スピードアップの先へ:KVキャッシュをサンプリングと推論に活用する
大規模言語モデルの推論を高速化するために不可欠なKVキャッシュを、単なる加速手段ではなく、下流タスクのための軽量な表現(埋め込み)として再利用する手法が提案されました。 この手法は、追加の計算コストやメモリ消費をほとんど伴わずに、推論パスの選択を行うChain-of-Embeddingや、問題の難易度に応じて思考の深さを切り替えるFast/Slow Thinking Switchに適用可能です。 実験では、Llama-3.1やQwen2などのモデルにおいて、フル状態の隠れ層を用いる手法に匹敵する性能を示しつつ、特定のタスクでは生成トークン数を最大5.7倍削減することに成功しました。
TL;DR(結論)
大規模言語モデルの推論を高速化するために不可欠なKVキャッシュを、単なる加速手段ではなく、下流タスクのための軽量な表現(埋め込み)として再利用する手法が提案されました。 この手法は、追加の計算コストやメモリ消費をほとんど伴わずに、推論パスの選択を行うChain-of-Embeddingや、問題の難易度に応じて思考の深さを切り替えるFast/Slow Thinking Switchに適用可能です。 実験では、Llama-3.1やQwen2などのモデルにおいて、フル状態の隠れ層を用いる手法に匹敵する性能を示しつつ、特定のタスクでは生成トークン数を最大5.7倍削減することに成功しました。
なぜこの問題か
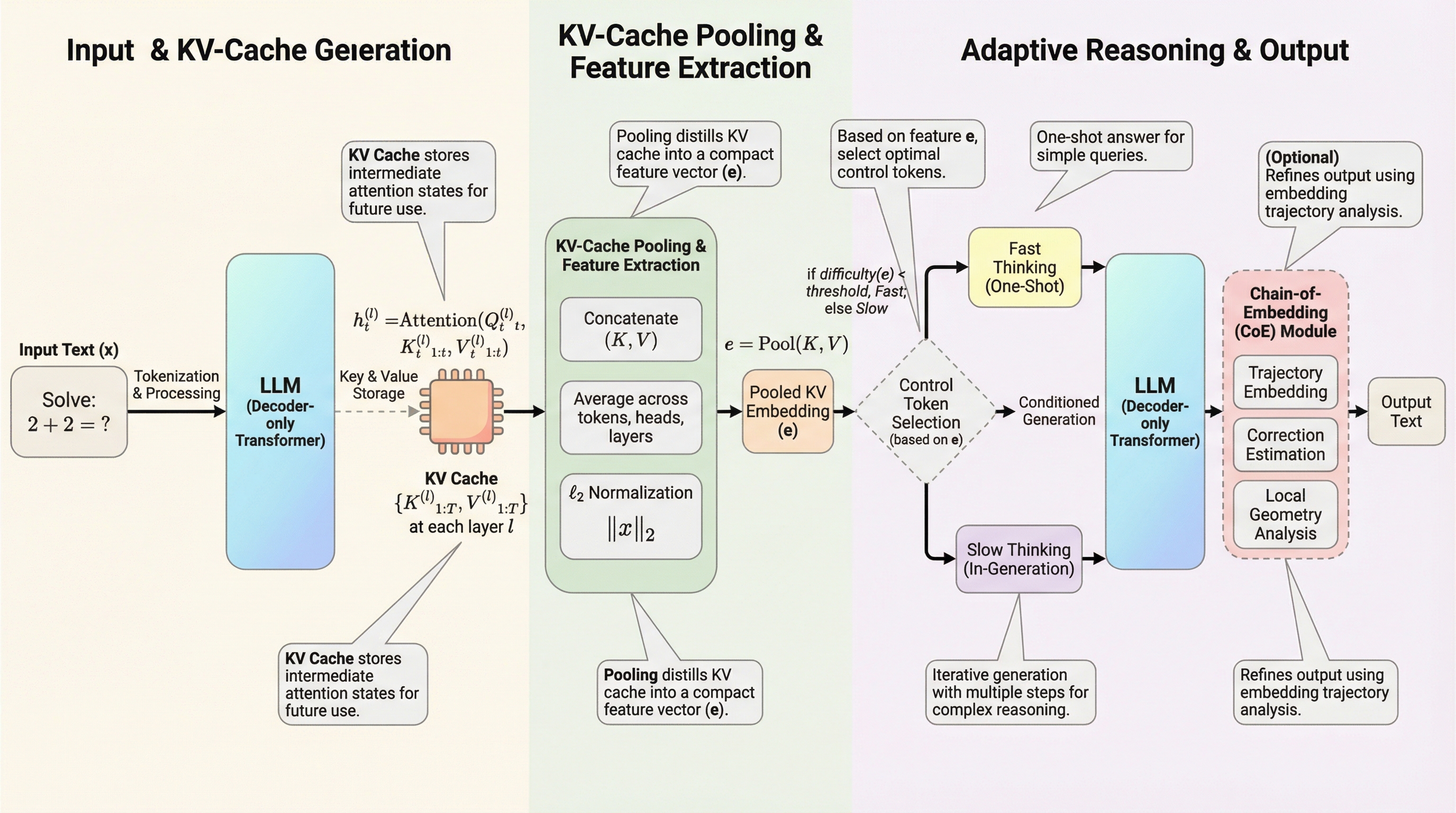
現代の大規模言語モデル(LLM)において、自己回帰的なデコーディングを高速化するためにKVキャッシュは欠かせない存在となっています。標準的なアテンション機構では、新しいトークンを生成するたびに過去の全てのトークンに対して計算をやり直す必要があり、計算複雑度がシーケンス長の二乗に比例して増大するというボトルネックが存在します。KVキャッシュはこの問題を解決するために、過去のアテンション状態(キーと値)を保存し、再計算を避けることで計算複雑度を線形に抑える役割を果たしています。しかし、これまでの研究や実用的なシステムにおいて、KVキャッシュの役割はもっぱらこの「推論の加速」に限定されてきました。 一方で、モデルの内部状態である隠れ層(Hidden States)を活用して、モデル自身の回答の正確性を評価したり、推論のプロセスを適応的に制御したりする試みも行われています。しかし、これらの手法には大きな代償があります。フル状態の隠れ層を保存または再計算することは、メモリ消費と計算コストの両面で非常に高価であり、特に長いコンテキストを扱う場合にはGPUメモリ(VRAM)の使用量が劇的に増加してしまいます。…
核心:何を提案したのか
本研究の核心は、KVキャッシュを「軽量な表現(Embedding)」として扱い、それをサンプリングや推論の制御に活用する新しい枠組みを提案した点にあります。具体的には、KVキャッシュを単なる加速用のデータとしてではなく、タスク固有の情報を保持したベクトルとして再定義しました。この提案には大きく分けて二つの主要なアプリケーションが含まれています。一つ目は「Chain-of-Embedding(CoE)」のKVキャッシュ版である「KV-CoE」です。これは、推論中のトークンごとのKVキャッシュの軌跡を追跡することで、生成された回答の正誤を自己評価する手法です。従来のCoEは隠れ層の保存を必要としていましたが、KV-CoEは既存のキャッシュを再利用するため、メモリのオーバーヘッドがほぼゼロになります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related