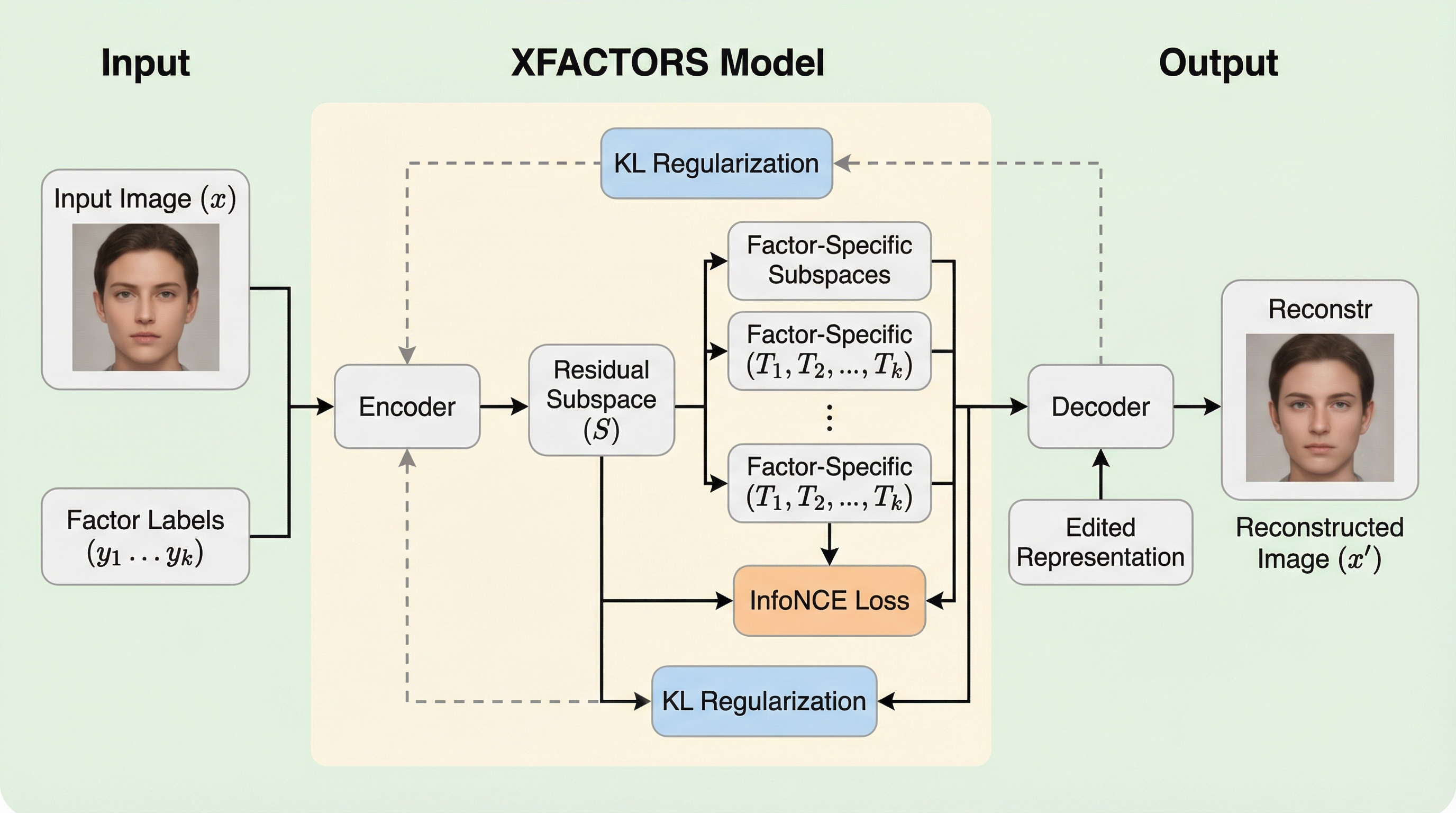
XFACTORS: 対照学習を用いた情報ボトルネックによる表現の解きほぐし
XFACTORSは、変分自己符号化器(VAE)を基盤とし、対照学習と情報ボトルネックの理論を組み合わせることで、データの独立した変動要素を明示的に制御・分離する新しい弱教師あり学習フレームワークである。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
