手続き型事前学習:抽象データによる言語モデルのウォーミングアップ
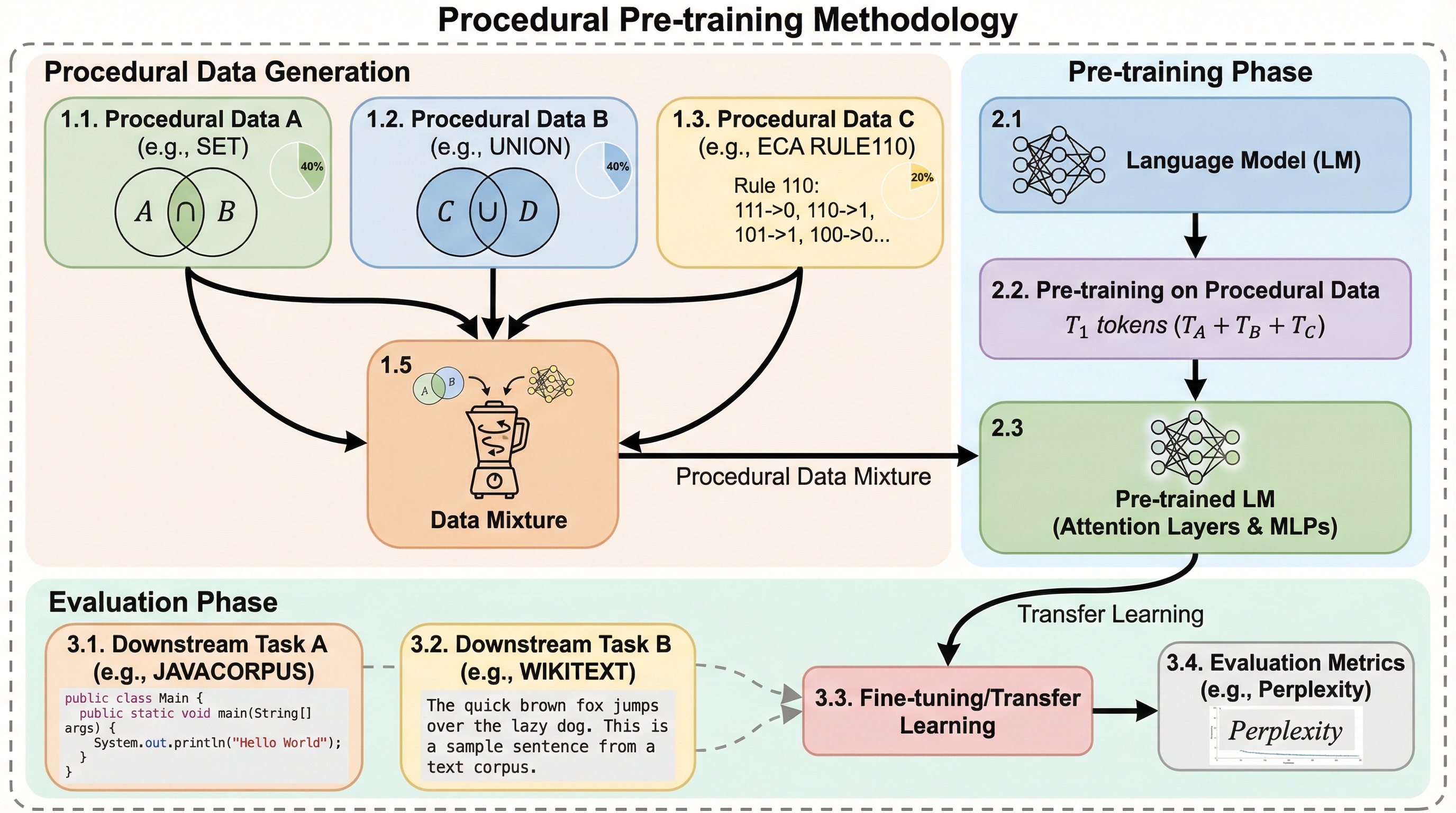
大規模言語モデルの学習において、自然言語の前に抽象的な構造を持つ「手続き型データ」を学習させる「手続き型事前学習」という手法が提案されました。この手法は、特定のアルゴリズムタスク(コンテキスト想起など)の精度を10%から98%へ劇的に向上させ、標準的な自然言語やコードの学習を大幅に加速させる効果があります。
TL;DR(結論)
大規模言語モデルの学習において、自然言語の前に抽象的な構造を持つ「手続き型データ」を学習させる「手続き型事前学習」という手法が提案されました。この手法は、特定のアルゴリズムタスク(コンテキスト想起など)の精度を10%から98%へ劇的に向上させ、標準的な自然言語やコードの学習を大幅に加速させる効果があります。事前学習で得られた知識はモデル内の特定の層(アテンション層やMLP層)に局在化しており、わずか0.1%の抽象データを追加するだけで、通常より少ないデータ量で同等の性能に到達可能です。
なぜこの問題か
現在の大規模言語モデル(LLM)の構築において、ウェブ規模の巨大なコーパスを直接学習させる手法が事実上の標準となっています。しかし、この手法には大きな課題が存在します。モデルは学習の過程で、豊かな意味的内容(セマンティック知識)の吸収と、その知識を操作するための抽象的なスキル(推論能力)の獲得を同時に行わなければなりません。この「知識と推論の絡み合い」が、現在のモデルの限界の一因であると指摘されています。モデルが体系的な推論手順を身につけるのではなく、表面的なヒューリスティック(経験則)に依存してしまう傾向があるのは、この絡み合いが原因であると考えられます。 人間の場合、高度な推論や知識の習得に挑む前に、まず単純な論理や数学、あるいはブロックを積み上げるといった基本的なゲームを通じて、アルゴリズム的な思考の足場を築きます。本研究は、この人間の学習プロセスを模倣し、言語モデルにも「ウォーミングアップ」の段階を設けることで、その後の複雑な知識獲得を容易にすることを目指しています。…
核心:何を提案したのか
本研究が提案するのは「手続き型事前学習(Procedural Pretraining)」という手法です。これは、セマンティックな意味を持たない抽象的で構造化されたデータ(手続き型データ)を、標準的な事前学習の前にモデルに提示する軽量な初期段階です。ここで言う「手続き型データ」とは、LLMによって生成された合成データとは異なり、明示的なアルゴリズムや形式言語によって生成されたデータを指します。この手法の核心は、意味的なショートカットに頼ることなく、モデルに純粋なアルゴリズム的スキルを教え込むことにあります。 具体的には、形式言語、セル・オートマトン、あるいは単純な配列操作アルゴリズムから生成されたデータを使用します。これにより、モデルは自然言語の複雑さに直面する前に、記号の操作、合成的な推論、長距離の依存関係の追跡といった基礎的な能力を「ウォーミングアップ」として習得します。このアプローチの利点は、非常に軽量であることです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related