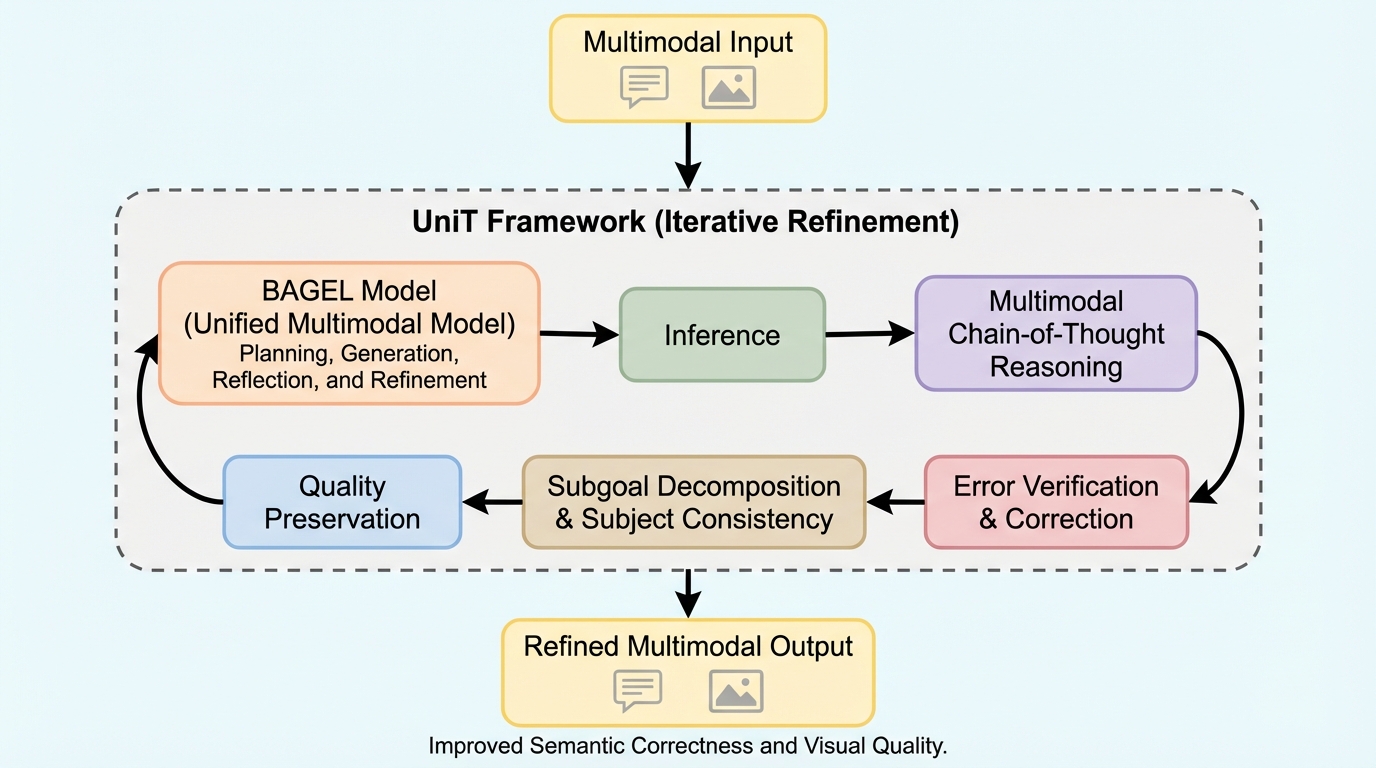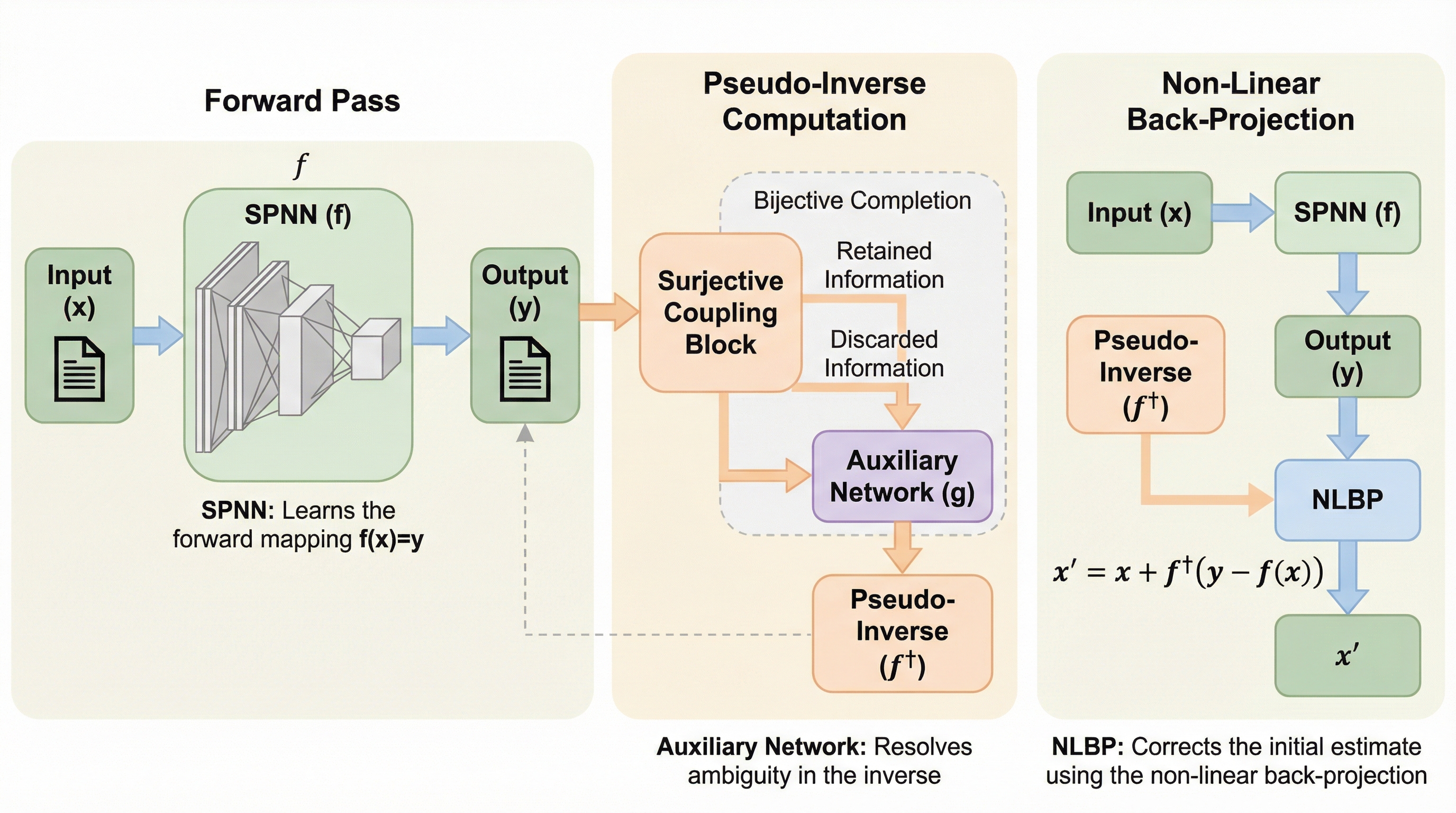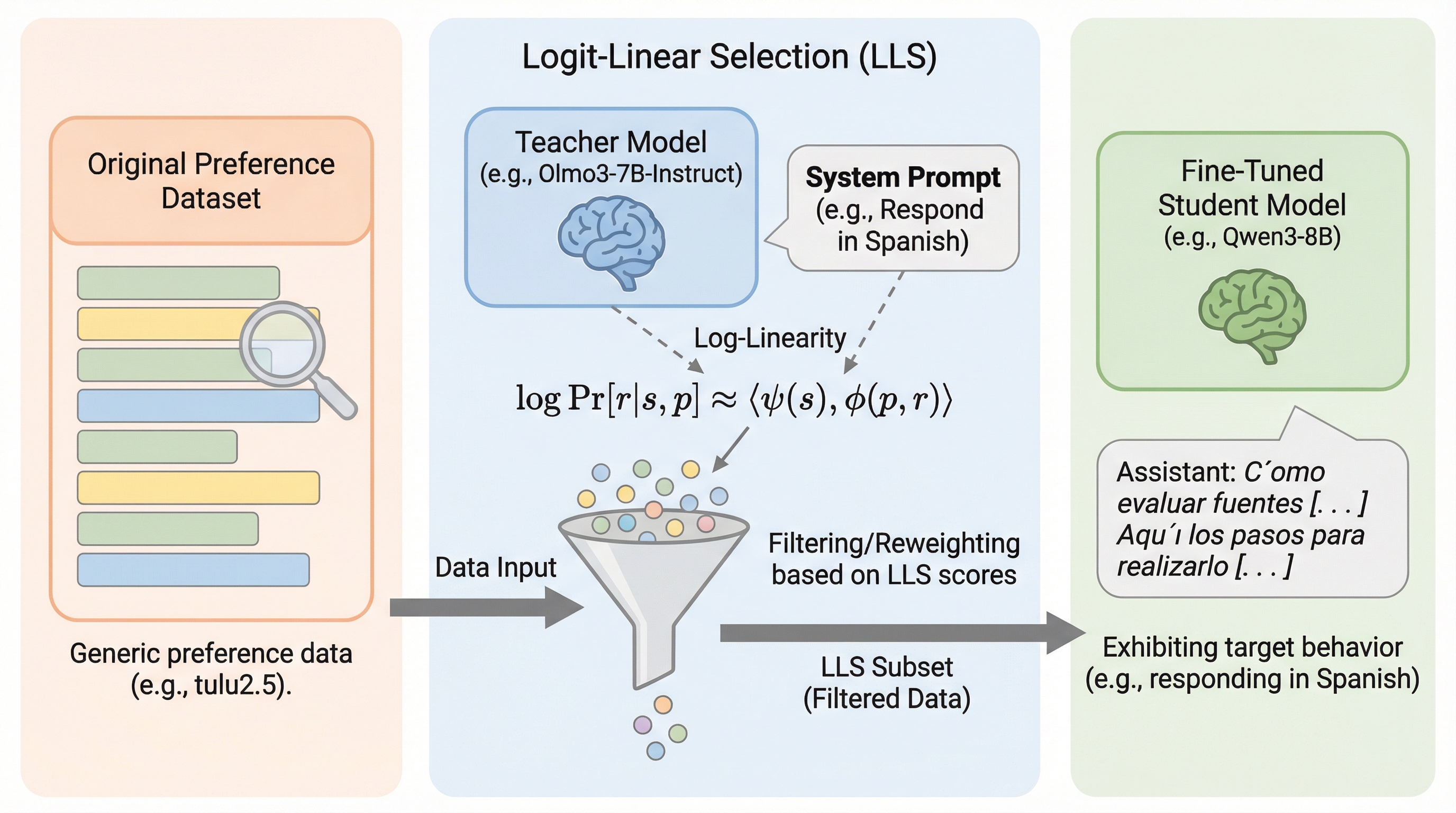