安いチェックをいつ信じるか:推論における弱い検証と強い検証
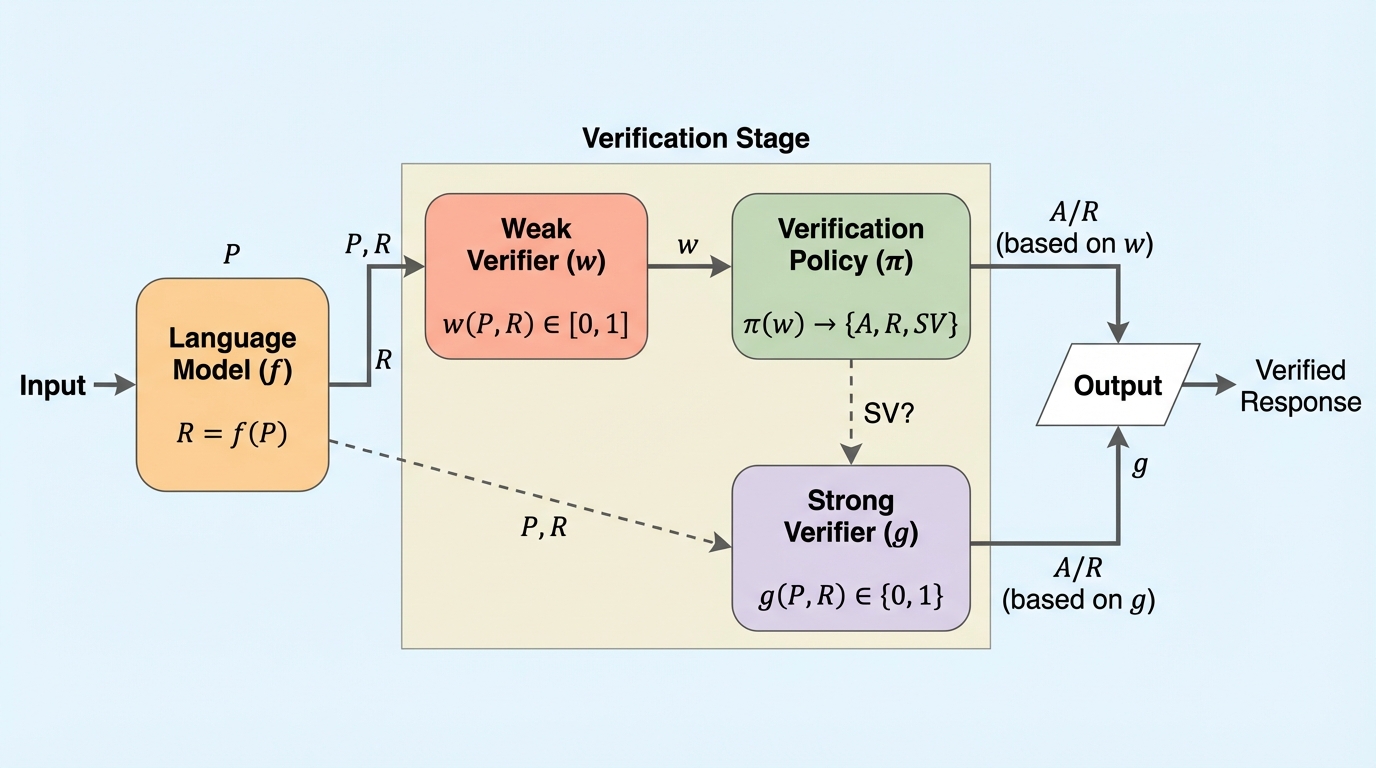
推論を含む大規模言語モデルの運用では、速くて安いが不完全な弱い検証と、信頼を確立しやすい一方で資源を要する強い検証の使い分けがボトルネックになりやすく、本論文はその緊張関係を「いつ強い検証に委ねるか」という意思決定として整理しています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
推論を含む大規模言語モデルの運用では、速くて安いが不完全な弱い検証と、信頼を確立しやすい一方で資