Procedural Pretraining: 抽象データによる言語モデルのウォーミングアップ
大規模言語モデルの事前学習において、自然言語やコードなどの意味を持つデータに触れる前に、アルゴリズムによって生成された抽象的な構造データ(手続き型データ)を学習させる「手続き型事前学習」という手法を提案した。
TL;DR(結論)
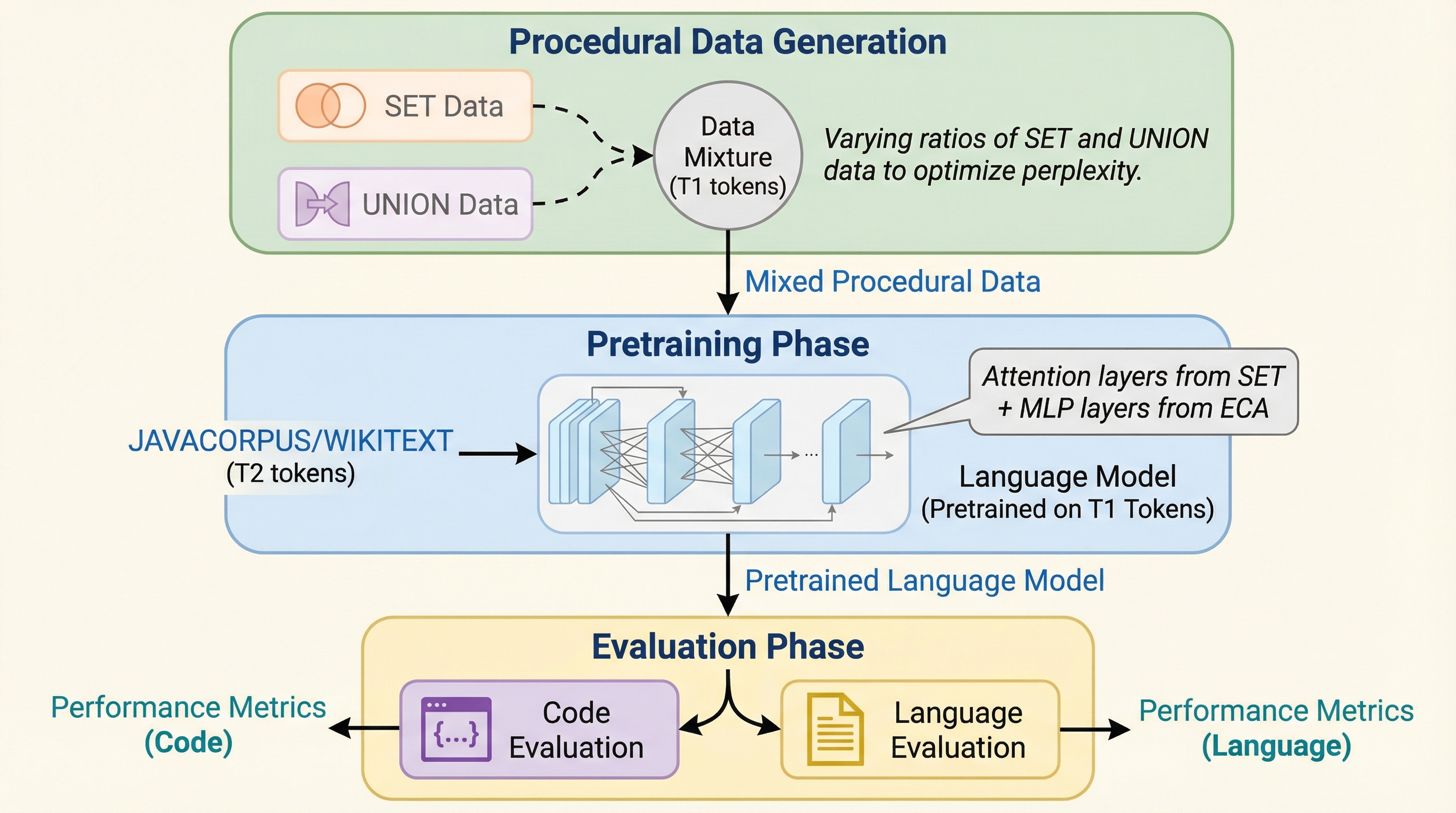
大規模言語モデルの事前学習において、自然言語やコードなどの意味を持つデータに触れる前に、アルゴリズムによって生成された抽象的な構造データ(手続き型データ)を学習させる「手続き型事前学習」という手法を提案した。この手法は、人間が高度な知識を習得する前に積み木や単純な論理を学ぶ過程を模倣しており、モデルに基礎的なアルゴリズムの足場を築くことで、その後の学習を劇的に効率化することを目的としている。 Dyckシーケンスやソート、スタック操作などの単純な規則に基づくデータを用いることで、モデルの推論スキルを大幅に強化できることが示された。具体的には、長文の文脈から情報を引き出す精度が10%から98%へと飛躍的に向上し、算術演算や論理的処理の能力も改善されることが確認された。これは、モデルが表面的なパターンに頼らず、体系的な推論手順を学習したことを示唆している。 わずか0.1%から0.3%という極めて少量の手続き型データを導入するだけで、自然言語、コード、数学といった多様なドメインでの学習効率が向上する。標準的な学習と比較して、自然言語では55%、コードでは67%、数学では86%のデータ量で同等の性能に到達することが可能となり、計算資源とデータの節約に大きく寄与する。また、この効果はモデルを微調整した後も持続することが確認された。
なぜこの問題か
現在の大規模言語モデル(LLM)の構築においては、ウェブから収集された膨大なコーパスを直接学習させることが標準的な手法となっている。しかし、このアプローチには、豊かな意味的知識の吸収と、その知識を操作するための抽象的なスキルの習得が同時に行われるという課題がある。この知識と推論能力の「絡み合い」は、モデルが体系的な推論手順を身につけるのではなく、データの統計的な表面上の特徴やヒューリスティックに依存する原因として指摘されている。モデルが単なるパターンの模倣に終始し、論理的な一貫性を欠く背景には、この学習プロセスの未分化があると考えられる。 人間の場合、高度な推論や専門知識を学ぶ前に、積み木遊びや単純な論理、数学といった基礎的な概念を学ぶ段階がある。これと同様に、言語モデルにも意味的な内容に惑わされる前に、純粋な論理構造やアルゴリズム的な「足場」が必要であると考えられる。既存の研究では、形式言語から生成されたデータが自然言語よりもトークンあたりの学習価値が高いことや、コードの学習が構成的・再帰的な推論を助けることが示唆されてきた。…
核心:何を提案したのか
本研究が提案する「手続き型事前学習」の核心は、セマンティックなデータに露出する前に、単純なアルゴリズムによって生成された「手続き型データ」を用いて言語モデルを初期訓練する手法である。この手続き型データは、形式言語やセル・オートマトン、あるいは単純な配列操作アルゴリズムによって生成される。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related