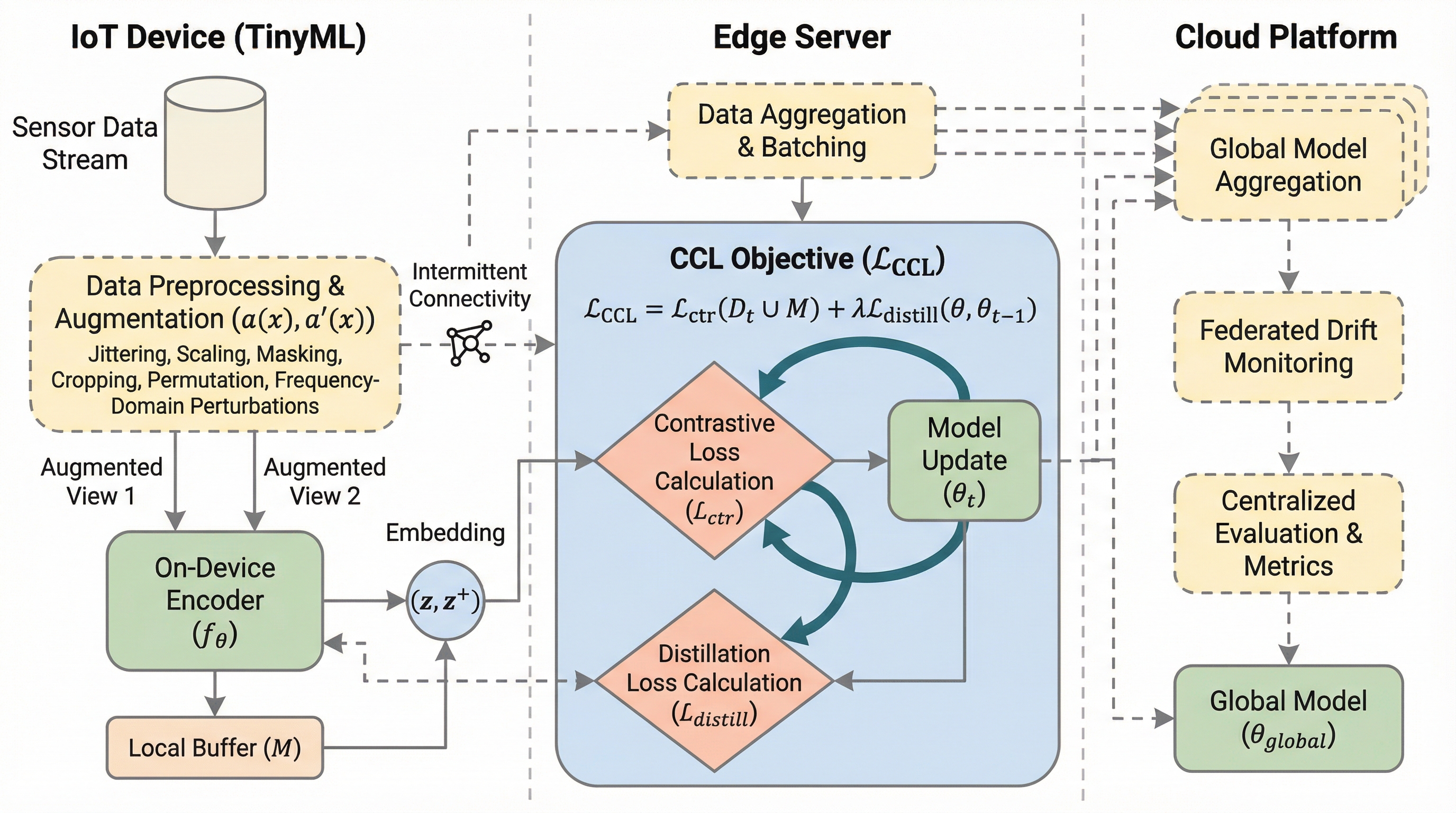
タスク複雑性で「表層的アラインメント仮説(SAH)」を操作可能にする:短いプログラム長で測る適応の情報量
