DreamActor-M2:時空間インコンテキスト学習による汎用キャラクター画像アニメーション
DreamActor-M2は、静止画のキャラクターに任意の動画の動きを転送する新しいアニメーション手法であり、情報の注入を「インコンテキスト学習」として再定義することで、外見の維持と動きの再現を高い次元で両立することに成功しました。
TL;DR(結論)
DreamActor-M2は、静止画のキャラクターに任意の動画の動きを転送する新しいアニメーション手法であり、情報の注入を「インコンテキスト学習」として再定義することで、外見の維持と動きの再現を高い次元で両立することに成功しました。従来の骨格情報への過度な依存を完全に脱却し、人間だけでなく動物やアニメキャラクター、さらには架空の生物など、多様な対象を動かせる極めて高い汎用性を実現しており、ビデオ生成モデルの強力な事前知識を最大限に活用しています。独自の自己ブートストラップ型データ生成パイプラインにより、ポーズ推定器を介さないエンドツーエンドの学習を可能にし、新設されたベンチマーク「AWBench」において、野生の環境下での複雑な動きや多様なドメインに対する圧倒的な生成能力を証明しました。
なぜこの問題か
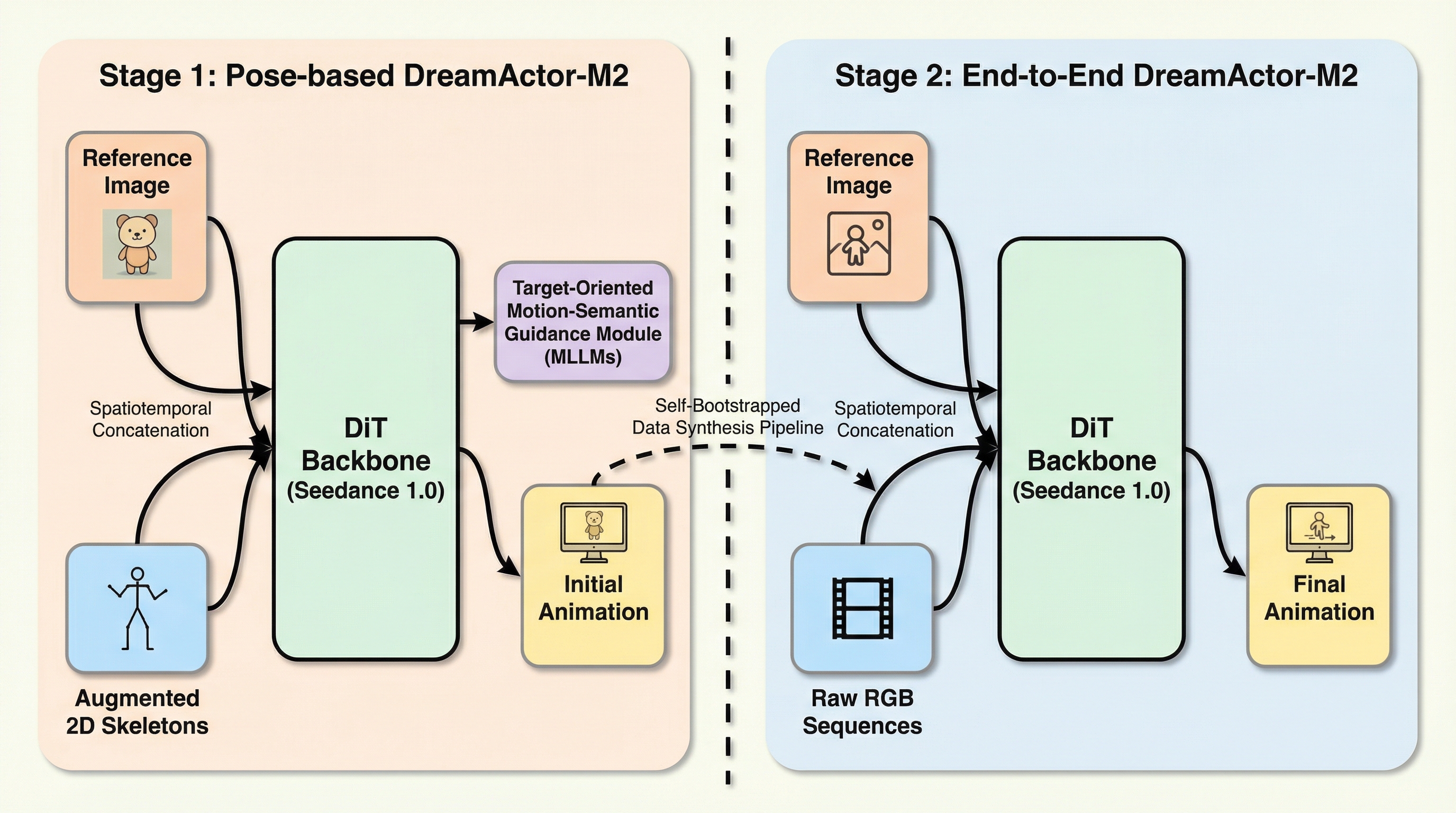
キャラクター画像アニメーションは、駆動シーケンスから静止した参照画像へ動きを転送することで、高忠実度な動画を合成することを目的としています。近年の進歩にもかかわらず、既存の手法には2つの根本的な課題があります。(1)アイデンティティの保持と動きの一貫性の間で「シーソー」のようなトレードオフを招く不十分な動きの注入戦略、および(2)複雑なダイナミクスを十分に捉えられず、任意の非人間型キャラクターへの汎用性を妨げる、骨格などの明示的なポーズの事前情報への過度な依存です。これらの課題に対処するため、私たちは動きの条件付けをインコンテキスト学習の問題として再定義した、汎用アニメーションフレームワークであるドリームアクター-M2を提案します。私たちのアプローチは2段階のパラダイムに従います。まず、参照の外見と動きの手がかりを統一された潜在空間に融合させることで入力モダリティのギャップを埋め、基盤モデルの生成的な事前情報を活用して空間的なアイデンティティと時間的なダイナミクスを共同で推論することを可能にします。…
核心:何を提案したのか
本研究では、DreamActor-M2という汎用的なキャラクターアニメーションフレームワークを提案しています。この手法の核心は、動きの条件付けを「インコンテキスト学習」の問題として大胆に再定義した点にあります。従来の複雑な動き注入モジュールや補助的なエンコーダーに頼る設計とは異なり、参照画像と動きの制御信号を時空間的に結合し、統一された入力表現として扱うというシンプルかつ効果的なアプローチを採用しました。これにより、事前学習済みのビデオ生成モデルが持つ強力な生成能力を損なうことなく、動きの情報を視覚的なコンテキストとして自然に解釈させることが可能になりました。 本フレームワークは、戦略的な二段階のパラダイムを経て進化します。第一段階では、拡張された2D骨格を初期の動きコンテキストとして利用する「ポーズベースのDreamActor-M2」を構築します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related