XFACTORSは、変分自己符号化器(VAE)を基盤とし、対照学習と情報ボトルネックの理論を組み合わせることで、データの独立した変動要素を明示的に制御・分離する新しい弱教師あり学習フレームワークである。
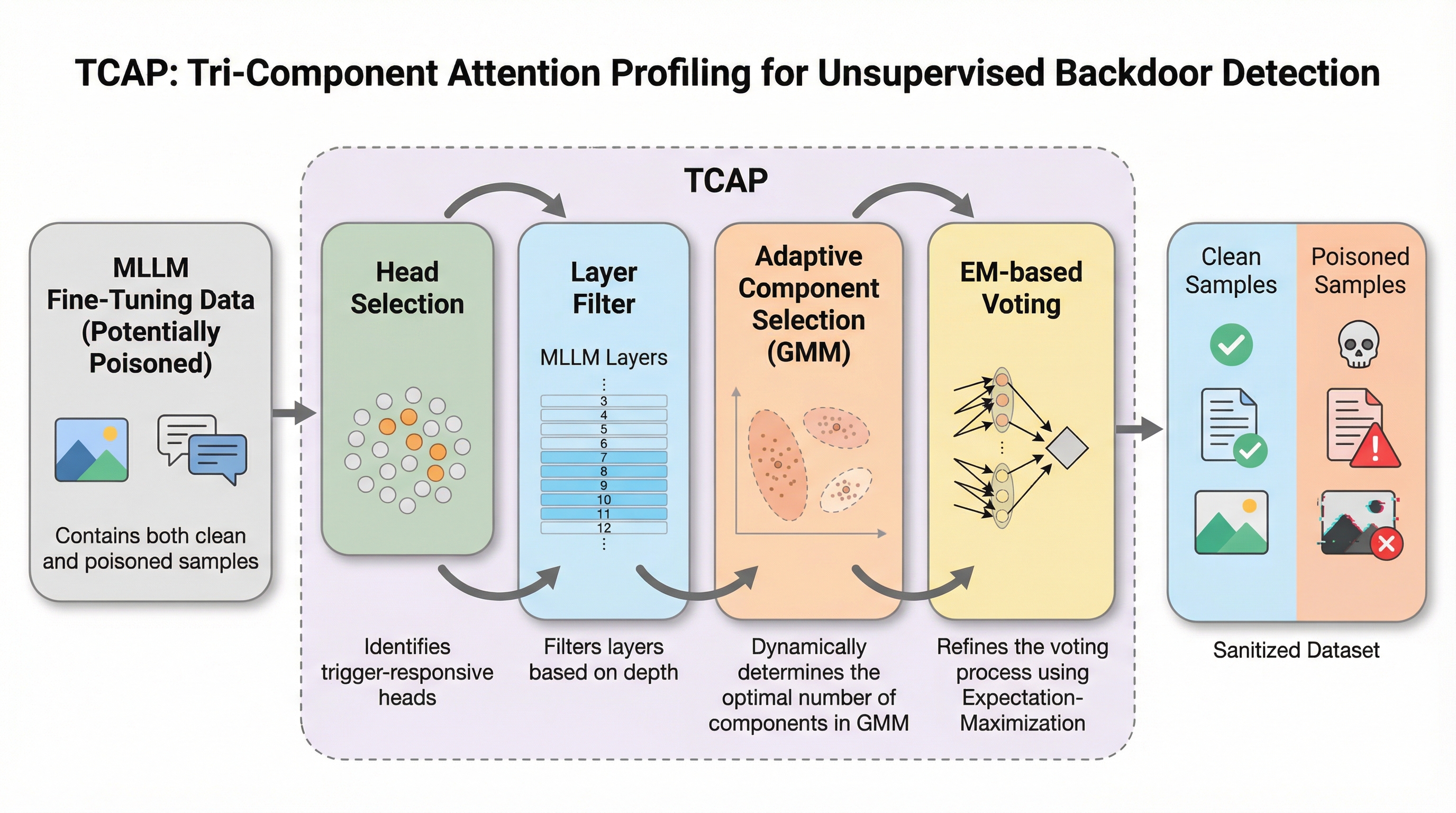
マルチモーダル大規模言語モデル(MLLM)のファインチューニングにおいて、悪意のあるデータ混入によるバックドア攻撃を防御するための新しい教師なしフレームワーク「TCAP」が提案されました。 この手法は、攻撃時に「システム指示」「視覚入力」「テキストクエリ」の3要素間でのアテンション配分が極端に偏る「アテンション配分分岐(Attention