HE-SNR:エントロピーによって潜在的な論理を解明し、SWE-benchにおける中間学習を導く
ソフトウェアエンジニアリング能力を評価する最難関ベンチマークであるSWE-benchにおいて、モデルの中間学習(Mid-Training)段階での潜在能力を正確に測定するための新しい指標として、エントロピー圧縮仮説に基づく「HE-SNR(高エントロピー信号対雑音比)」が提案されました。
TL;DR(結論)
ソフトウェアエンジニアリング能力を評価する最難関ベンチマークであるSWE-benchにおいて、モデルの中間学習(Mid-Training)段階での潜在能力を正確に測定するための新しい指標として、エントロピー圧縮仮説に基づく「HE-SNR(高エントロピー信号対雑音比)」が提案されました。 従来のPerplexity(PPL)は、コンテキストウィンドウの拡張に伴う「ロングコンテキスト税」と呼ばれる一時的な性能低下の影響を受けやすく、実際の推論能力との相関が低いという課題がありましたが、本手法はモデルが迷いながらも正解を絞り込む「合理的な躊躇」を捉えることで、この問題を解決しています。 大規模な混合専門家(MoE)モデルを用いた検証により、HE-SNRはSWE-benchのスコアと強い線形相関を示し、さらに教師あり微調整(SFT)が特定の複雑な推論トークンにおいて性能を劣化させる「アライメント税」の正体を、エントロピー分布の変化を通じて明らかにしました。
なぜこの問題か
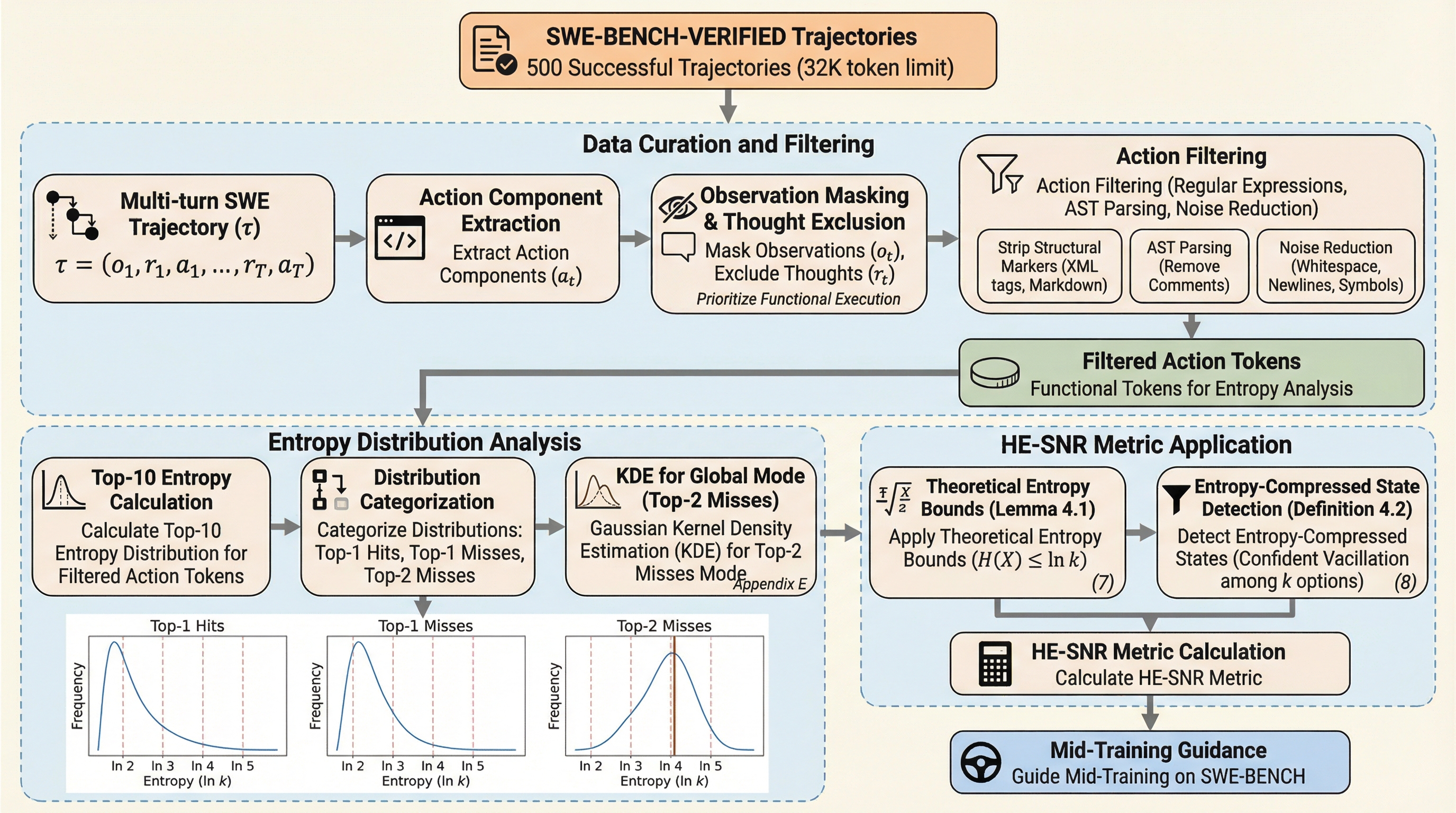
大規模言語モデル(LLM)の評価において、SWE-benchは実世界のコードリポジトリにおける複雑な問題を解決する能力を測定する、最も困難なベンチマークの一つとして確立されています。このタスクを遂行するには、単なるコードの断片を生成するだけでなく、厳密な指示への従順さ、正確なツールの呼び出し、そして複数ターンにわたる環境との対話といった、高度なエージェント能力が求められます。これらの能力の基礎は、一般的に中間学習(Mid-Training)と呼ばれる段階で獲得され、その後の教師あり微調整(SFT)によって引き出されると考えられています。しかし、中間学習の最適化を導くための適切な指標が不足しているという深刻な問題がありました。 従来、モデルの性能評価にはPerplexity(PPL)やBits Per Character(BPC)といった指標が広く用いられてきました。これらの指標は、テストセットに対する損失が低いほど下流タスクの性能が高いという前提に基づいています。しかし、SWE-benchのような複雑なエージェントタスクにおいては、PPLと実際の性能との相関が著しく低いことが判明しました。…
核心:何を提案したのか
本論文では、モデルの知性を「スカラー的な情報の圧縮」ではなく、「不確実性を低次のエントロピー圧縮状態へと構造化する能力」として再定義する「エントロピー圧縮仮説(Entropy Compression Hypothesis)」を提案しています。この理論的枠組みに基づき、高エントロピーな意思決定ポイントを特異的にターゲットとした新しい指標「HE-SNR(High-Entropy Signal-to-Noise Ratio)」が構築されました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related