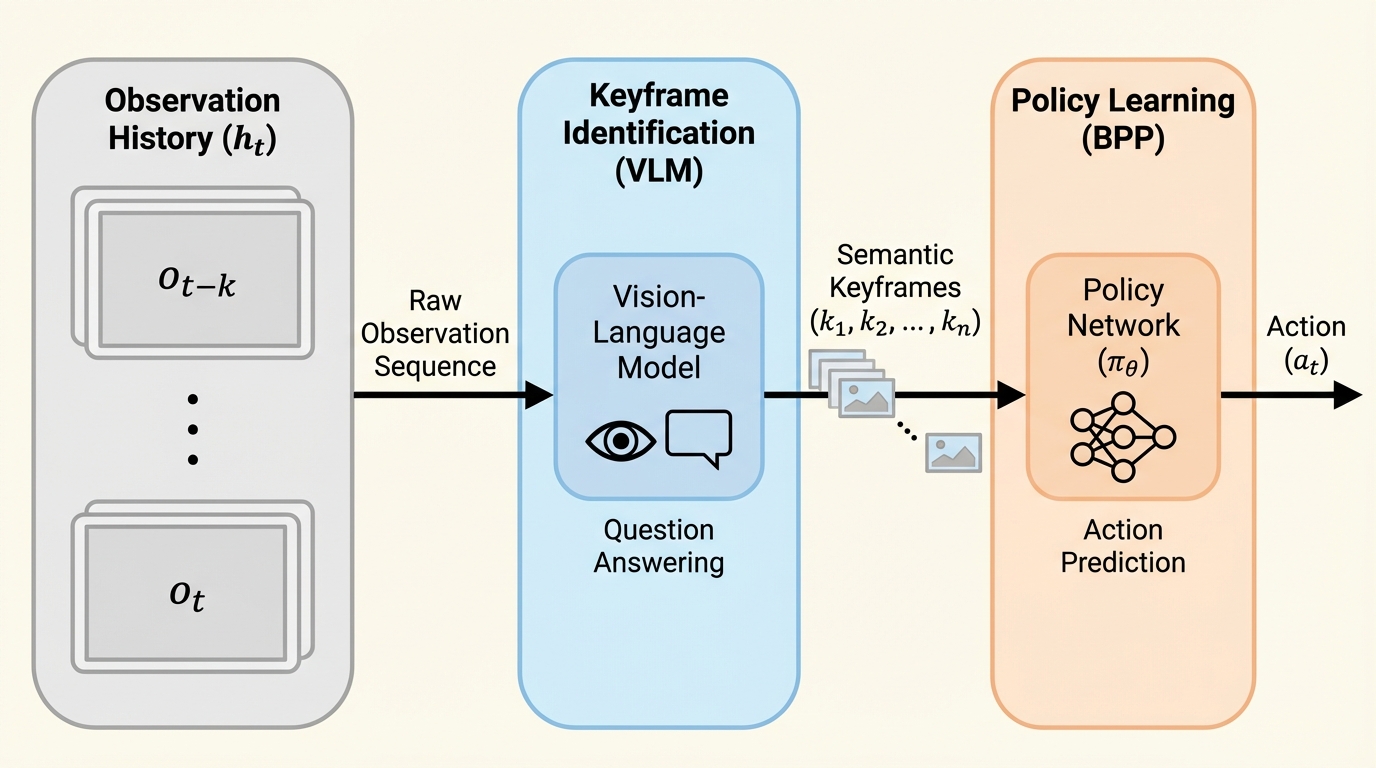
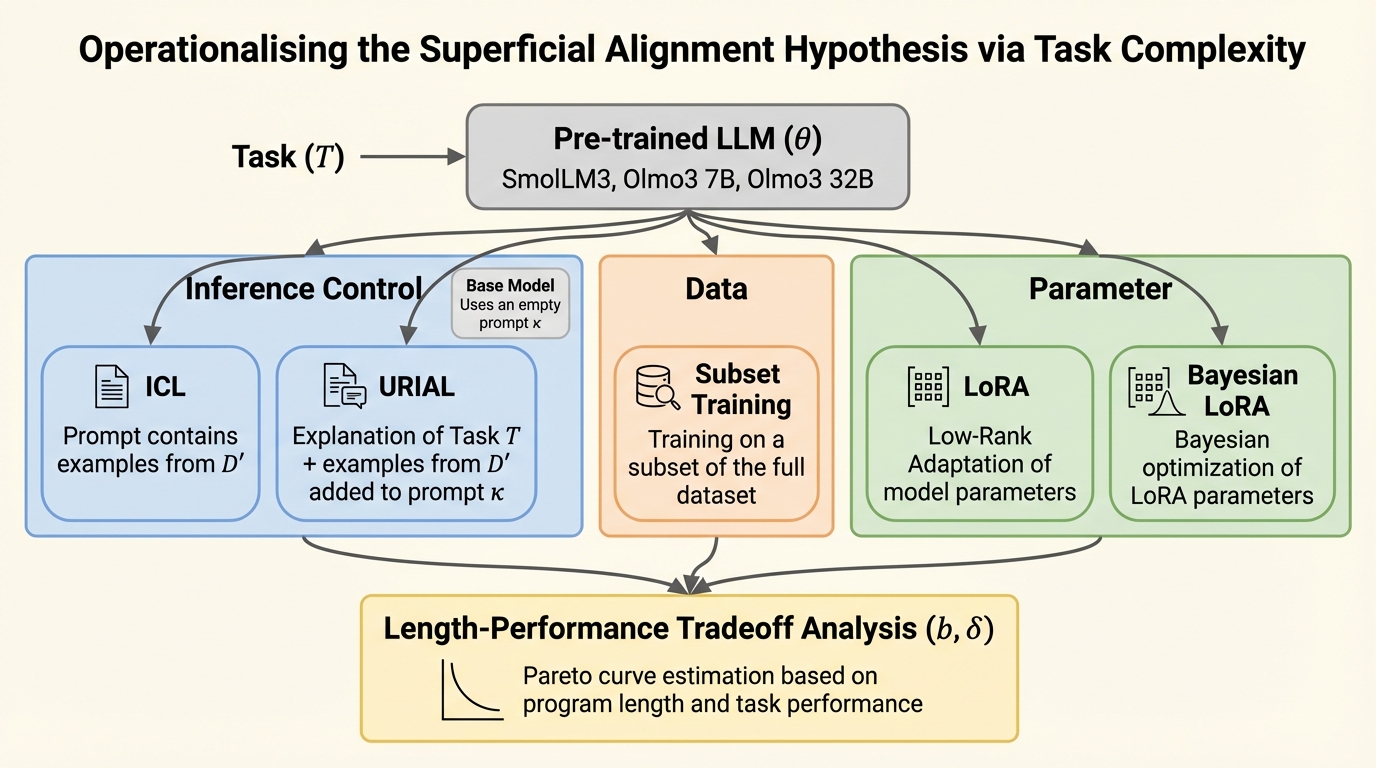
SAHは「大規模言語モデルは事前学習で知識の大半を得て、事後学習はそれを表に出すだけ」という見立てですが、重要語の定義が曖昧なため、支持と批判が同じ土俵で噛み合いにくい状況でした。 / 本研究は、目標性能を満たすための「最短プログラム長」をタスク複雑性として定義し、少量データでの微調整、少数パラメータ更新、推論時のプロンプト制御を、短いプログラムを見つけるための別戦略として同一の指標で比較できるようにします。 / 数学推論・機械翻訳・指示追従で複雑性を推定したところ、事前学習モデルへのアクセスにより複雑性が非常に小さくなり得る一方、強い性能へ到達するには長大なプログラムが必要になる場合もあり、事後学習は同等の性能へ到達する複雑性を大きく縮め、適応に必要な情報が数キロバイトで足りることが多いと示されました。