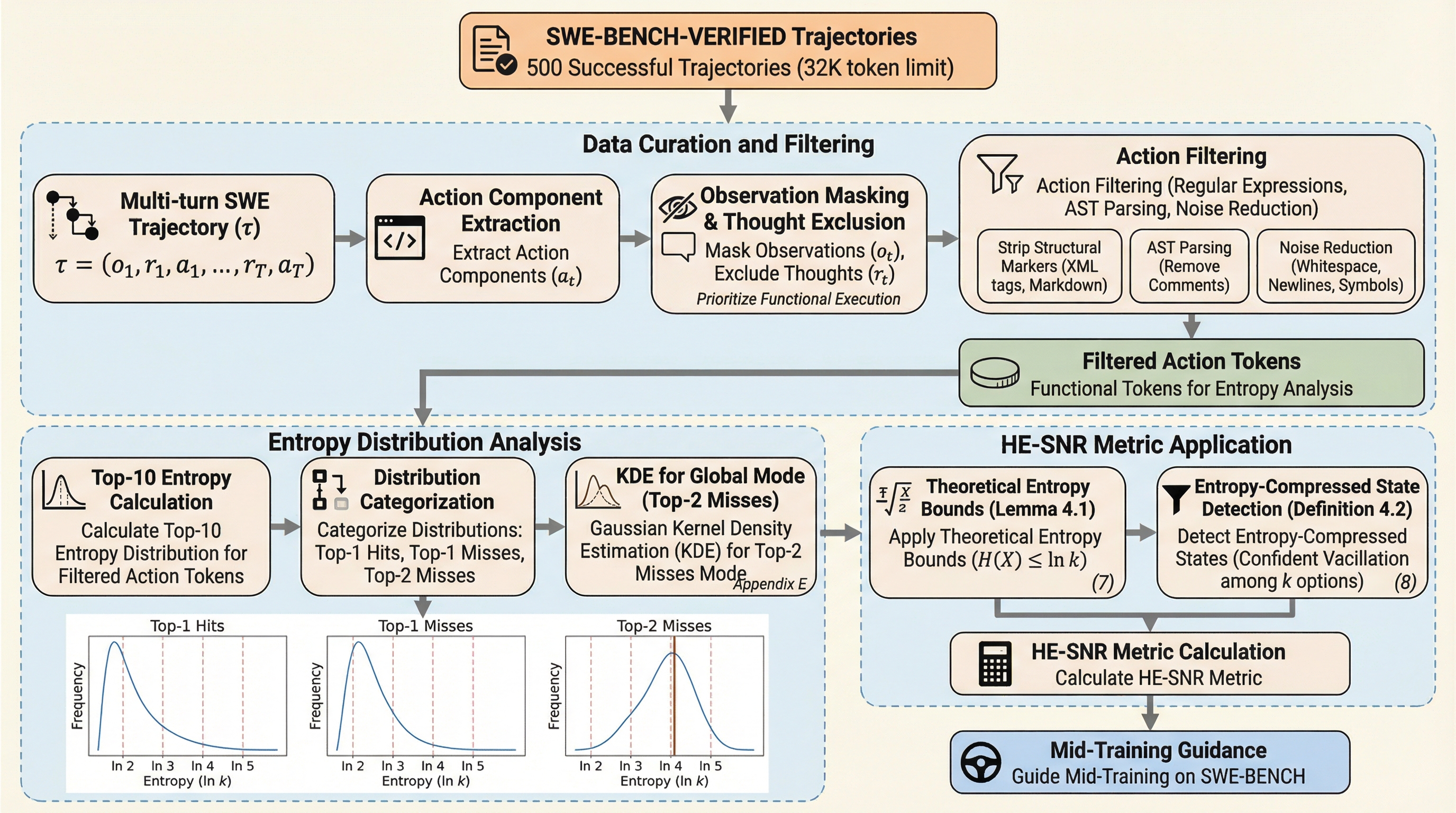
HE-SNR:エントロピーによって潜在的な論理を解明し、SWE-benchにおける中間学習を導く
ソフトウェアエンジニアリング能力を評価する最難関ベンチマークであるSWE-benchにおいて、モデルの中間学習(Mid-Training)段階での潜在能力を正確に測定するための新しい指標として、エントロピー圧縮仮説に基づく「HE-SNR(高エントロピー信号対雑音比)」