源を要する強い検証の使い分けがボトルネックになりやすく、本論文はその緊張関係を「いつ強い検証に委ねるか」という意思決定として整理しています。
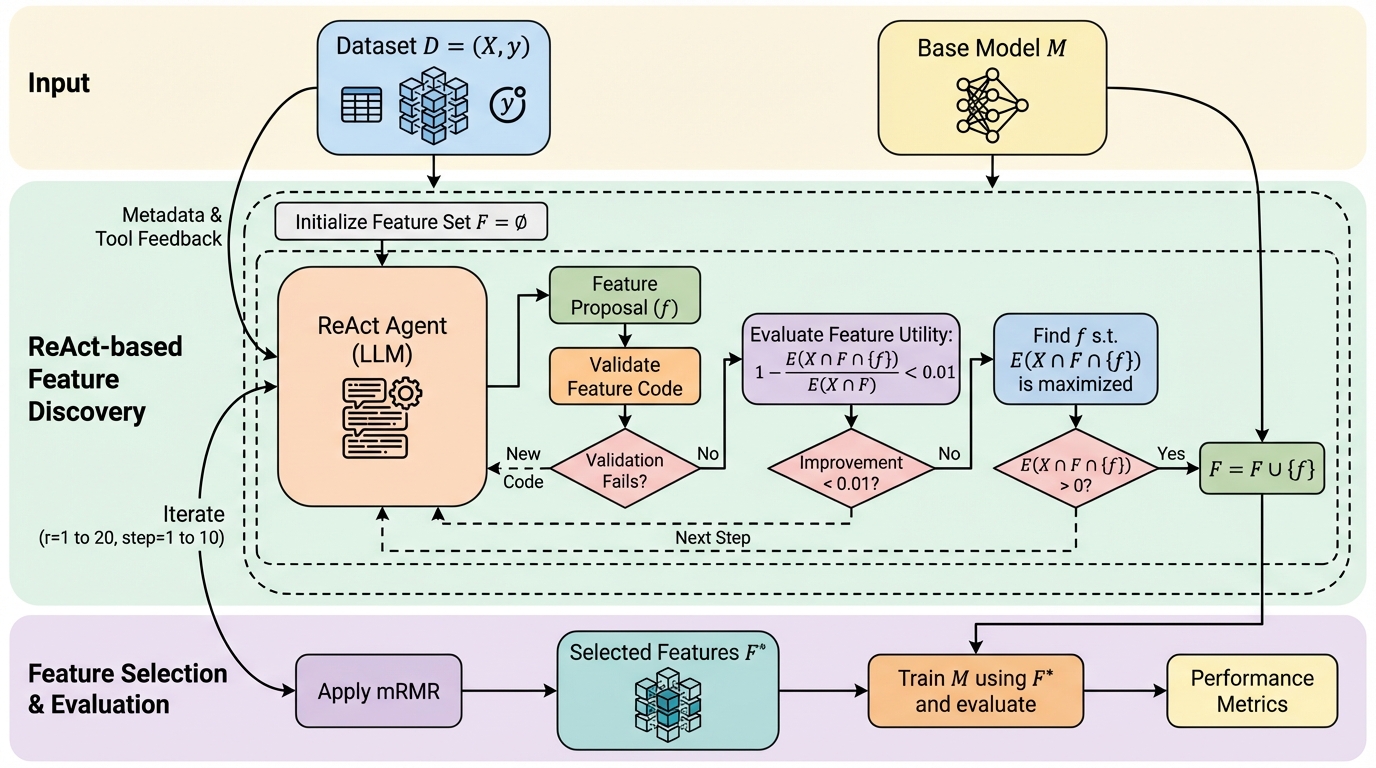
表形式データでは、モデルが比較的単純でも性能を詰めにくく、その主因になりがちな特徴量設計を、人手の直感や領域知識に頼らず進める仕組みが求められています。 / ReActの枠組みを用いたエージェントが、データを観察しながら特徴量を提案し、コード実行で妥当性を確認し、検証用データでの指標変化を見て失敗を修正し、良かった特徴量だけを段階的に蓄積していきます。 / 多数の公開データセットでの実験では、分類で最先端水準に近い性能、回帰で最先端水準の性能が報告されており、反復の履歴を文脈に残すことが創造的な特徴量の発見に効いている可能性が示されています。
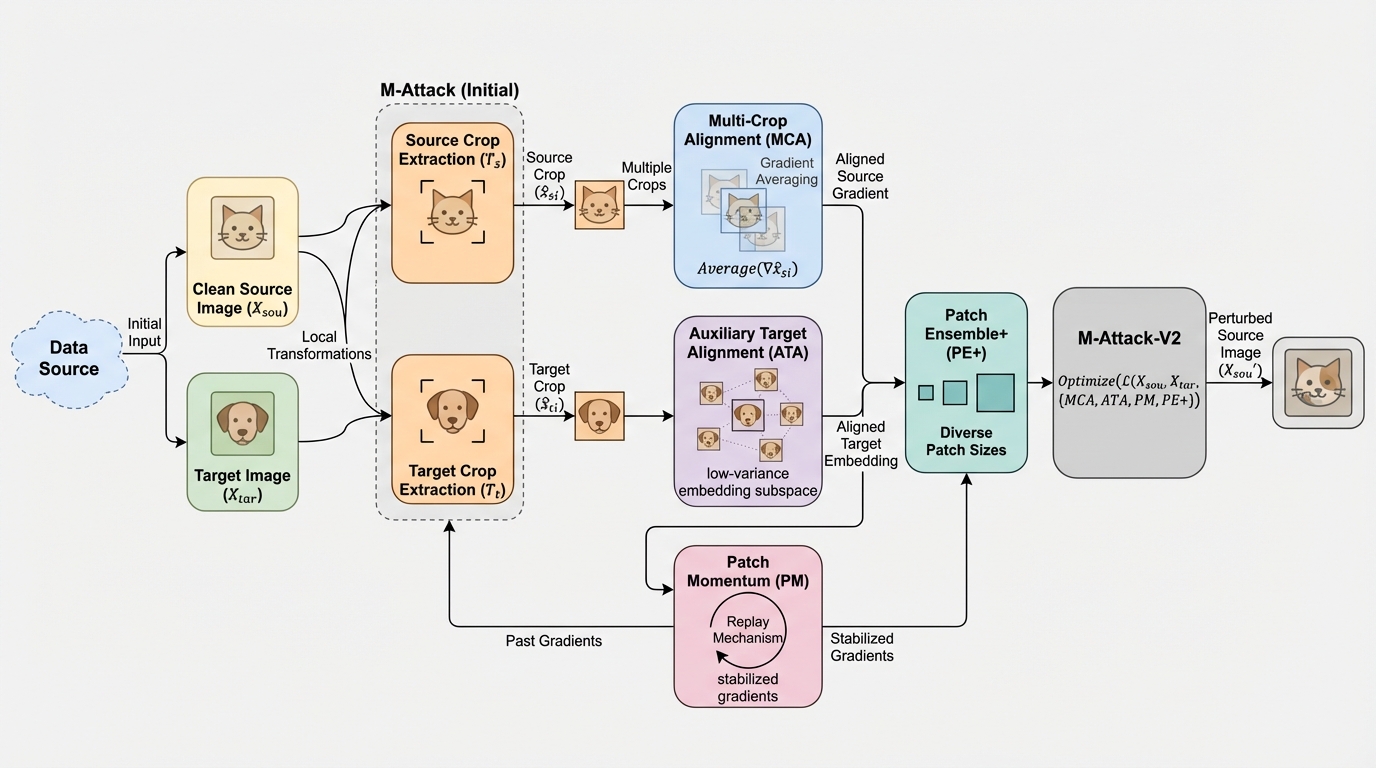
転送型ブラックボックス攻撃で強力だったM-Attackは、局所クロップ同士の一致という設計の裏側で、反復ごとに勾配が高分散になりほぼ直交して最適化が不安定になる問題があり、M-Attack-V2はこの不安定さを「勾配のデノイジング」として正面から抑える改良です。
