FAMOSE:ReActにもとづく自動特徴量発見フレームワークの提案
表形式データでは、モデルが比較的単純でも性能を詰めにくく、その主因になりがちな特徴量設計を、人手の直感や領域知識に頼らず進める仕組みが求められています。 / ReActの枠組みを用いたエージェントが、データを観察しながら特徴量を提案し、コード実行で妥当性を確認し、検証用データでの指標変化を見て失敗を修正し、良かった特徴量だけを段階的に蓄積していきます。 / 多数の公開データセットでの実験では、分類で最先端水準に近い性能、回帰で最先端水準の性能が報告されており、反復の履歴を文脈に残すことが創造的な特徴量の発見に効いている可能性が示されています。
TL;DR(結論)
- 表形式データでは、モデルが比較的単純でも性能を詰めにくく、その主因になりがちな特徴量設計を、人手の直感や領域知識に頼らず進める仕組みが求められています。
- ReActの枠組みを用いたエージェントが、データを観察しながら特徴量を提案し、コード実行で妥当性を確認し、検証用データでの指標変化を見て失敗を修正し、良かった特徴量だけを段階的に蓄積していきます。
- 多数の公開データセットでの実験では、分類で最先端水準に近い性能、回帰で最先端水準の性能が報告されており、反復の履歴を文脈に残すことが創造的な特徴量の発見に効いている可能性が示されています。
なぜこの問題か
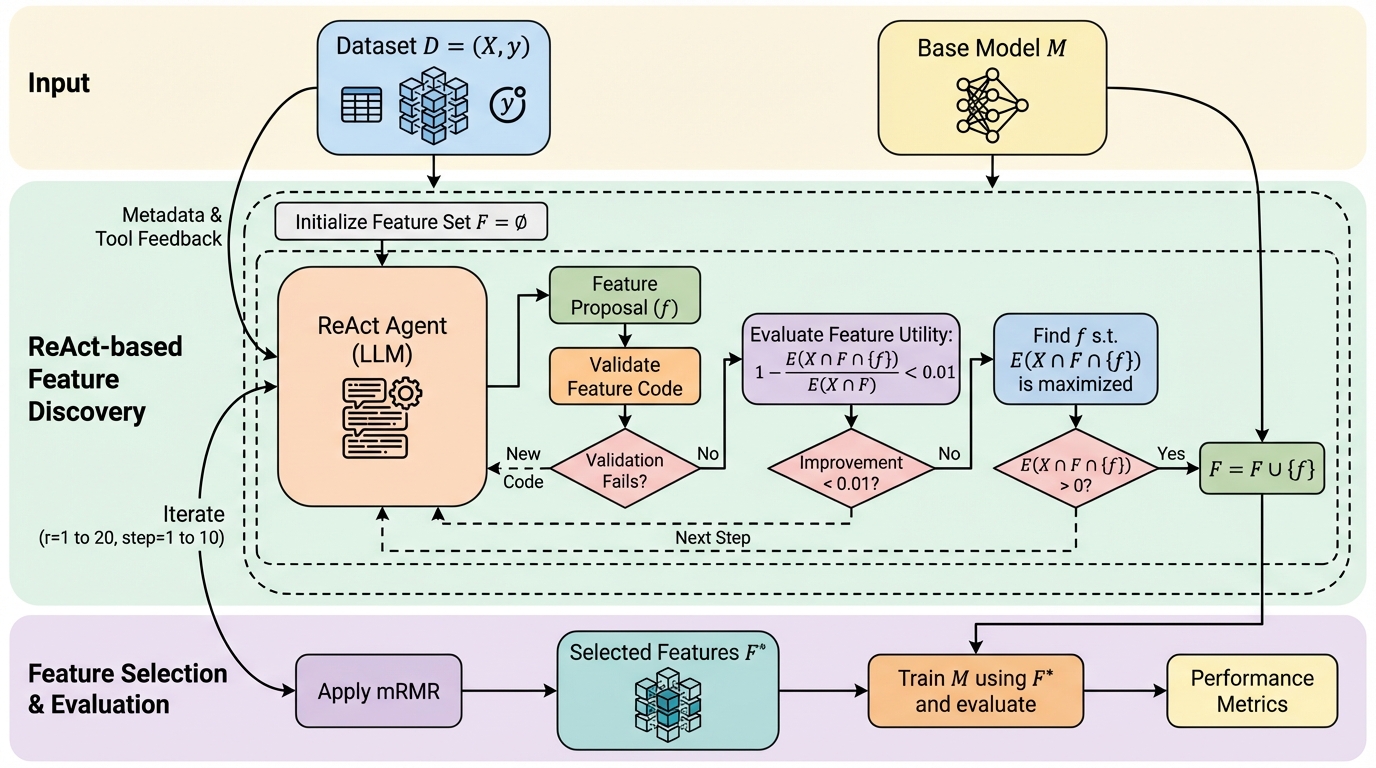
表形式データの学習では、扱うモデルが比較的単純であっても、最終的な性能最適化が難しいと繰り返し述べられています。性能を左右する要因の中でも、既存の属性を変換したり組み合わせたりして有用な特徴量を見つける工程は、実務でも研究でも大きな負担になりやすいです。理由は明確で、候補となる新しい特徴量の空間が組合せ的に膨れ上がる一方で、実際に役立つものはごく一部に限られるためです。結果として、どの変換が効くかを見抜くには人間の直感やドメイン知識が必要になり、試行錯誤に時間がかかりがちです。 この負担を減らすため、OpenFEのようなアルゴリズム主導の自動特徴量設計や、CAAFEのような大規模言語モデルを用いた特徴量生成が提案されてきました。しかし、いずれの方向性でも「評価すべき候補が多すぎる」という根本問題は残りやすいです。特に大規模言語モデルを使う方法は、テンプレートや一回の生成に寄りやすく、生成後に外部で評価して終わる流れになりがちです。その場合、モデル自身が失敗から学んで修正し、次の案に反映する「反復的な特徴量の改良」が十分に行われません。…
核心:何を提案したのか
本研究が提案するのは、FAMOSE(Feature AugMentation and Optimal Selection agEnt)という自動特徴量発見のフレームワークです。特徴は、ReActの考え方にもとづくエージェント構成により、特徴量の「探索・生成・改良」を自律的に反復し、その過程に評価と選択の道具を組み込んでいる点です。著者らの主張として、回帰と分類の両方を対象に、エージェント型のReAct枠組みを自動特徴量設計へ適用した初めての例であると位置づけています。 FAMOSEは、単に新しい特徴量候補を生成するだけではなく、提案した特徴量が実データ上で有効かどうかを検証し、うまくいかなければコードや内容を修正して作り直すという、試行錯誤の循環を内側に持ちます。さらに、各ラウンドの最後に「性能を改善した最良の特徴量」が保存され、次のラウンドでは過去に採用された特徴量群も含めた条件付きで新しい候補を評価します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related