LLM評価は誰を信じるべきか:比較評価のための「LLM陪審」とBT-σによる信頼性推定
複数の大規模言語モデルを評価者として使う比較評価では、評価確率が偏ったり整合しなかったりするため、単独の評価者や単純平均に頼ると、安定した順位づけが難しくなります。 / 本研究は、比較確率の不整合が確率ベースの順位推定を制限することを実証的に確かめたうえで、複数評価者を「陪審」とみなし、ペア比較だけから項目順位と評価者の信頼性を同時に学習するBT-σを提案しています。 / 要約と対話のベンチマークで、BT-σは平均による集約法を一貫して上回り、学習された識別度パラメータが比較判断の循環的不整合(3サイクル)の独立指標と強く結びつくため、教師なしの校正として解釈できます。
TL;DR(結論)
- 複数の大規模言語モデルを評価者として使う比較評価では、評価確率が偏ったり整合しなかったりするため、単独の評価者や単純平均に頼ると、安定した順位づけが難しくなります。
- 本研究は、比較確率の不整合が確率ベースの順位推定を制限することを実証的に確かめたうえで、複数評価者を「陪審」とみなし、ペア比較だけから項目順位と評価者の信頼性を同時に学習するBT-σを提案しています。
- 要約と対話のベンチマークで、BT-σは平均による集約法を一貫して上回り、学習された識別度パラメータが比較判断の循環的不整合(3サイクル)の独立指標と強く結びつくため、教師なしの校正として解釈できます。
なぜこの問題か
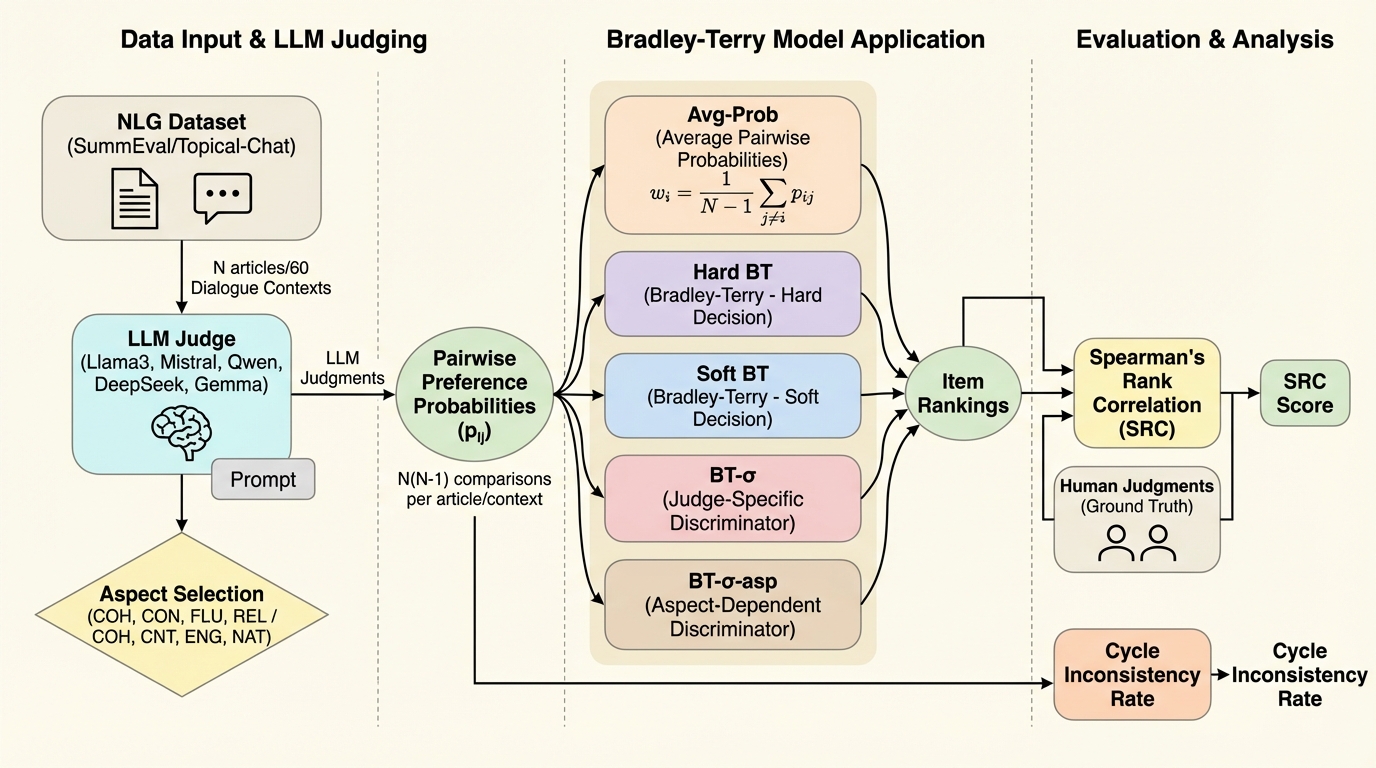
大規模言語モデル(LLM)を自然言語生成(NLG)の自動評価に使う場面が増えており、とくに候補を2つ並べて「どちらが良いか」を問うペア比較は、絶対スコアよりも安定しやすい枠組みとして広く用いられています。ところが、LLMを評価者(LLM-as-a-judge)として用いると、評価者が常に信頼できるとは限らず、タスクや観点によって性能や一貫性が大きく変わることがあります。さらに、LLMが返す「どちらが勝つ確率」は、自己選好バイアスや冗長性バイアス、プロンプトの言い回しや提示形式への感度などの影響を受けやすく、確率が偏ったり、論理的な整合性が崩れたりします。 実運用では、評価者を1つに固定するか、複数評価者の確率や投票を単純に平均することが多いですが、これは「全員が同程度に信頼できる」という仮定を暗に置いてしまいます。実際には、評価者の中にノイズの大きいモデルが混ざることがあり、平均との差分が埋もれてしまうと、集約結果が不安定になり得ます。また、人手ラベルを用意して評価者を校正する方法も考えられますが、参照なし評価では、人手ラベルがそもそも存在しない、あるいは十分に集められない状況が起こり得ます。…
核心:何を提案したのか
本研究は、複数のLLM評価者を同時に用いる状況をLLM-as-a-jury(LLM陪審)として定式化し、ペア比較の観測だけから「項目の順位」と「評価者の信頼性」を同時に推定する確率モデルBT-σを提案しています。土台はBradley–Terry(BT)モデルであり、項目ごとに潜在スコアを置いて、2項目の差から「どちらが好まれるか」の確率を表します。提案の新規性は、評価者ごとに識別度を表すパラメータ(論文ではσで表されます)を導入し、同じ項目差であっても、評価者により確率がどれだけ鋭く出るか、あるいはどれだけ鈍ってノイズ的になるかを明示的に表現できる点にあります。 重要なのは、BT-σが教師なしで動くように設計されていることです。温度スケーリングのような確率校正はラベル付きデータを必要としますが、本研究では人手ラベルが利用できない場合を想定し、比較データのみから評価者の相対的な信頼性を学習します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related