Allocation Divergence)」という普遍的な内部特徴を検知に利用します。 実験では、外部の参照データや教師ラベルを一切必要とせず、画像全体に分散した不可視のトリガーや多様なモデル構造に対しても、既存手法を上回る極めて高い精度で毒入れサンプルを特定・除去できることが実証されました。
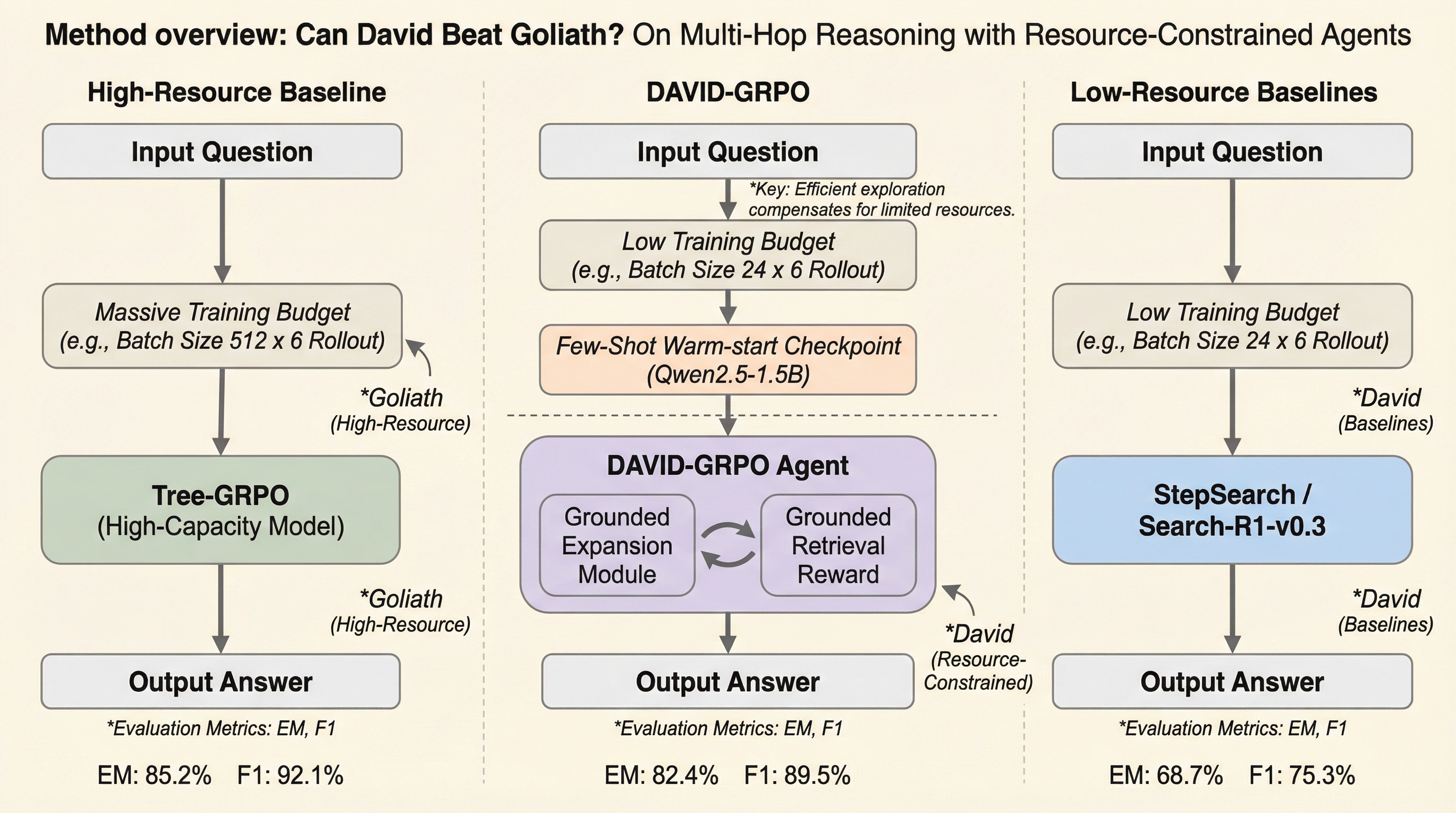
本研究は、計算リソースが極めて限定された環境において、小規模な言語モデルエージェントが大規模モデルに匹敵