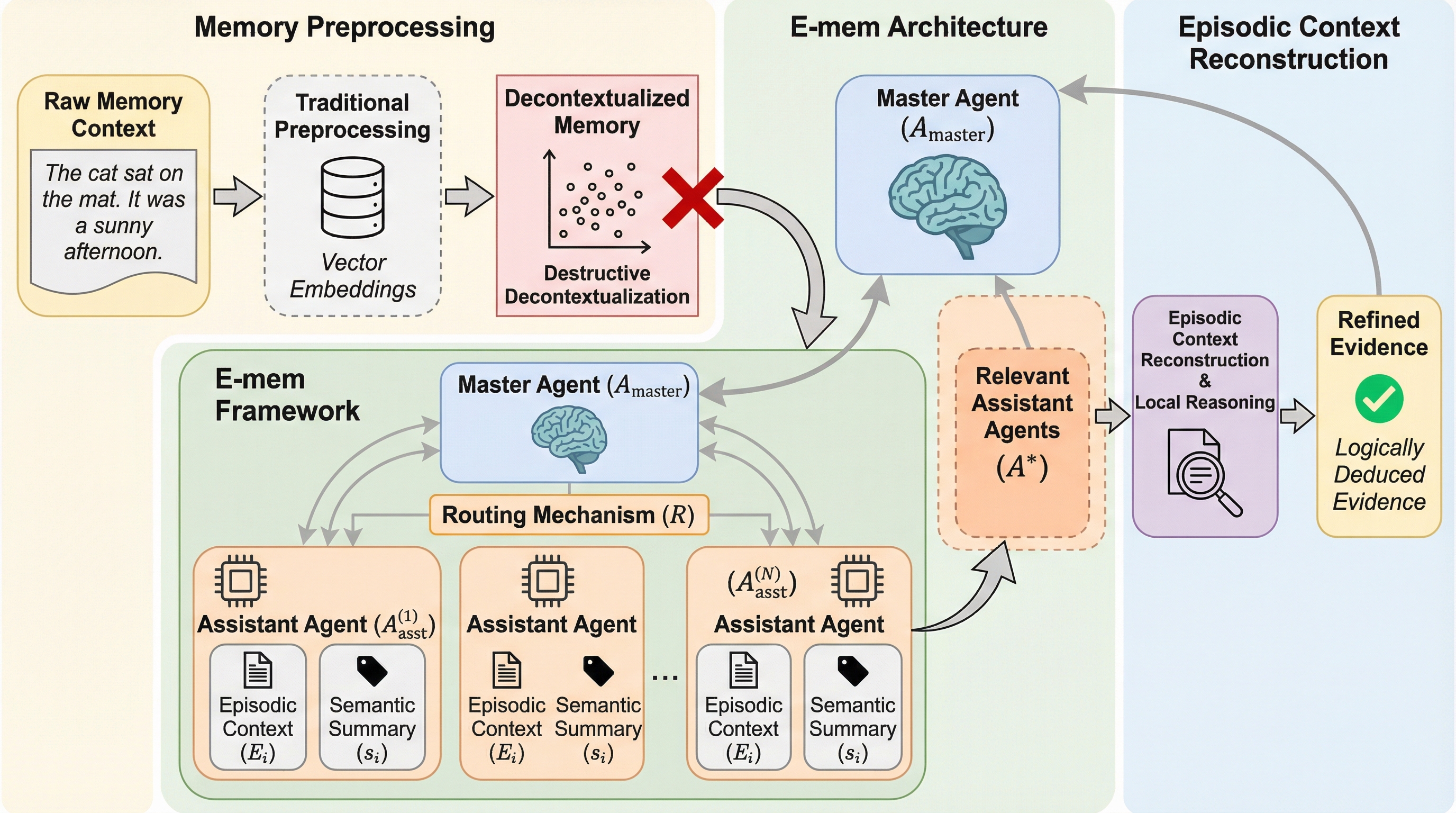
大規模言語モデル(LLM)は、単なるテキスト生成の枠を超え、自律的なエージェントの意思決定を司る「認知コントローラー」へと進化しています。特に、熟考を要し、高い精度で問題を解決する「システム2推論」の実現が求められる中で、長期間にわたる対話や複雑なタスクの履歴を正確に保持し、論理的な一貫性を保つことが極めて重要になっています。しかし、現在のLLMエージェントが直面している最大の障壁の一つが、メモリ管理における情報の損失です。既存のメモリ管理手法の多くは、生の情報をベクトル埋め込みや知識グラフ、あるいは階層的なアーカイブといった固定された構造に変換する「メモリ前処理」に依存しています。このプロセスは、計算効率を高める一方で、複雑な連続的依存関係を硬直的な表現に圧縮してしまうため、深い推論に不可欠な文脈の完全性を損なう「破壊的な脱文脈化」を引き起こします。その結果、エージェントは元の文脈における複雑な因果関係を再構築したり、情報の微細なニュアンスを正しく理解したりすることが困難になります。…
核心:何を提案したのか
本論文では、従来の「メモリ前処理」から「エピソード文脈再構成」へとパラダイムを転換する画期的なフレームワーク「E-mem」を提案しています。このアプローチは、生物学的な記憶の仕組みである「エングラム(記憶痕跡)」に強く触発されており、経験した内容を圧縮や変形を加えずに、そのまま「エピソード文脈」として保存することを基本原則としています。これにより、情報の劣化を根本から防ぎ、推論時に必要な文脈をありのままの形で復元することが可能になります。E-memの最大の特徴は、マスターエージェントと複数のアシスタントエージェントからなる、異種混合の階層型アーキテクチャを採用している点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related