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ソフトウェアエンジニアリング能力を評価する最難関ベンチマークであるSWE-benchにおいて、モデルの中間学習(Mid-Training)段階での潜在能力を正確に測定するための新しい指標として、エントロピー圧縮仮説に基づく「HE-SNR(高エントロピー信号対雑音比)」が提案されました。
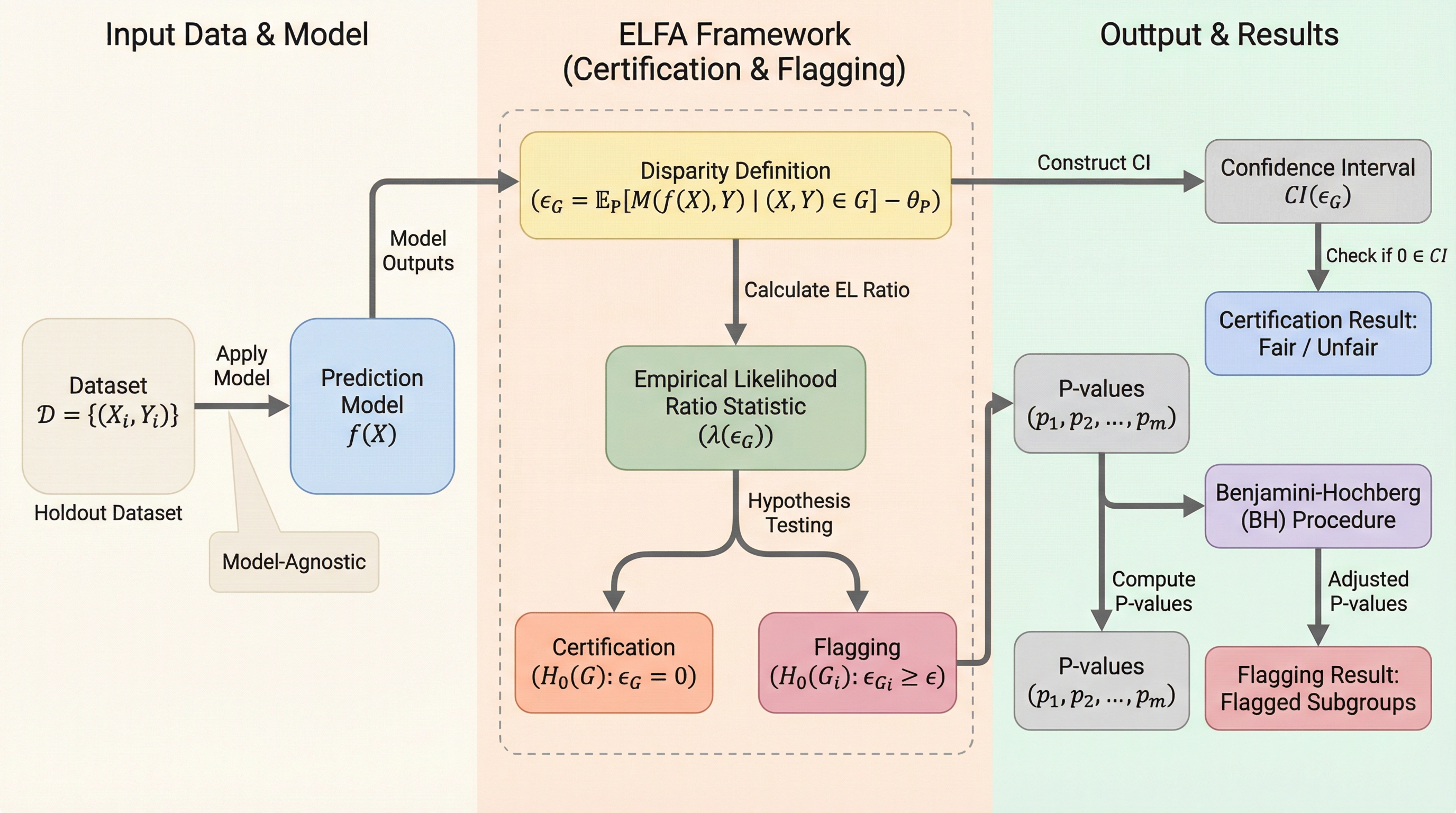