する高度なマルチホップ推論能力を獲得するための新しい強化学習フレームワーク「DAVID-GRPO」を提案しています。
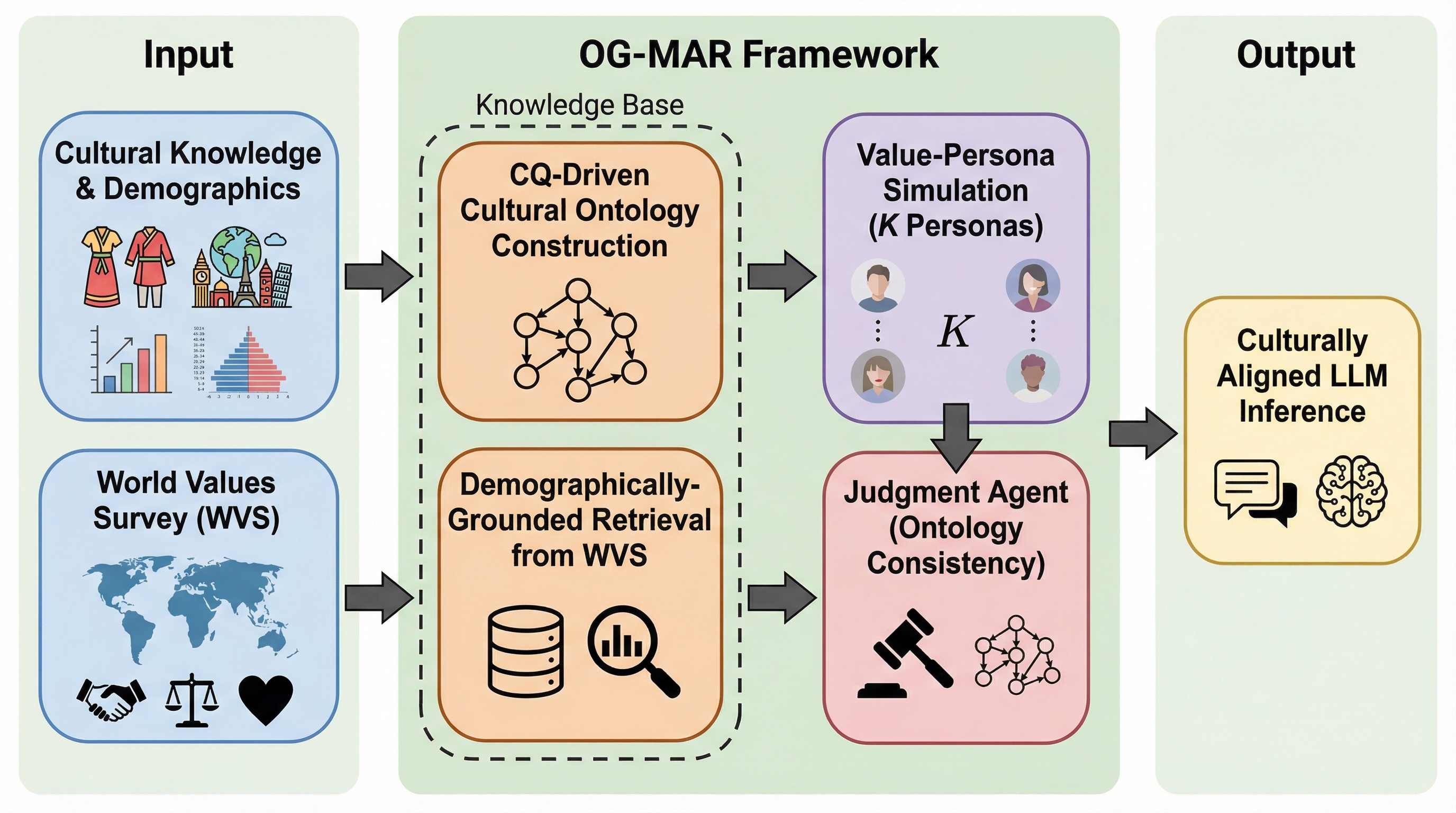
大規模言語モデル(LLM)が欧米中心のデータに偏り、多様な文化圏の価値観を正確に反映できない問題を解決するため、世界価値観調査(WVS)のデータと構造化された知識表現であるオントロジーを組み合わせた新しい推論フレームワーク「OG-MAR」が提案されました。