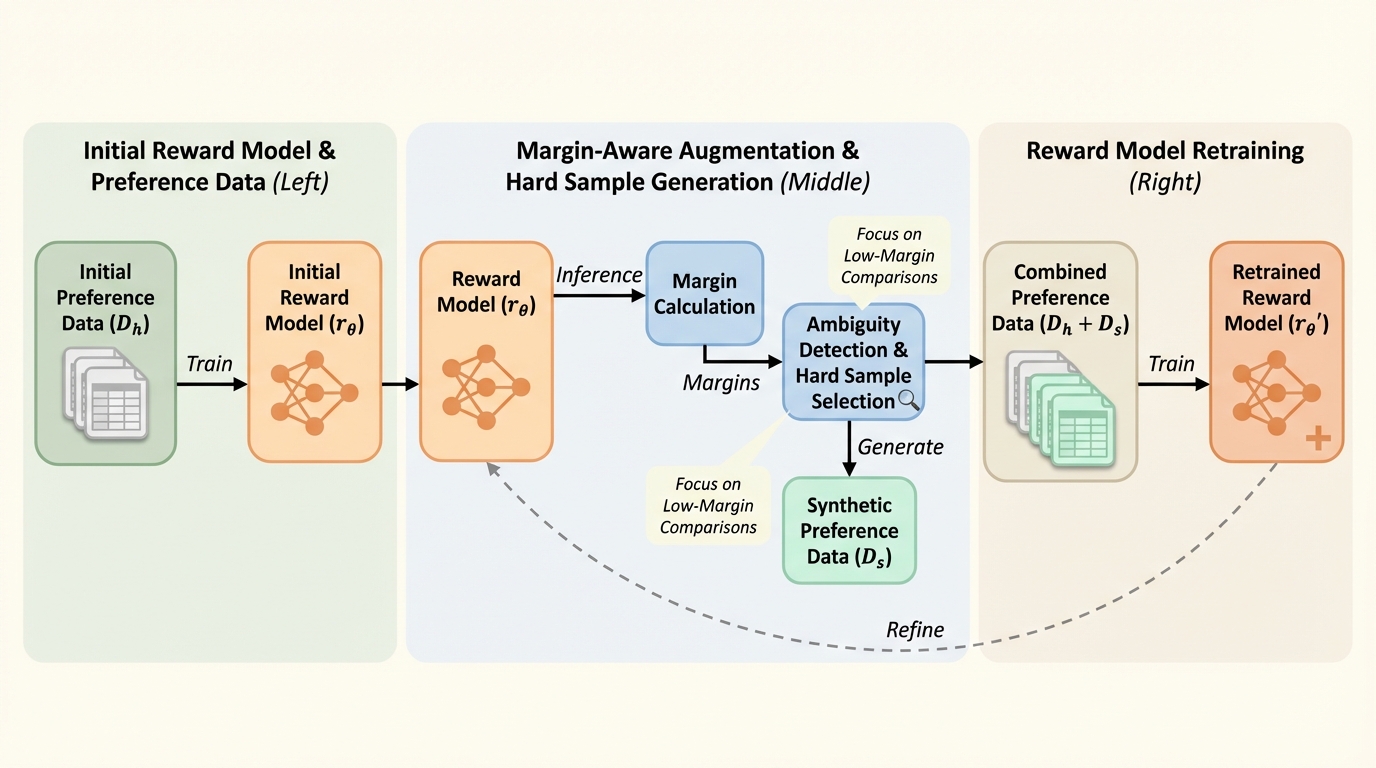
人手の選好データに強く依存する報酬モデリングでは、どの比較が「判断しにくいか」を無視して一様に増やしても、モデルの弱点に学習が届かない可能性があるため、推定が難しい領域を狙って鍛える発想が重要です。
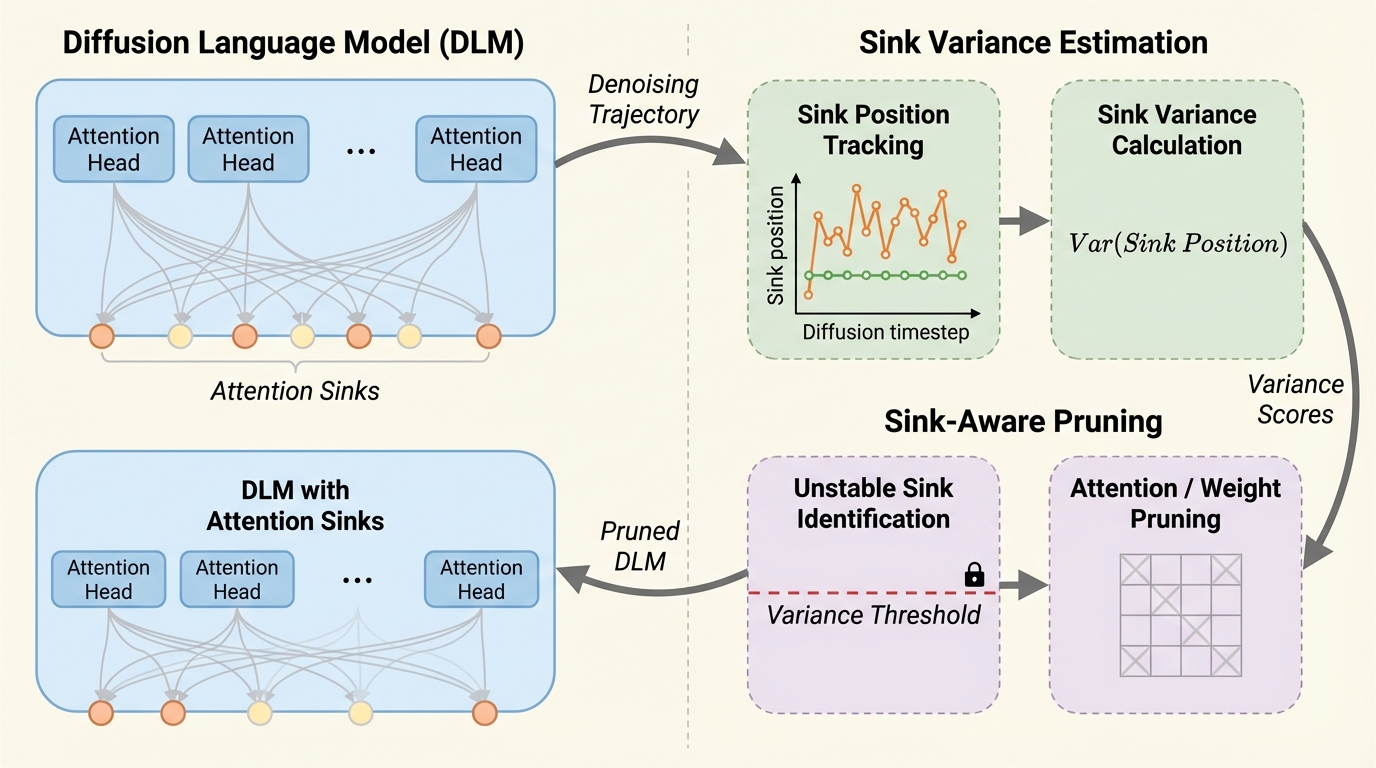
拡散言語モデル(DLMs)では、生成の反復的なデノイジング過程を通じて注意の集中先(attention sink)の位置が大きく動きやすく、自己回帰(AR)モデルで広まった「sinkは安定した錨なので残すべき」という前提がそのまま当てはまりにくいと示されています。
