TabClustPFN:表形式データのクラスタリングのための事前適合ネットワーク
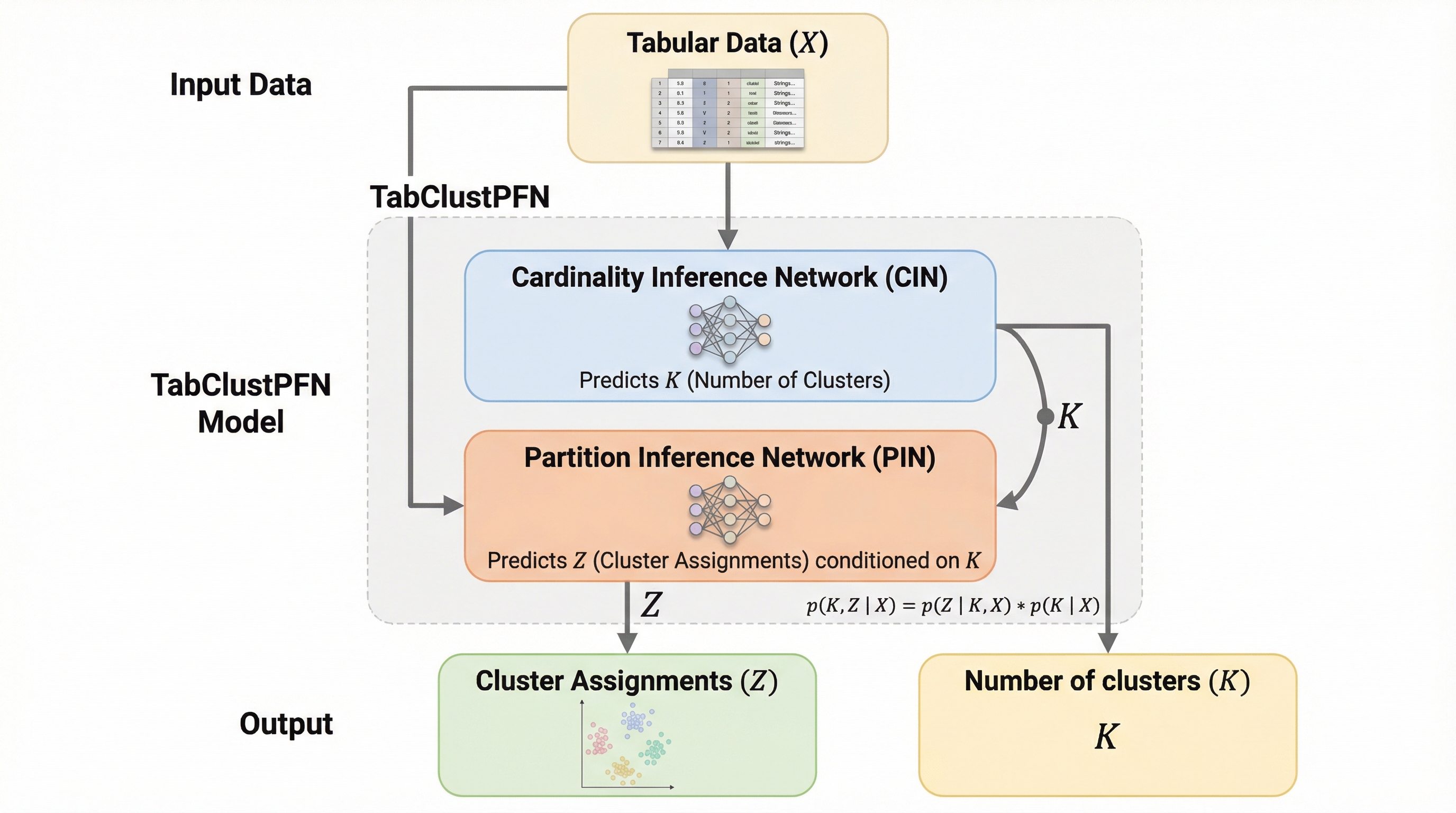
TabClustPFNは、表形式データのクラスタリングを高速かつ高精度に実行するために開発された、新しい事前適合ネットワーク(PFN)である。このモデルは、クラスタの割り当てを推論するネットワーク(PIN)とクラスタの数自体を推定するネットワーク(CIN)の2つで構成されており、事前のデータセットごとの再学習やハイパーパラメータの調整を一切必要としない。合成データを用いた大規模な事前学習により、未知のデータセットに対しても1回のフォワードパスで即座に結果を出力し、従来の古典的手法や深層学習手法を上回る性能を達成している。さらに、数値データとカテゴリデータが混在する不均一なデータ構造を自然に扱うことができ、サンプル数が1,000個程度のデータセットであれば、クラスタ数が不明な状態でもスペクトラルクラスタリングと比較して最大500倍高速に動作するという驚異的な効率性を備えている。これにより、データサイエンティストは新しいデータに対して即座に深い洞察を得ることが可能となる。
TL;DR(結論)
TabClustPFNは、表形式データのクラスタリングを高速かつ高精度に実行するために開発された、新しい事前適合ネットワーク(PFN)である。このモデルは、クラスタの割り当てを推論するネットワーク(PIN)とクラスタの数自体を推定するネットワーク(CIN)の2つで構成されており、事前のデータセットごとの再学習やハイパーパラメータの調整を一切必要としない。合成データを用いた大規模な事前学習により、未知のデータセットに対しても1回のフォワードパスで即座に結果を出力し、従来の古典的手法や深層学習手法を上回る性能を達成している。さらに、数値データとカテゴリデータが混在する不均一なデータ構造を自然に扱うことができ、サンプル数が1,000個程度のデータセットであれば、クラスタ数が不明な状態でもスペクトラルクラスタリングと比較して最大500倍高速に動作するという驚異的な効率性を備えている。これにより、データサイエンティストは新しいデータに対して即座に深い洞察を得ることが可能となる。
なぜこの問題か
表形式データは、科学研究から産業界まで幅広く遍在しており、その構造を理解するための手法としてクラスタリングは極めて重要である。理想的なクラスタリング手法は、事前の知識がなくても即座に洞察を提供できる探索的ツールであるべきだが、既存の手法には多くの課題が存在する。まず、k-meansやガウス混合モデル(GMM)のような古典的な手法は、計算効率は高いものの、データの形状に対して凸形やガウス分布といった硬直的な幾何学的仮定を置いている。DBSCANは均一な密度に依存し、階層的クラスタリングは距離尺度や連結基準の選択に敏感である。これらの手法は、実世界の表形式データが持つ多様で不均一な構造を捉えきれないことが多い。 次に、多様体学習や表現学習に基づく手法は、データをより分離しやすい潜在空間に写像するが、これらはデータセット固有の最適化問題を解く必要がある。例えば、スペクトラルクラスタリングはサンプル数に対して3次の計算複雑性を持ち、近年の深層クラスタリング手法はデータセットごとにモデルを訓練する必要があるため、計算コストが非常に高く、探索的な用途には不向きである。…
核心:何を提案したのか
本研究では、表形式データのクラスタリングのための事前適合ネットワークである「TabClustPFN」を提案している。これは、教師あり学習の分野で高い汎化性能を示したTabPFNのパラダイムをクラスタリングへと拡張したものである。TabClustPFNは、大規模な合成データセットを用いて事前学習されたトランスフォーマーモデルであり、未知のデータセットに対しても追加の学習や調整なしで、1回のフォワードパスによってクラスタ割り当てとクラスタ数の両方を推論することができる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related