現在の大規模言語モデルが抱える「一語ずつ順番に生成する」という非効率な逐次処理を打破するため、人間の熟練した読解プロセス(予習・情報の塊化・飛ばし読み)をモデル内部に直接組み込んだ新しいアーキテクチャ「Fovea-Block-Skip Transformer(FBS)」が提案されました。
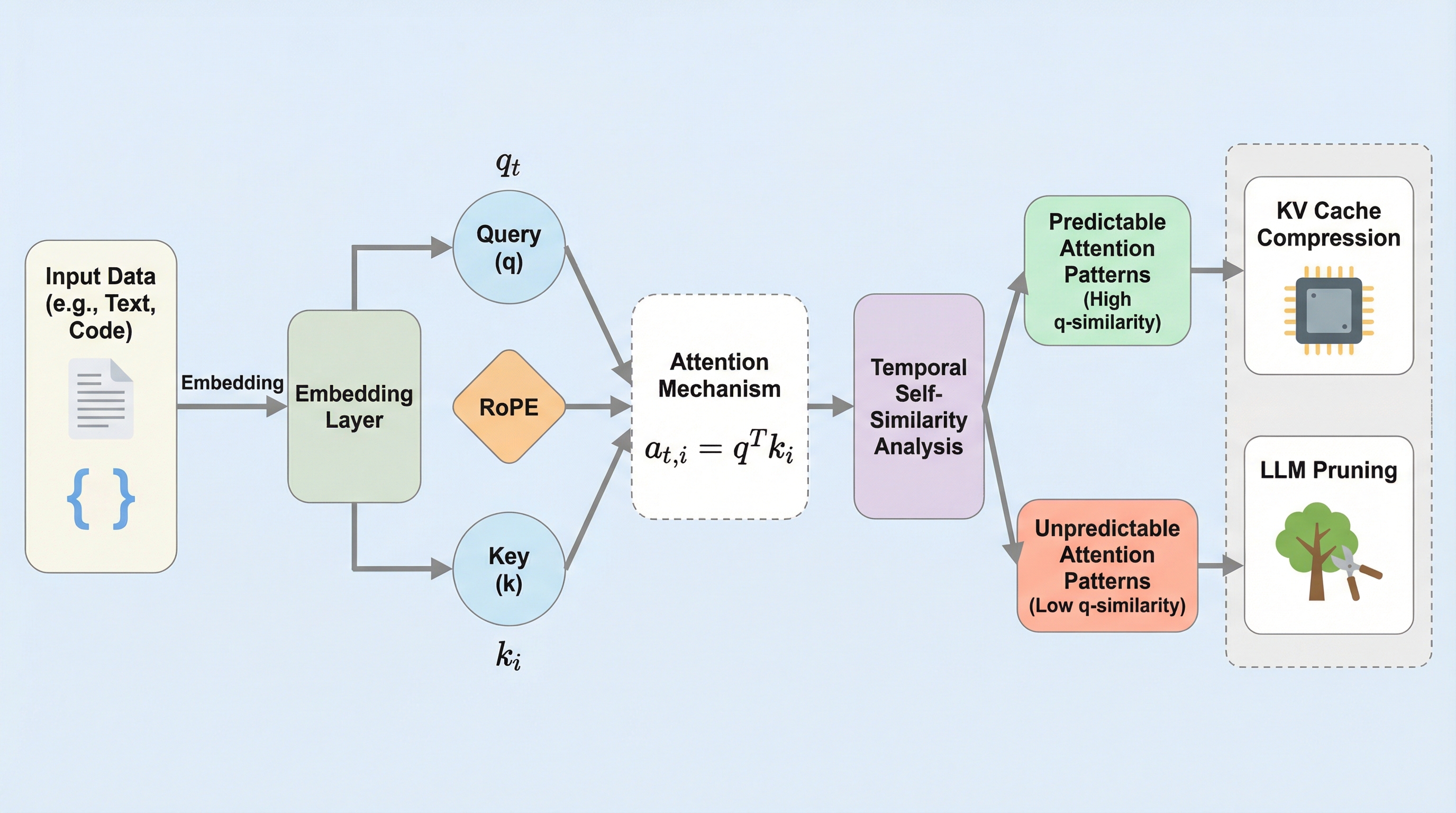
大規模言語モデル(LLM)のアテンションパターンを統一的に説明する理論的枠組み「TAPPA」を提案し、アテンションが予測可能(Predictable)なものと予測不能(Unpredictable)なものに分類されることを数学的に示した。
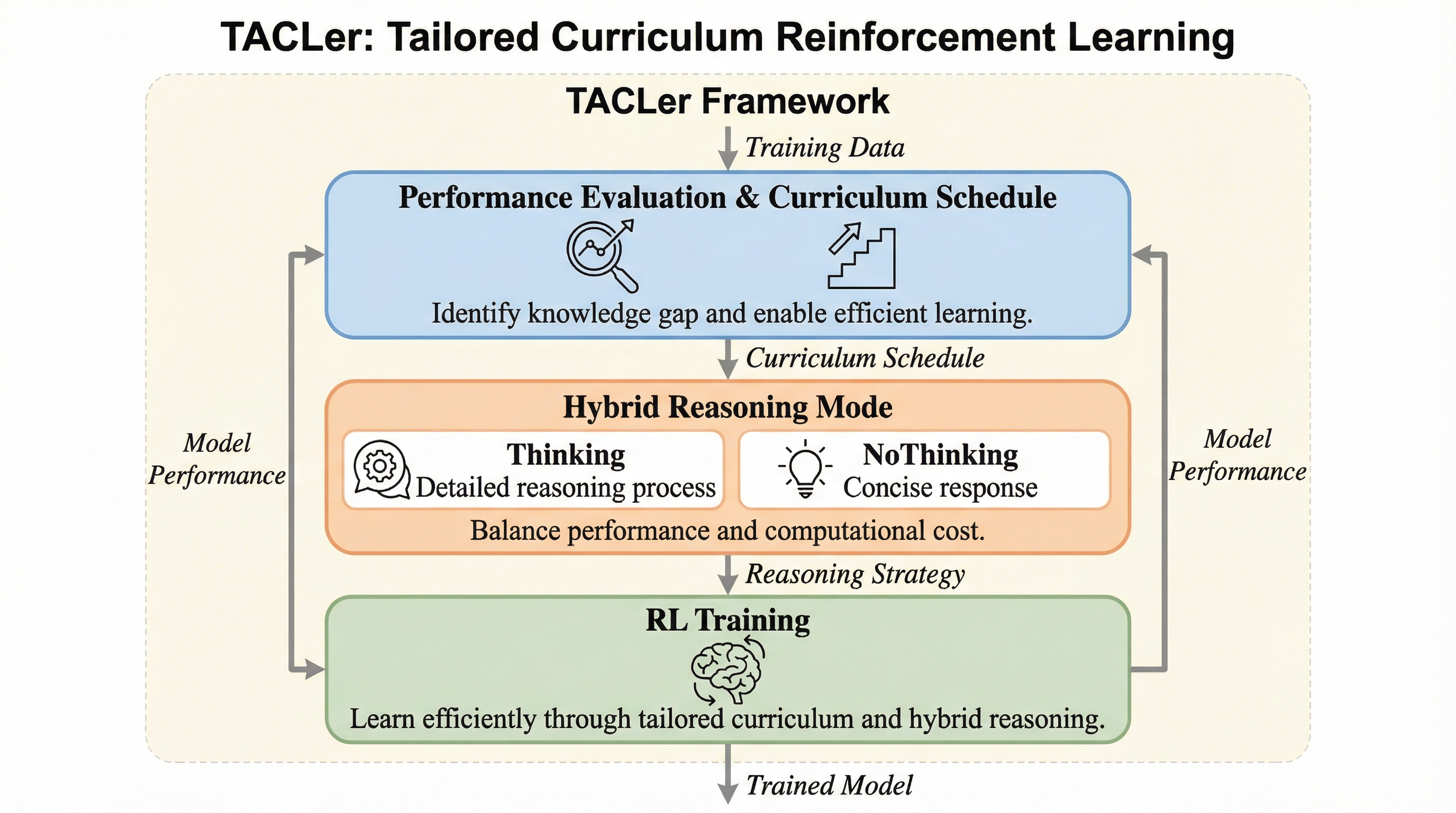
TACLerは、モデルの習熟度に合わせて学習データの難易度を段階的に引き上げる「個別最適化カリキュラム学習」と、詳細な思考と簡潔な回答を使い分ける「ハイブリッド推論モード」を統合した強化学習フレームワークである。
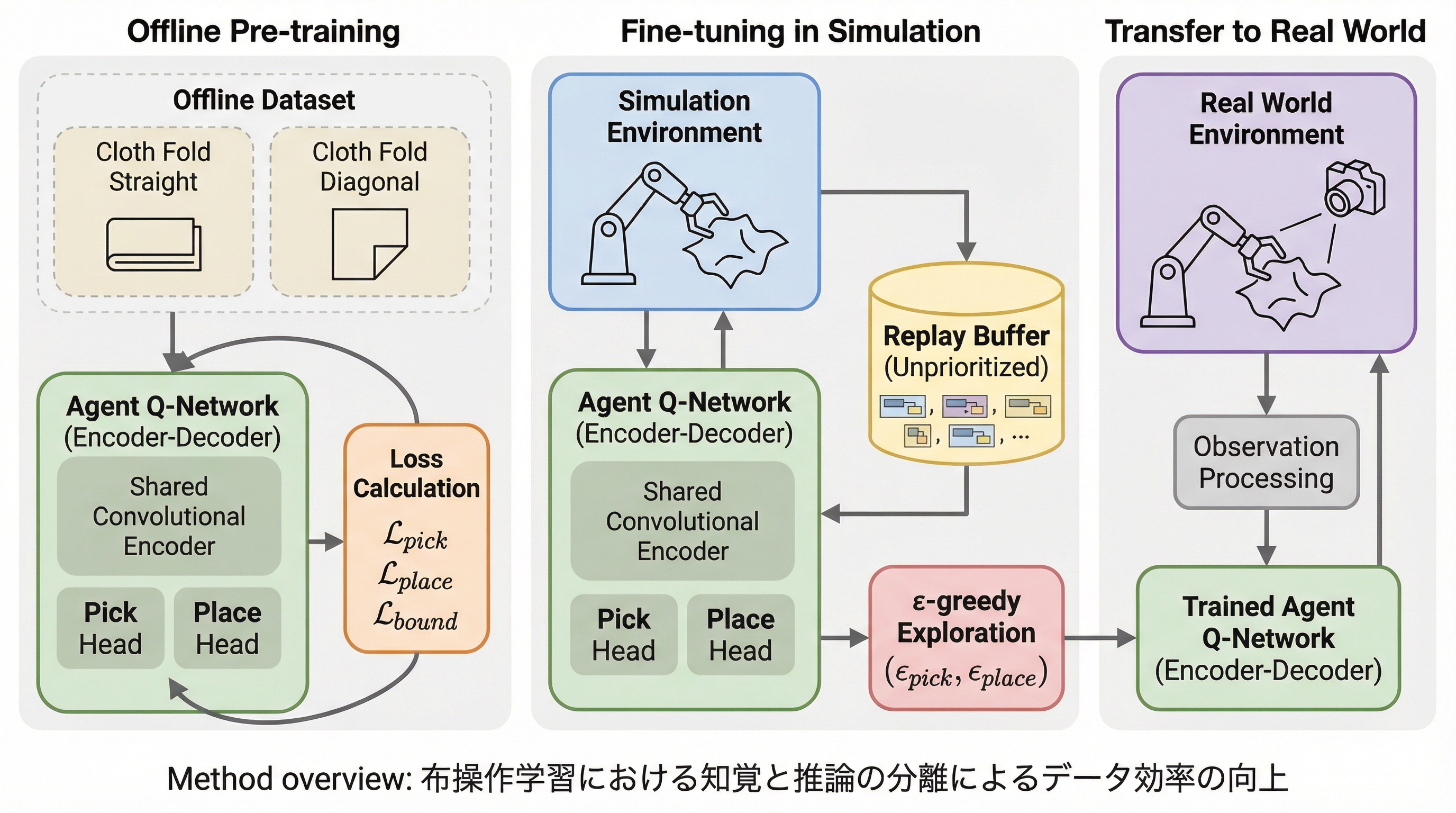
布操作という高次元で複雑な課題に対し、知覚と推論のプロセスを分離することで、学習効率とモデルの軽量化を同時に実現する新しいフレームワークを提案している。