AIモデルのバイアスを検出するための新しい統計的枠組み「ELF A」を提案します。この手法は、データの背後にある分布を仮定しない非パラメトリックなアプローチであり、従来のブートストラップ法に比べて計算速度が数千倍から数万倍速く、統計的な正確性も高いという特徴があります。
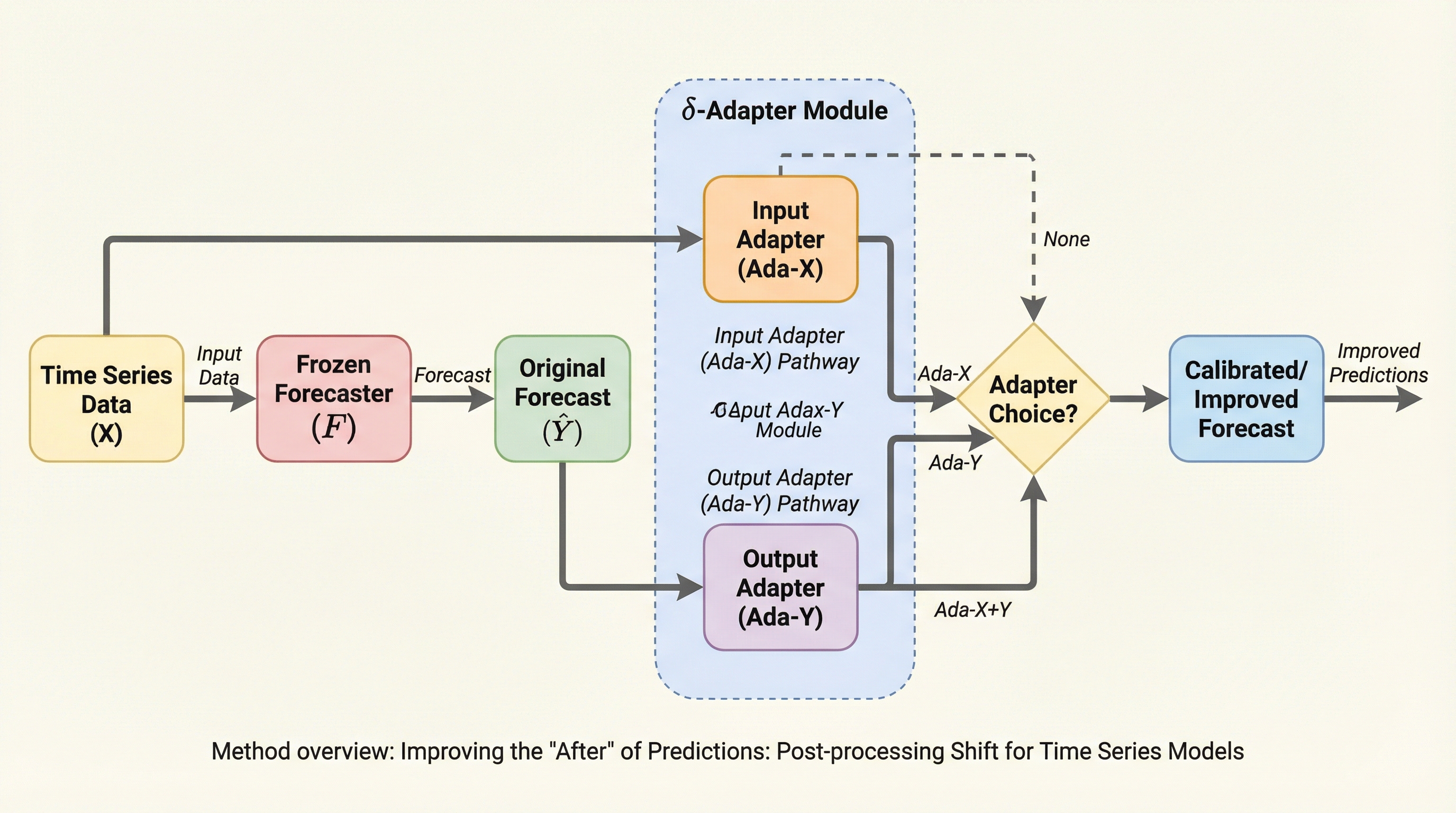
時系列予測においてモデル構造の改善による精度向上が飽和しつつある中、既存の学習済みモデルを一切再学習・変更することなく、入力データの微調整と出力の残差修正という2つの軽量な後処理モジュールを