平均報酬MDPにおける差分TD学習の「局所クロック不要」なほぼ確実収束解析
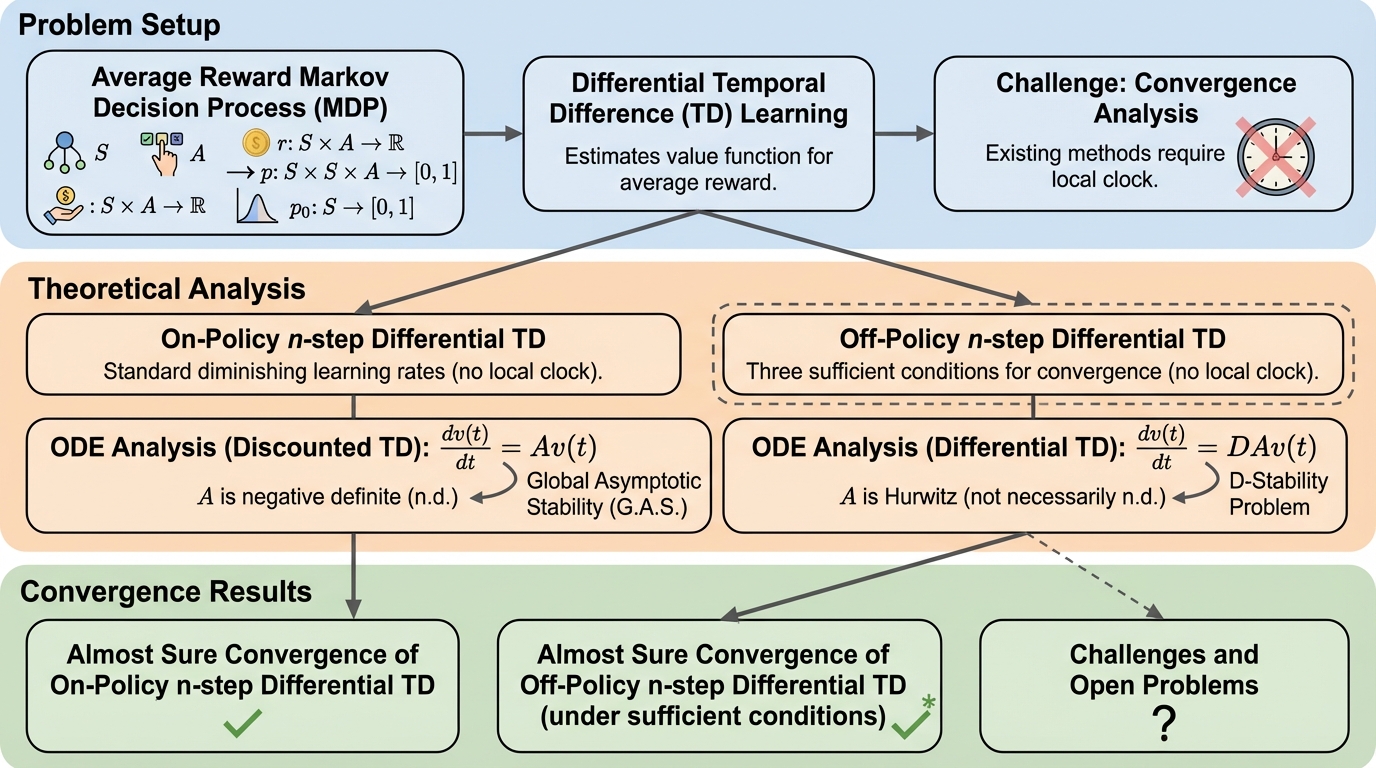
平均報酬を扱う差分TD学習について、状態訪問回数に基づく学習率調整(局所クロック)を使わない標準的な減少学習率でも、オンポリシーの$n$-step差分TDが任意の$n$でほぼ確実に収束することを示した研究です。
TL;DR(結論)
- 平均報酬を扱う差分TD学習について、状態訪問回数に基づく学習率調整(局所クロック)を使わない標準的な減少学習率でも、オンポリシーの$n$-step差分TDが任意の$n$でほぼ確実に収束することを示した研究です。
- $n$-step差分TDを定式化したうえで、更新式を確率近似として書き換え、期待更新が導く常微分方程式の大域的漸近安定性を、行列の正安定性やM行列に関する補題を用いて押さえる構成になっています。
- さらにオフポリシーでも局所クロックなしで収束するための十分条件を三つ導出し、平均報酬強化学習の収束解析を、実務で広く使われる学習率設定や特徴量のみが観測される状況に近づけています。
なぜこの問題か
平均報酬は、強化学習においてエージェントの長期的な振る舞いを重視する性能指標として位置付けられています。本文抜粋では、割引総報酬がよく使われる一方で、平均報酬の枠組みがネットワーク資源配分、ロボティクス、スケジューリングのような応用で特に適していることが動機として述べられています。こうした設定で方策評価をオンラインに進める手段として、平均報酬に対応する価値関数(バイアス)を推定する差分TD学習が重要であり、オンポリシーとオフポリシーの両方に適用できる点も利点として示されています。 一方で、既存の収束保証が実装実務とずれていることが、本研究の中心的な問題意識です。本文抜粋では、先行研究(Wanら)におけるほぼ確実収束が、学習率を「局所クロック」、すなわち各状態の訪問回数カウンタに結び付けた形でしか示されていないと説明されています。この局所クロックが不満足な理由として、少なくとも三点が挙げられています。第一に、実務では局所クロック付き学習率がほとんど使われず、先行研究の実験でも使われていないという指摘です。…
核心:何を提案したのか
本研究の提案は、平均報酬MDPに対する差分TD学習の収束保証を、局所クロックに依存しない形へ進めた点にあります。Abstractでは、標準的な減少学習率(時刻$t$にのみ依存する、確率近似で一般的に用いられる仮定を満たす学習率列)を用い、局所クロックなしでオンポリシーの$n$-step差分TDが任意の$n$についてほぼ確実に収束することを証明したと述べられています。これにより、先行研究で理論上は必要とされていた「状態ごとの訪問回数に応じた学習率」を使わなくてもよい、という主張が理論的に裏付けられます。 加えて、オフポリシーの$n$-step差分TDについても、局所クロックなしでほぼ確実収束するための十分条件を三つ導出した点が貢献として挙げられています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related