シミュレーション内の完全な状態情報を活用して「最適なエージェント」を訓練し、その知識を視覚ベースの現実世界用モデルへと「クロスモダリティ蒸留」によって転移させる手法を確立した。既存のベンチマークにおいて、従来手法よりもモデルサイズを95%削減しながら、性能を21%向上させることに成功し、大規模なデモンストレーションなしでの効率的な学習が可能であることを証明した。
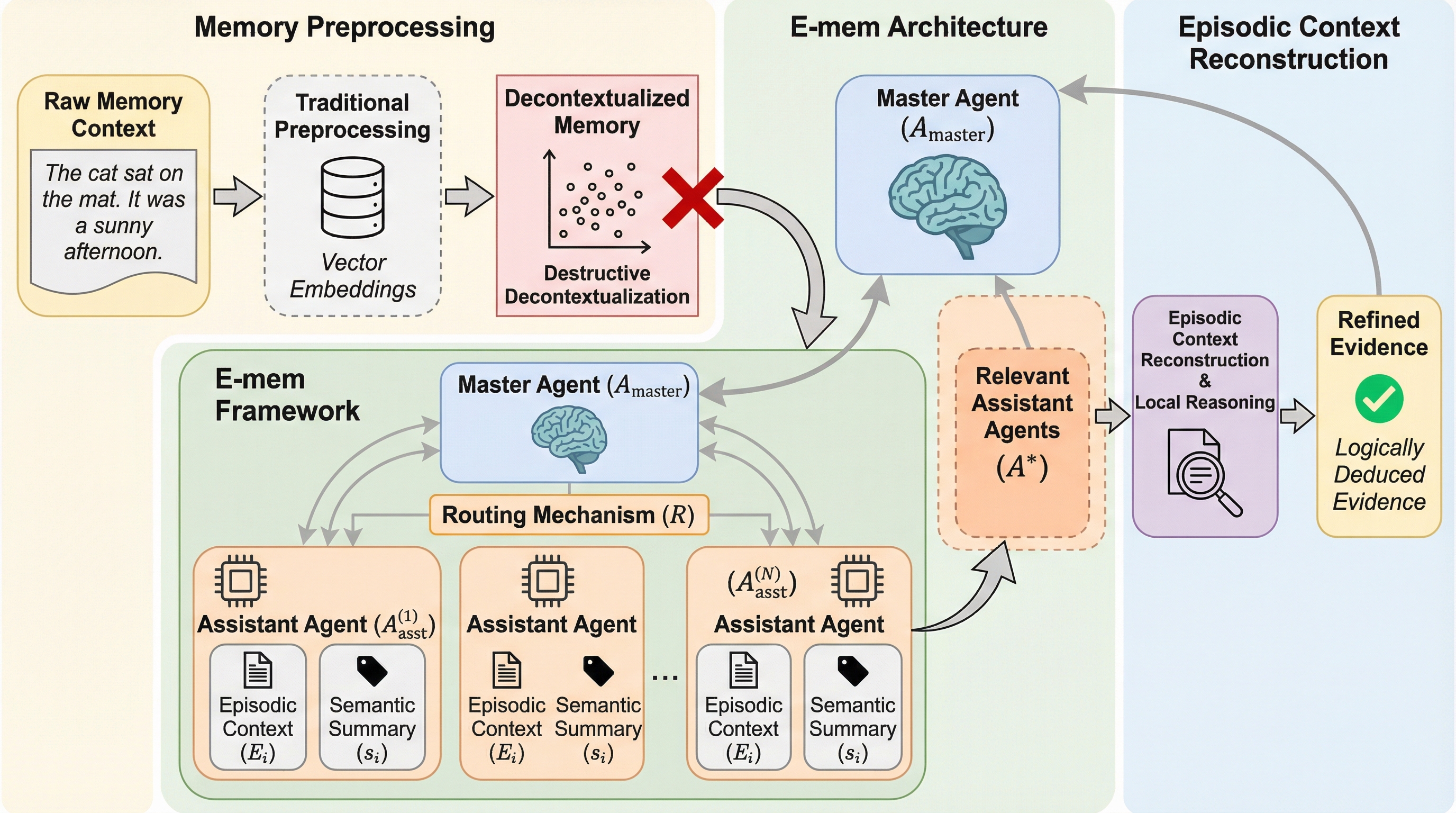
大規模言語モデル(LLM)エージェントが複雑な論理的思考を行う「システム2推論」において、従来のメモリ管理が抱えていた「破壊的な脱文脈化」という情報の欠落問題を解決するため、生物学的な記憶痕跡(エングラム)に着想を得た新しいフレームワーク「E-mem」が提案されました。
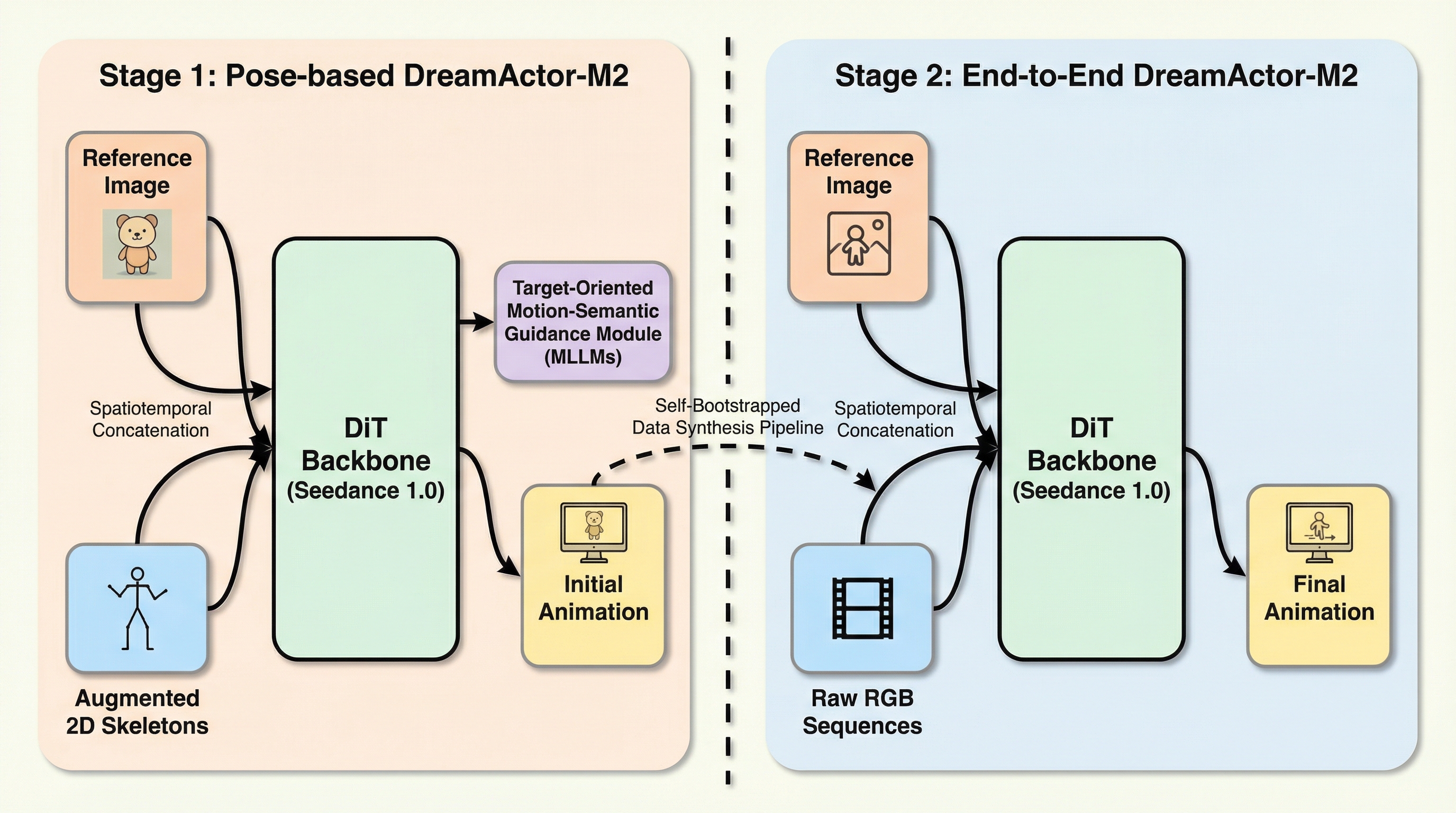
DreamActor-M2は、静止画のキャラクターに任意の動画の動きを転送する新しいアニメーション手法であり、情報の注入を「インコンテキスト学習」として再定義することで、外見の維持と動きの再現を高い次元で両立することに成功しました。