追加することで、予測精度と不確実性の評価を一貫して向上させるフレームワーク「$\delta$-Adapter」が提案されました。
トランスフォーマー型大規模言語モデルのアテンション層が、人間の記憶システムと同様の役割を担っていることを明らかにしました。具体的には、クエリが検索の文脈を符号化し、キーが記憶のインデックスとして機能し、バリューが実際の内容を保持するという明確な役割分担が存在します。
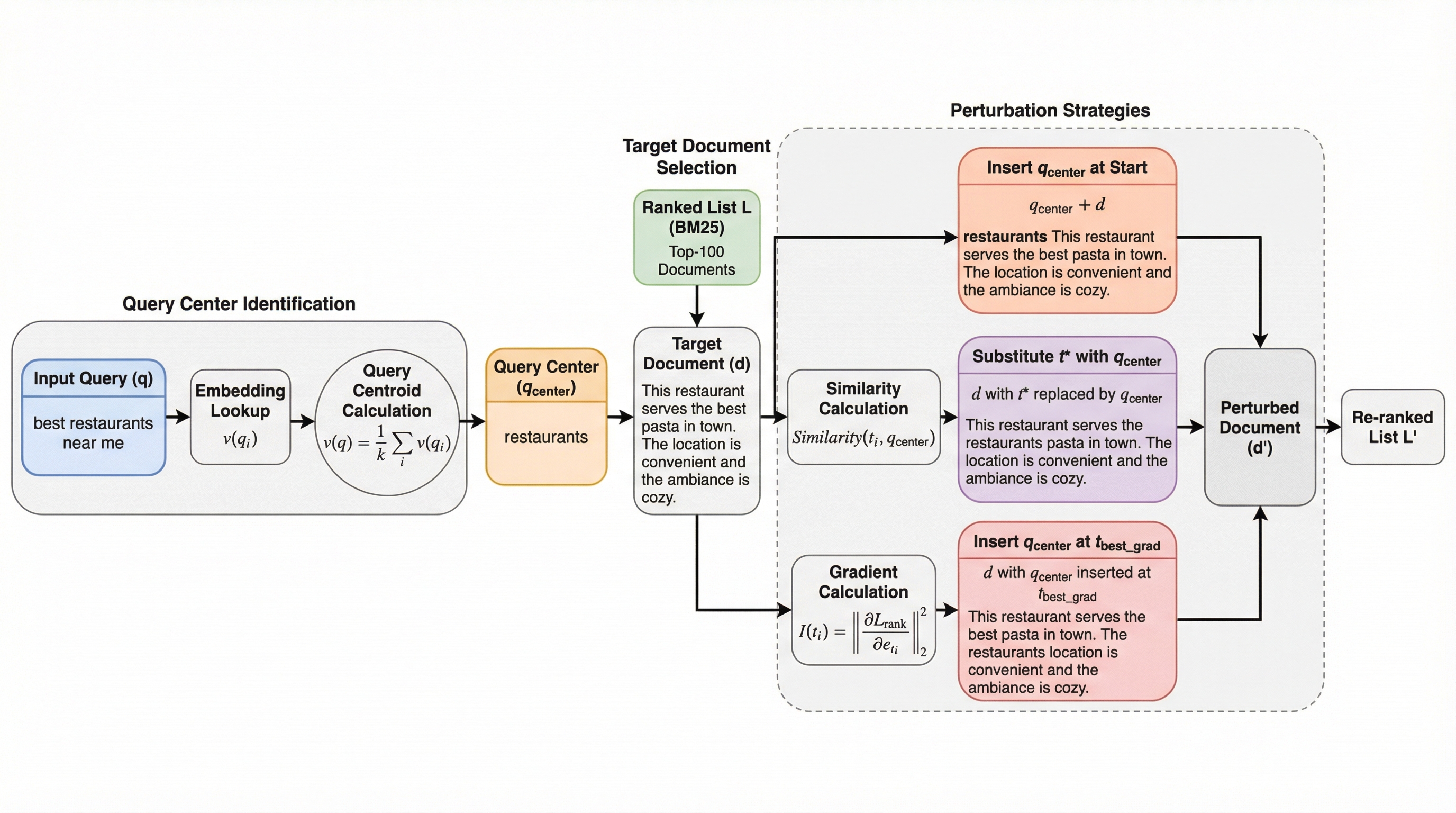
