MEG基盤モデルにおけるサンプルレベルトークナイゼーション戦略の体系評価
MEGの連続時系列をトランスフォーマー系の基盤モデルで扱う際のサンプルレベル「トークナイゼーション」を、学習型と非学習型で体系的に比べると、多くの評価観点では差が大きくならず、単純な固定手法でも基盤モデル開発を進められる可能性が示されました。
TL;DR(結論)
- MEGの連続時系列をトランスフォーマー系の基盤モデルで扱う際のサンプルレベル「トークナイゼーション」を、学習型と非学習型で体系的に比べると、多くの評価観点では差が大きくならず、単純な固定手法でも基盤モデル開発を進められる可能性が示されました。
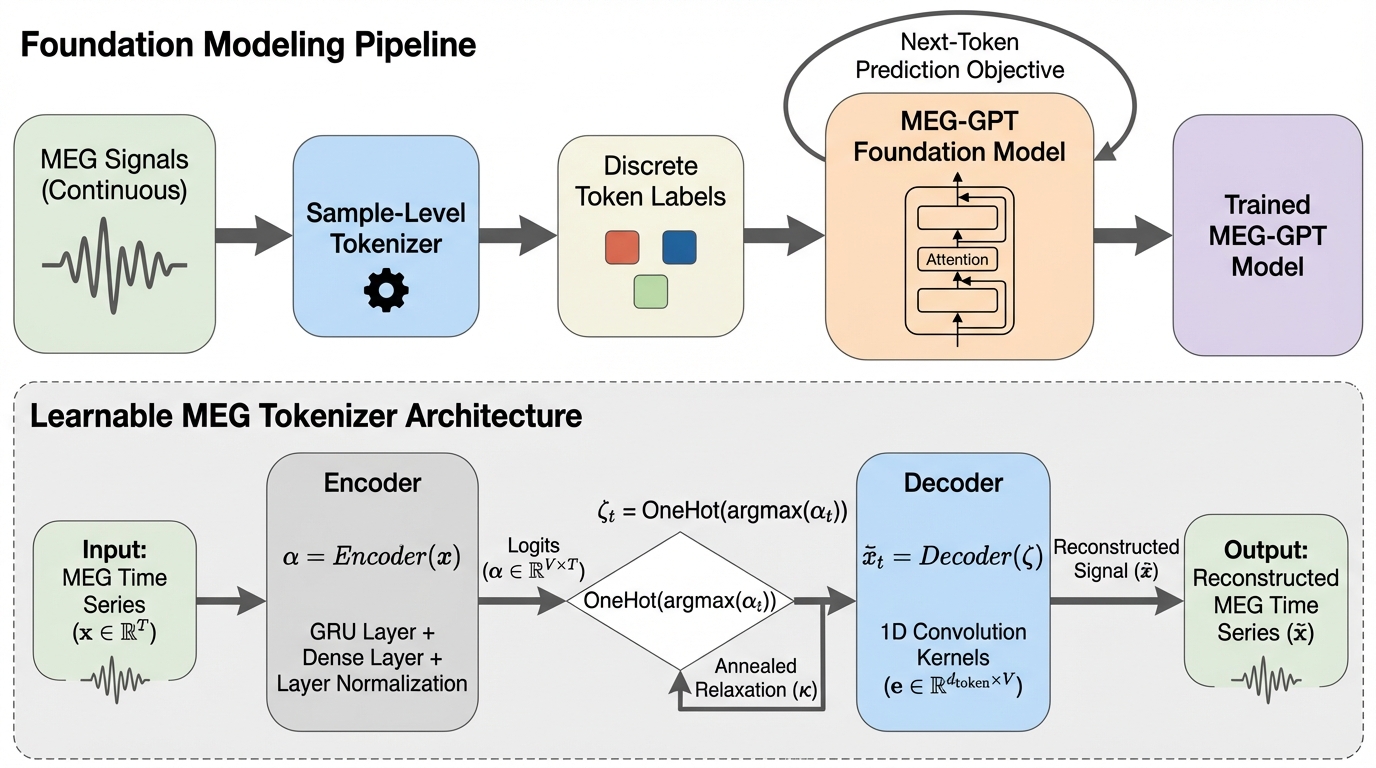
- 信号を離散トークン列に変換する方法として、オートエンコーダに基づく学習型トークナイザを新たに用意し、固定量子化(例として平均スケーリング+一様ビニング、神経信号向けの標準化+分位点ビニング、μ-law compandingなど)と同じ土俵で、復元精度と事前学習後のモデル挙動を3つの公開MEGデータセットで検証しました。
- その結果、復元精度が高いことに加えて、次トークン予測や生成データの生物学的もっともらしさ、下流デコーディング(ゼロショットと微調整)では概ね同程度でしたが、被験者フィンガープリンティングでは学習型が改善する傾向が報告され、目的に応じた選択が重要だと分かりました。
なぜこの問題か
自然言語処理や視覚分野での基盤モデルの成功を受けて、神経画像データでも大規模な基盤モデルを作り、少量のラベルや課題情報に依存せずに汎用表現を学習したいという関心が高まっています。特にEEGやMEGは時間分解能が高く、多変量で長い時系列になりやすいため、自己教師ありで大規模事前学習を行う発想と相性がよいとされています。一方で、トランスフォーマー系のモデルを適用するには、連続値の時系列を離散的な記号列に変換する「トークナイゼーション」が設計上の中心になります。ここでのトークン化は単なる前処理ではなく、表現の粒度やモデルに入る帰納バイアスを左右し、結果として下流性能や生成挙動まで影響し得る部品です。 しかし、神経信号向けにどのトークナイゼーションが望ましいのか、またその違いが何にどの程度効くのかは十分に整理されていません。一般の時系列向けに発展した方法は、小売・金融・疫学などを想定しており、振動ダイナミクスやスペクトル構造、振幅分布が概ねガウス的と述べられる神経信号の性質と一致するとは限りません。適切でないトークン化は、生物学的に意味のある構造を見えにくくしたり、データの統計性質に合わない仮定を押し付けたりするおそれがあります。…
核心:何を提案したのか
本研究の提案は、MEG向けのトランスフォーマーベース大規模神経画像モデル(Large Neuroimaging Models)を想定し、サンプルレベルのトークナイゼーションを同一の枠組みで比較評価する、という実験設計そのものにあります。評価は大きく二軸で、第一に「連続信号を離散空間へ写すときの情報損失の小ささ」を信号復元の精度で測り、第二に「そのトークン列で基盤モデルを事前学習したときの挙動」を多面的に調べます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related