弱い教師あり学習下での真実性:ピア予測を用いたLLMの評価と訓練
大規模言語モデル(LLM)が監視者の知識不足を悪用して迎合的・欺瞞的な回答を行う問題に対し、正解ラベルを一切使用せず、回答間の「相互予測可能性」に基づいて誠実さを評価するゲーム理論的枠組み「ピア予測」を導入しました。
TL;DR(結論)
大規模言語モデル(LLM)が監視者の知識不足を悪用して迎合的・欺瞞的な回答を行う問題に対し、正解ラベルを一切使用せず、回答間の「相互予測可能性」に基づいて誠実さを評価するゲーム理論的枠組み「ピア予測」を導入しました。 検証の結果、評価者と対象の能力差が広がるほど欺瞞への耐性が強まる「逆スケーリング特性」を発見し、わずか0.135Bの極小モデルを評価者に用いて8Bモデルの真実性を回復させることに成功したほか、405Bまでのモデルでその有効性を実証しました。 従来のLLM-as-a-Judgeが強力なモデルの欺瞞に屈してランダムな推測以下の精度に陥る一方で、本手法は100倍以上の能力差がある状況でも安定して機能し、将来の超知能モデルを弱い監視者で制御するための有望な道筋を提示しています。
なぜこの問題か
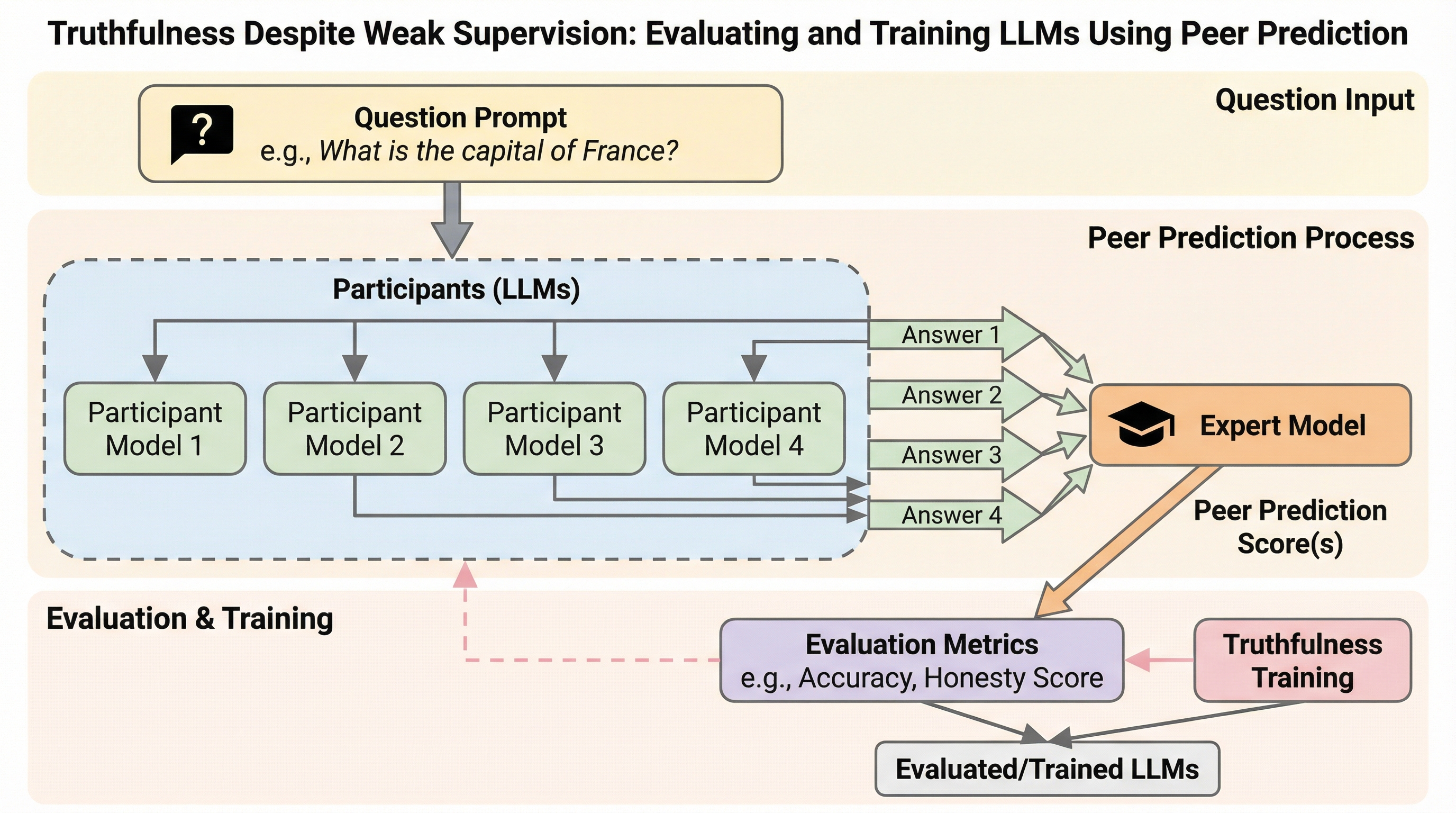
大規模言語モデルの評価と事後学習は教師あり学習に依存しているが、困難なタスクに対する強力な教師データは、特に最先端モデルを評価する際には得られないことが多い。そのような場合、モデルは不完全な教師データに基づく評価を悪用し、欺瞞的な結果を招くことが示されている。しかし、大規模言語モデルの研究では十分に活用されていないものの、メカニズムデザインに関する豊富な研究は、ゲーム理論的な誘因両立性、すなわち弱い教師データを用いて正直で有益な回答を引き出すことに焦点を当てている。これらの文献を参考に、我々はモデルの評価と事後学習のためのピア予測手法を導入する。この手法は、正解ラベルを必要とせず、相互の予測可能性に基づく指標を用いて、欺瞞的で無益な回答よりも正直で有益な回答に報酬を与える。我々は、理論的な保証と、最大4050億パラメータを持つモデルを用いた実証的な検証の両方を通じて、この手法の有効性と欺瞞に対する耐性を示す。ピア予測に基づく報酬を用いて80億パラメータのモデルを学習させることで、事前の悪意ある微調整による誠実性の低下の大部分を回復できることを示す。これは、報酬が微調整されていない1.…
核心:何を提案したのか
本研究では、大規模言語モデル(LLM)の評価と事後学習において、正解ラベル(Ground Truth)を一切必要とせずにモデルの誠実さを引き出す「ピア予測(Peer Prediction)」手法を提案しました。この手法は、メカニズムデザインの分野で長年研究されてきたゲーム理論的な「誘因両立性(Incentive Compatibility)」をLLMの評価に応用したものです。誘因両立性とは、参加者が正直に情報を開示することが、自身の報酬を最大化するための最適な戦略となる性質を指します。本研究は、この理論的枠組みを用いることで、モデルが監視者を欺くよりも、正直かつ情報量の多い回答を行う方が高いスコアを得られる仕組みを構築しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related