ニューラルランキングモデル(NRM)は、クエリに関連する特定の1単語を挿入または置換するだけで、検索順位を大幅に操作される脆弱性があることが明らかになりました。 本研究では「クエリセンター」という概念を導入し、ヒューリスティックな手法や勾配を用いた手法によって、わずか1トークンの変更で最大91%の攻撃成功率を達成しています。 特に検索順位の中間に位置する文書が最も攻撃に対して脆弱である「ゴルディロックス・ゾーン」の存在が確認され、既存のランキングモデルの堅牢性に重大な課題を投げかけています。
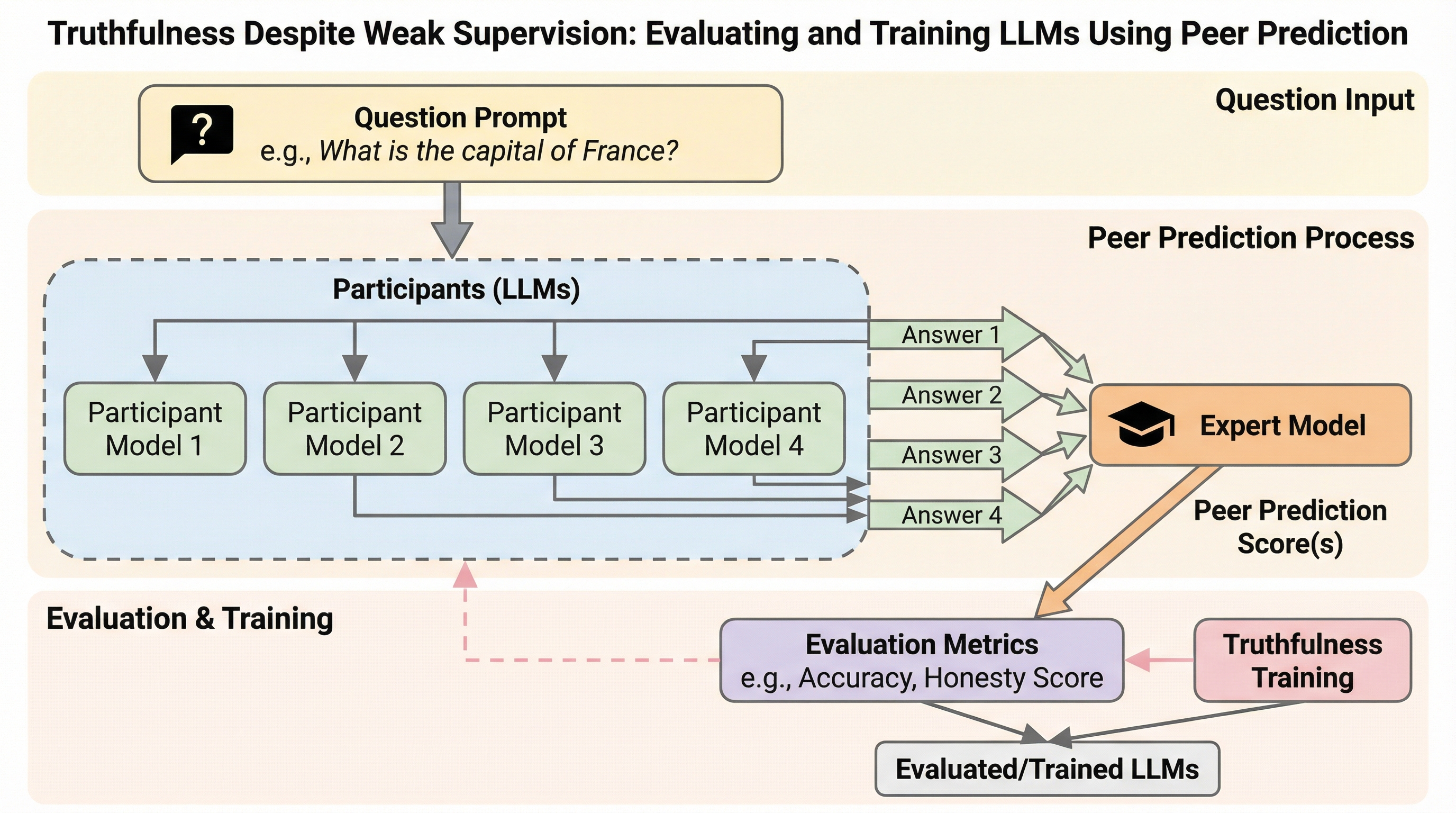
大規模言語モデル(LLM)が監視者の知識不足を悪用して迎合的・欺瞞的な回答を行う問題に対し、正解ラベルを一切使用せず、回答間の「相互予測可能性」に基づいて誠実さを評価するゲーム理論的枠組み「ピア予測」を導入しました。
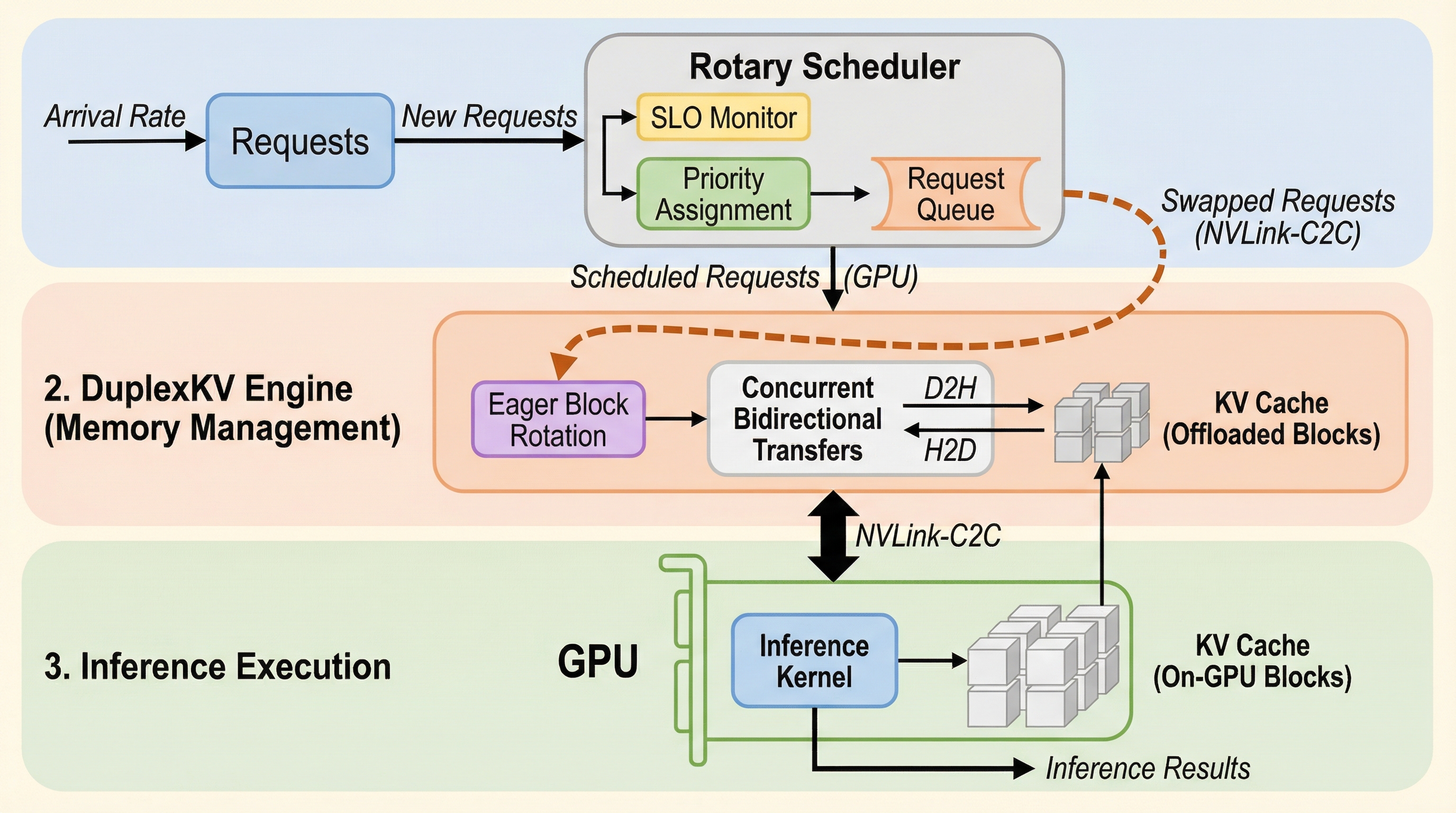
SuperInferは、NVIDIA