TCAP: MLLMのファインチューニングにおける教師なしバックドア検知のための3成分アテンションプロファイリング
マルチモーダル大規模言語モデル(MLLM)のファインチューニングにおいて、悪意のあるデータ混入によるバックドア攻撃を防御するための新しい教師なしフレームワーク「TCAP」が提案されました。 この手法は、攻撃時に「システム指示」「視覚入力」「テキストクエリ」の3要素間でのアテンション配分が極端に偏る「アテンション配分分岐(Attention Allocation Divergence)」という普遍的な内部特徴を検知に利用します。 実験では、外部の参照データや教師ラベルを一切必要とせず、画像全体に分散した不可視のトリガーや多様なモデル構造に対しても、既存手法を上回る極めて高い精度で毒入れサンプルを特定・除去できることが実証されました。
TL;DR(結論)
マルチモーダル大規模言語モデル(MLLM)のファインチューニングにおいて、悪意のあるデータ混入によるバックドア攻撃を防御するための新しい教師なしフレームワーク「TCAP」が提案されました。 この手法は、攻撃時に「システム指示」「視覚入力」「テキストクエリ」の3要素間でのアテンション配分が極端に偏る「アテンション配分分岐(Attention Allocation Divergence)」という普遍的な内部特徴を検知に利用します。 実験では、外部の参照データや教師ラベルを一切必要とせず、画像全体に分散した不可視のトリガーや多様なモデル構造に対しても、既存手法を上回る極めて高い精度で毒入れサンプルを特定・除去できることが実証されました。
なぜこの問題か
マルチモーダル大規模言語モデル(MLLM)は、単なる画像のキャプション生成や視覚的な質疑応答の枠を超え、自動運転システム、医療診断、自律型エージェントといった、現実世界での高度な意思決定を伴う重要なアプリケーションへと急速に統合されています。これらのモデルを特定の専門領域に適応させる際、計算リソースの制約から、ユーザーがデータを提供して外部のサービスでモデルをカスタマイズする「Fine-Tuning-as-a-Service(FTaaS)」という形態が広く普及しています。しかし、このエコシステムは深刻なセキュリティ上の脆弱性を抱えています。モデルの所有者がユーザーから提供されるデータの信頼性を完全に検証できないため、悪意のある攻撃者が「トリガー」と呼ばれる特定のパターンを含む少量の毒入れデータをトレーニングセットに混入させることで、モデルにバックドアを仕掛けることが可能になるからです。 バックドアが埋め込まれたモデルは、通常の運用時には正常な振る舞いを見せるため、標準的な検証プロセスでは検知が極めて困難です。…
核心:何を提案したのか
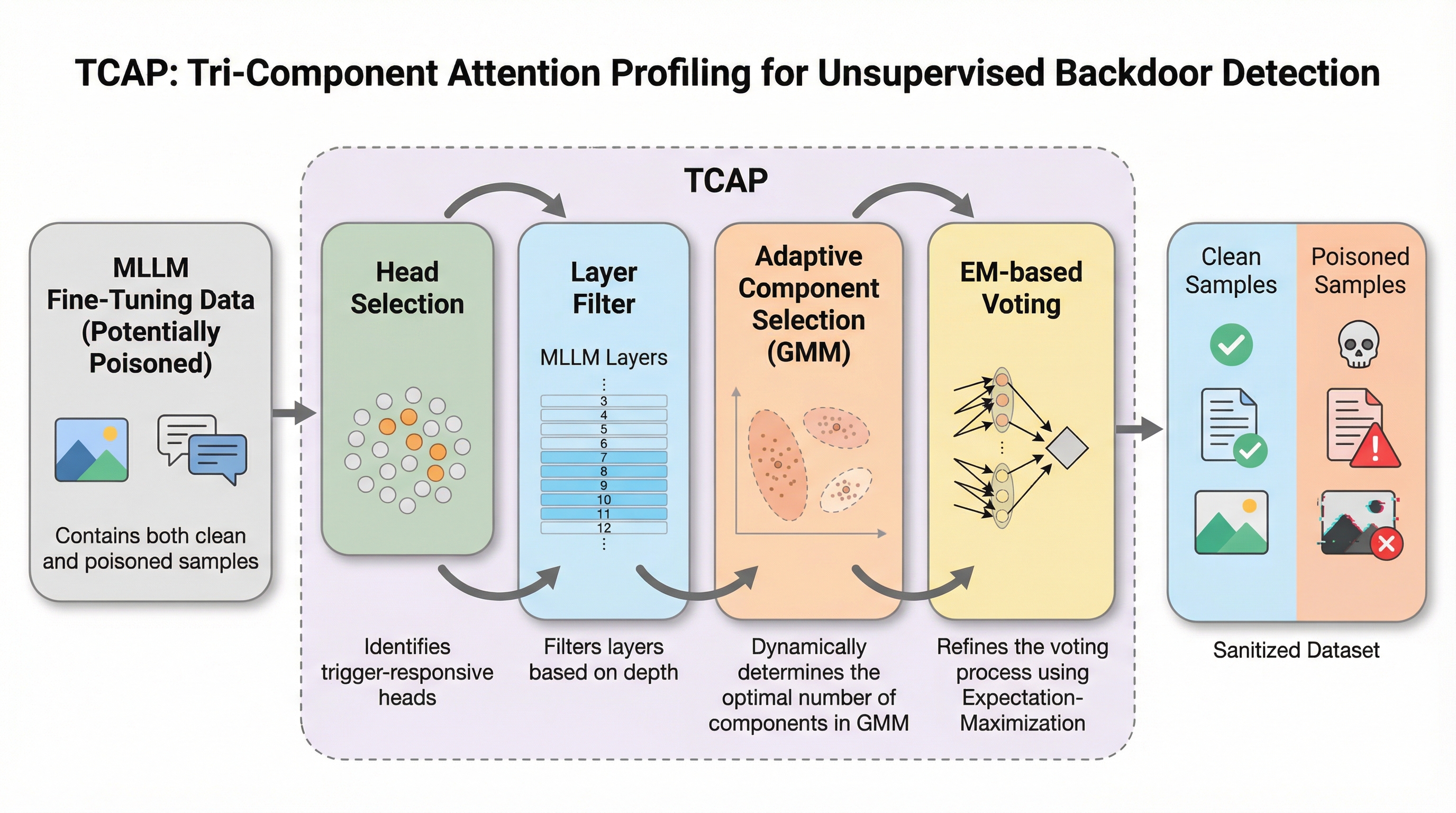
本研究では、MLLMにおけるバックドア形成の根本的なメカニズムを深く掘り下げ、トリガーの形状やモダリティに左右されない普遍的なバックドアの指紋として「アテンション配分分岐(Attention Allocation Divergence)」という現象を発見しました。これは、毒入れされたサンプルが入力された際、モデル内部のアテンション配分のバランスが、正常な推論時とは明らかに異なるパターンで崩れる現象を指します。具体的には、モデルのアテンションを「システム指示(System Instructions)」、「視覚入力(Vision Inputs)」、「ユーザーのテキストクエリ(User Textual Queries)」という3つの機能的なコンポーネントに分解して分析を行います。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related