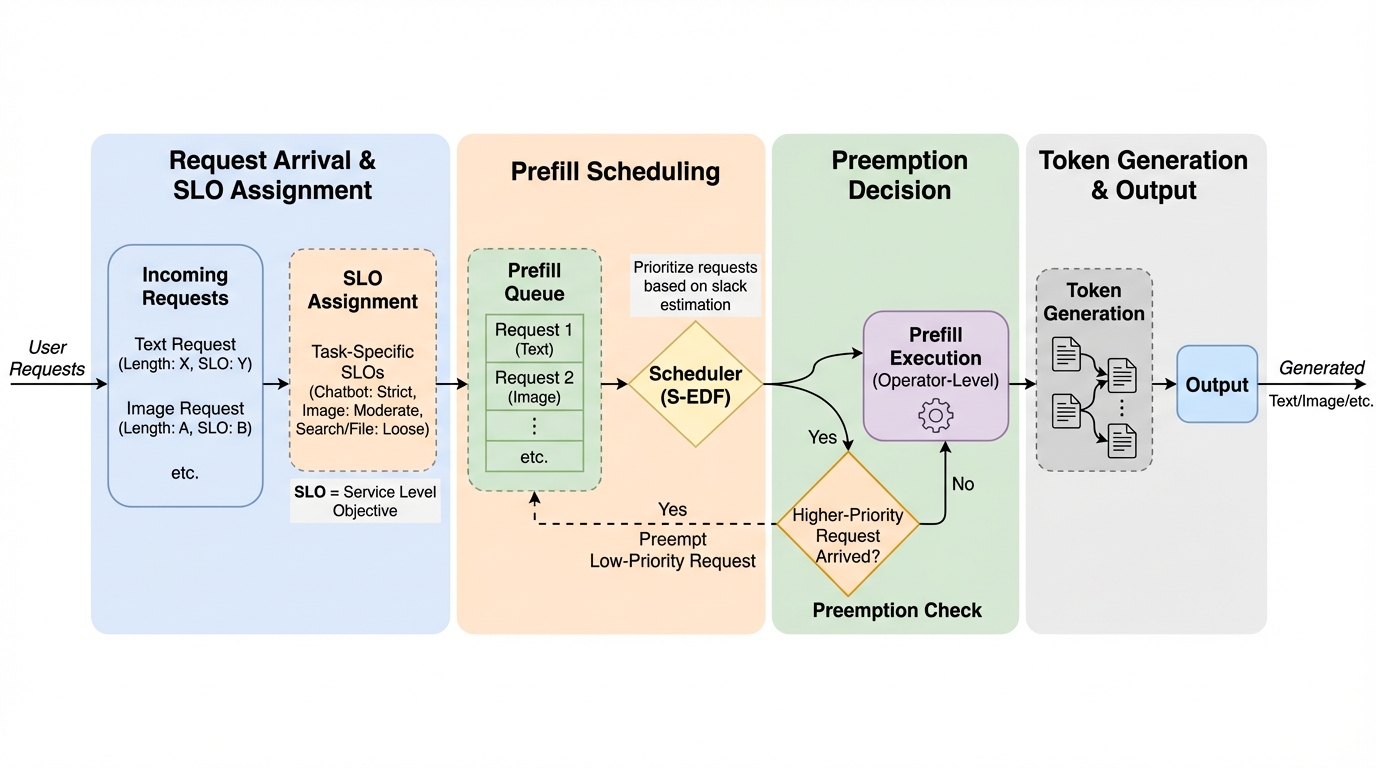
多様なSLOが混在する同時リクエスト環境では、計算集約的なプリフィルで長い入力がGPUを占有し、短く高優先度の要求まで詰まらせてTTFTのSLO違反を連鎖させやすいため、プリフィル起因のHoLブロッキング対策がサービス品質を左右します。
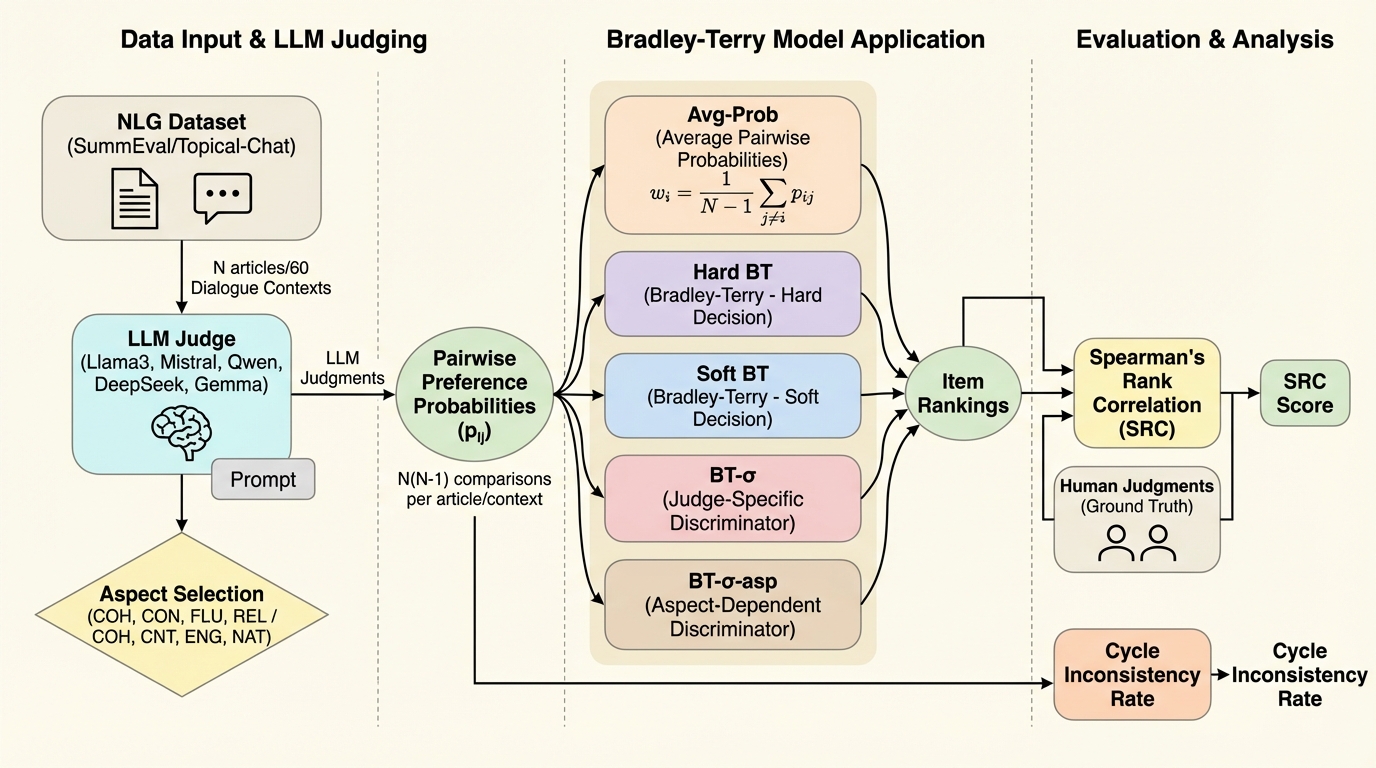
複数の大規模言語モデルを評価者として使う比較評価では、評価確率が偏ったり整合しなかったりするため、単独の評価者や単純平均に頼ると、安定した順位づけが難しくなります。 / 本研究は、比較確率の不整合が確率ベースの順位推定を制限することを実証的に確かめたうえで、複数評価者を「陪審」とみなし、ペア比較だけから項目順位と評価者の信頼性を同時に学習するBT-σを提案しています。 / 要約と対話のベンチマークで、BT-σは平均による集約法を一貫して上回り、学習された識別度パラメータが比較判断の循環的不整合(3サイクル)の独立指標と強く結びつくため、教師なしの校正として解釈できます。
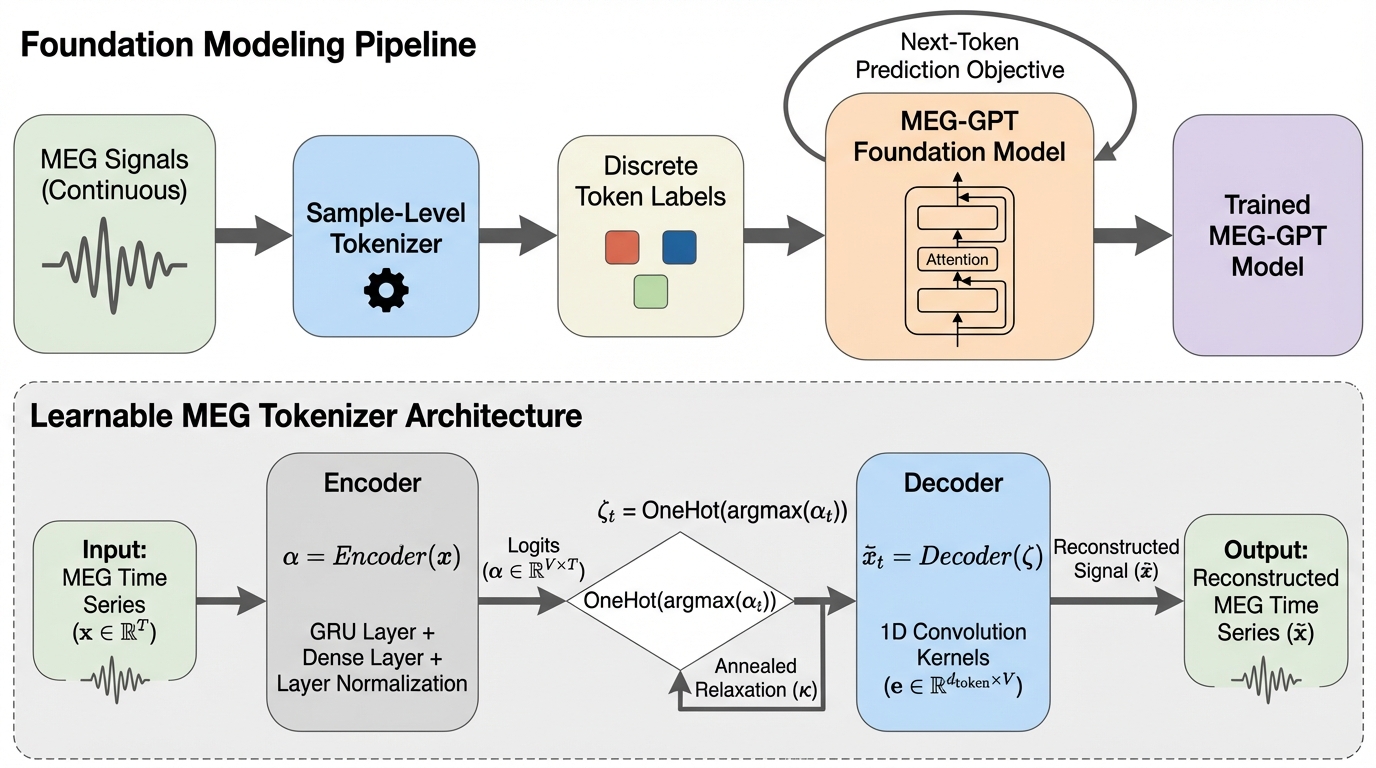
MEGの連続時系列をトランスフォーマー系の基盤モデルで扱う際のサンプルレベル「トークナイゼーション」を、学習型と非学習型で体系的に比べると、多くの評価観点では差が大きくならず、単純な固定手法でも基盤モデル開発を進められる可能性が示されました。
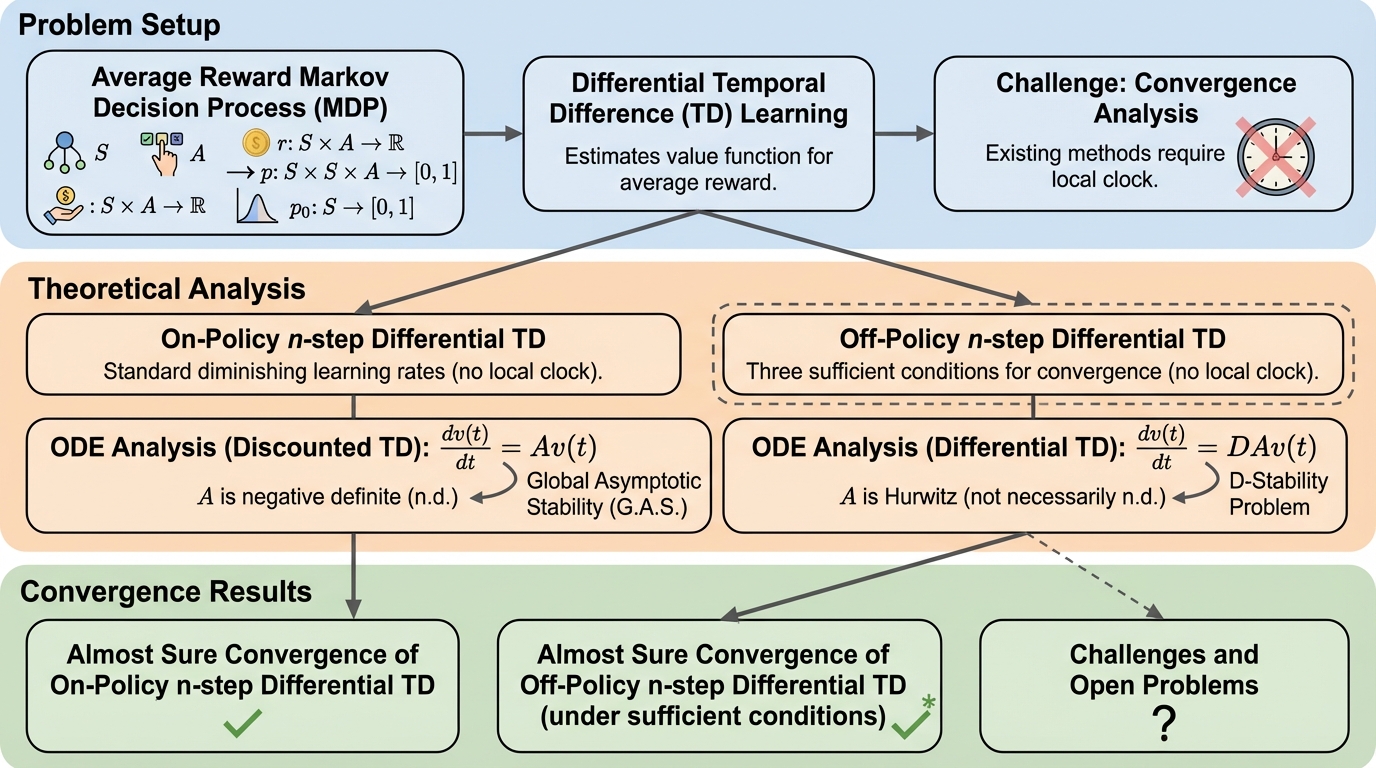
平均報酬を扱う差分TD学習について、状態訪問回数に基づく学習率調整(局所クロック)を使わない標準的な減少学習率でも、オンポリシーの$n$-step差分TDが任意の$n$でほぼ確実に収束することを示した研究です。
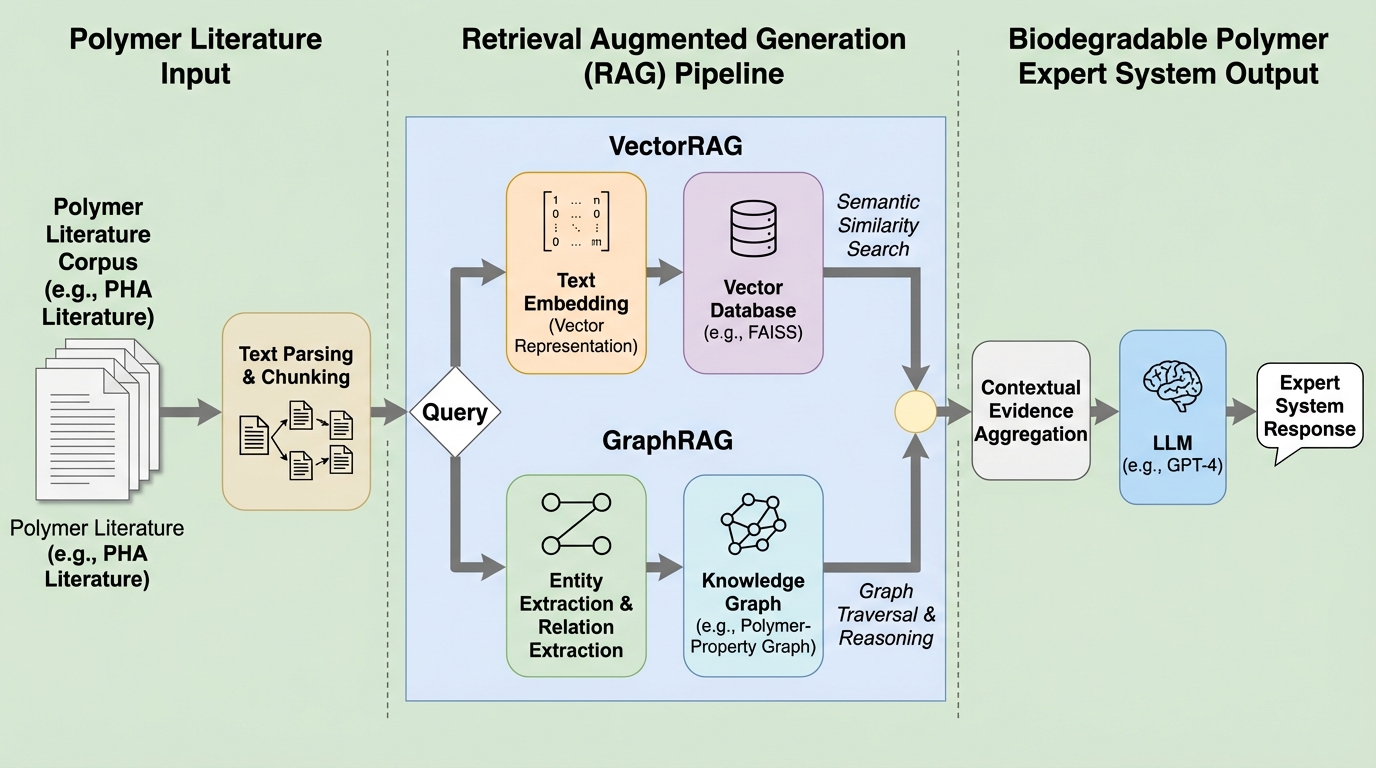
ポリマー分野の実験知は文献に大量に存在しますが、非構造テキストと用語の不一致により、研究横断で探して比べて筋道立てて考える作業が難しくなっています。 / PHA(polyhydroxyalkanoates)論文を1,000本超集めたコーパスを段落単位の根拠として整備し、意味検索に強いVectorRAGと、エンティティ正規化と多段推論を支えるGraphRAGの2系統で検索経路を作り分けています。 / 標準的な検索指標のベンチマーク、GPTやGeminiのような一般システムとの比較、化学分野の専門家による定性確認を通じて、GraphRAGは高い精度と解釈しやすさ、VectorRAGは広い再現率という補完関係が示されています。