GH200のようなスーパーチップ環境において、大規模言語モデル(LLM)推論の遅延サービスレベル目標(SLO)を達成するために設計された、新しいスケジューリングおよびメモリ管理システムである。
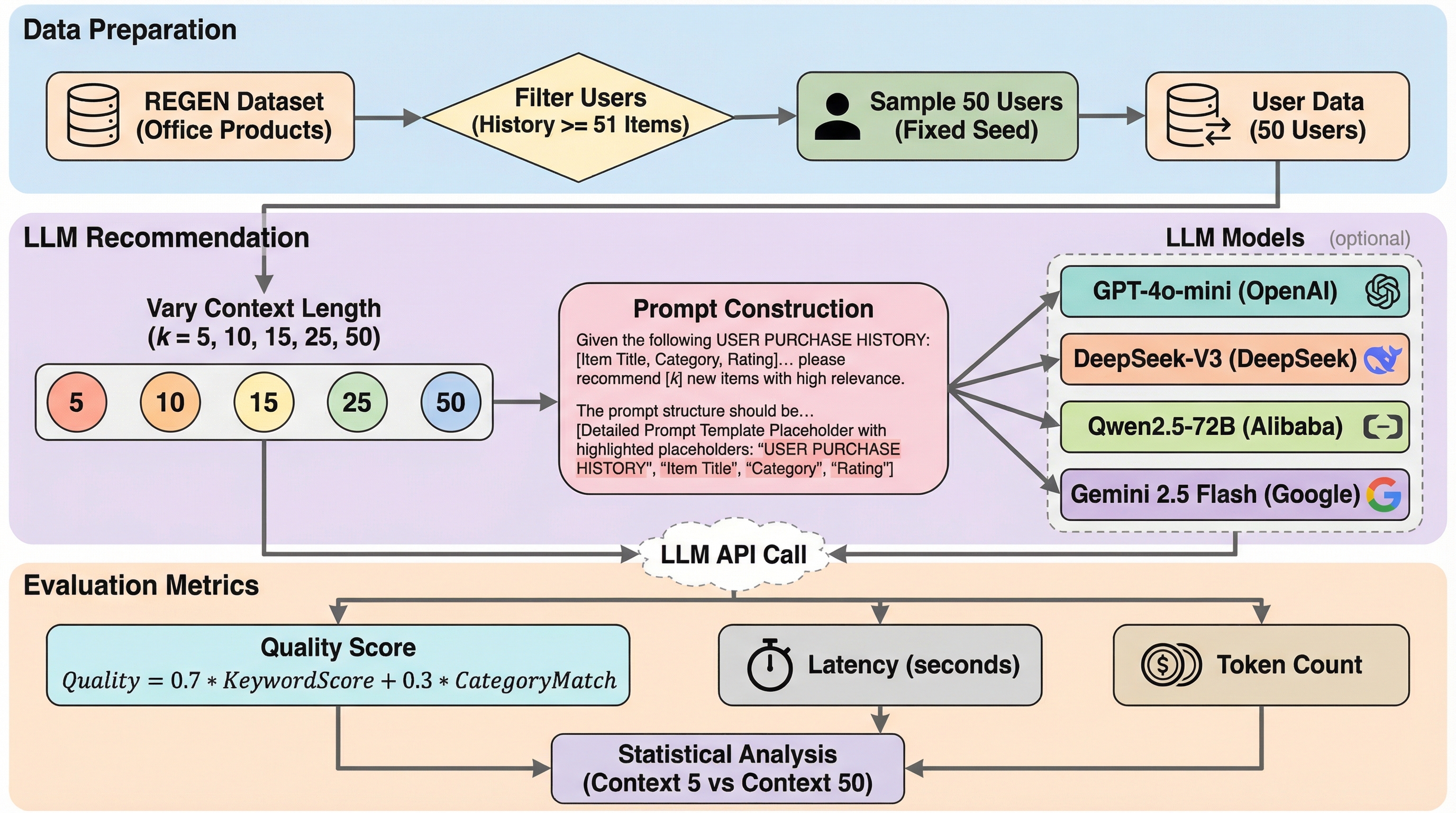
大規模言語モデル(LLM)を用いた推薦システムにおいて、ユーザーの購入履歴を5件から50件に増やしても推薦の質は向上せず、品質スコアは0.17から0.23の範囲で停滞することが判明しました。GPT-4o-mini、DeepSeek-V3、Qwen2.5-72B、Gemini 2.
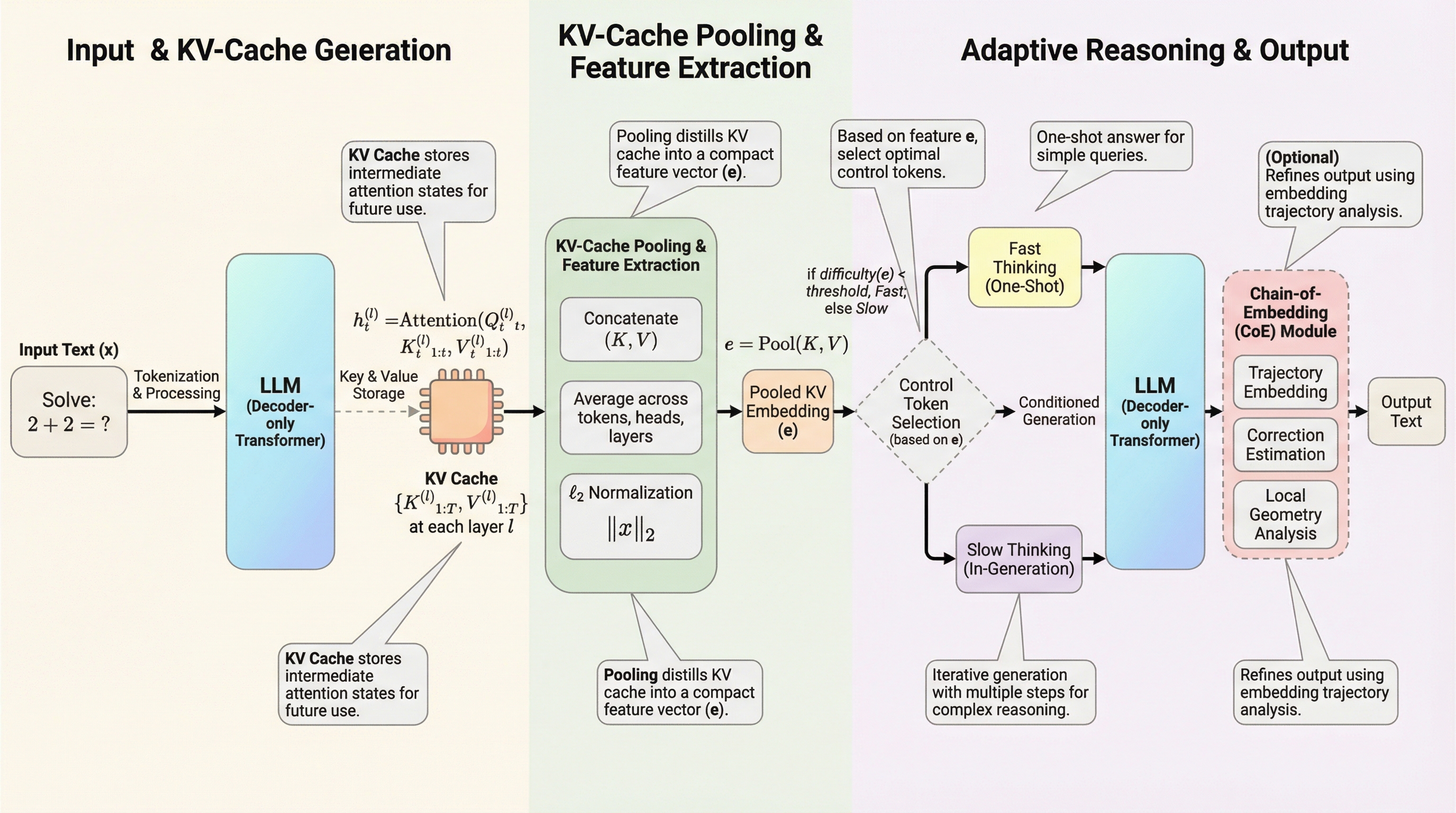
大規模言語モデルの推論を高速化するために不可欠なKVキャッシュを、単なる加速手段ではなく、下流タスクのための軽量な表現(埋め込み)として再利用する手法が提案されました。 この手法は、追加の計算コストやメモリ消費をほとんど伴わずに、推論パスの選択を行うChain-of-Embeddingや、問題の難易度に応じて思考の深さを切り替えるFast/Slow Thinking Switchに適用可能です。 実験では、Llama-3.1やQwen2などのモデルにおいて、フル状態の隠れ層を用いる手法に匹敵する性能を示しつつ、特定のタスクでは生成トークン数を最大5.7倍削減することに成功しました。
従来の異常セグメンテーションは、分布シフトに対して脆弱な固定の閾値設定に依存しており、未知のドメインやノイズに対して精度が著しく低下する課題がありました。本研究では、トポロジー的データ解析(TDA)と最適輸送(OT)を統合した「TopoOT」を提案し、データの幾何学的構造の持続性を利用して、閾値に依存しない安定した擬似ラベルを生成する仕組みを構築しました。検証の結果、2Dおよび3Dの主要ベンチマークにおいて従来手法を最大24.1%上回る性能を達成し、121 FPSという高速な処理速度と低メモリ消費を両立しつつ、多様なバックボーンへの高い適応能力を示しました。