Less is More: 大規模言語モデルによる推薦エージェントのベンチマーク
大規模言語モデル(LLM)を用いた推薦システムにおいて、ユーザーの購入履歴を5件から50件に増やしても推薦の質は向上せず、品質スコアは0.17から0.23の範囲で停滞することが判明しました。GPT-4o-mini、DeepSeek-V3、Qwen2.5-72B、Gemini 2.
TL;DR(結論)
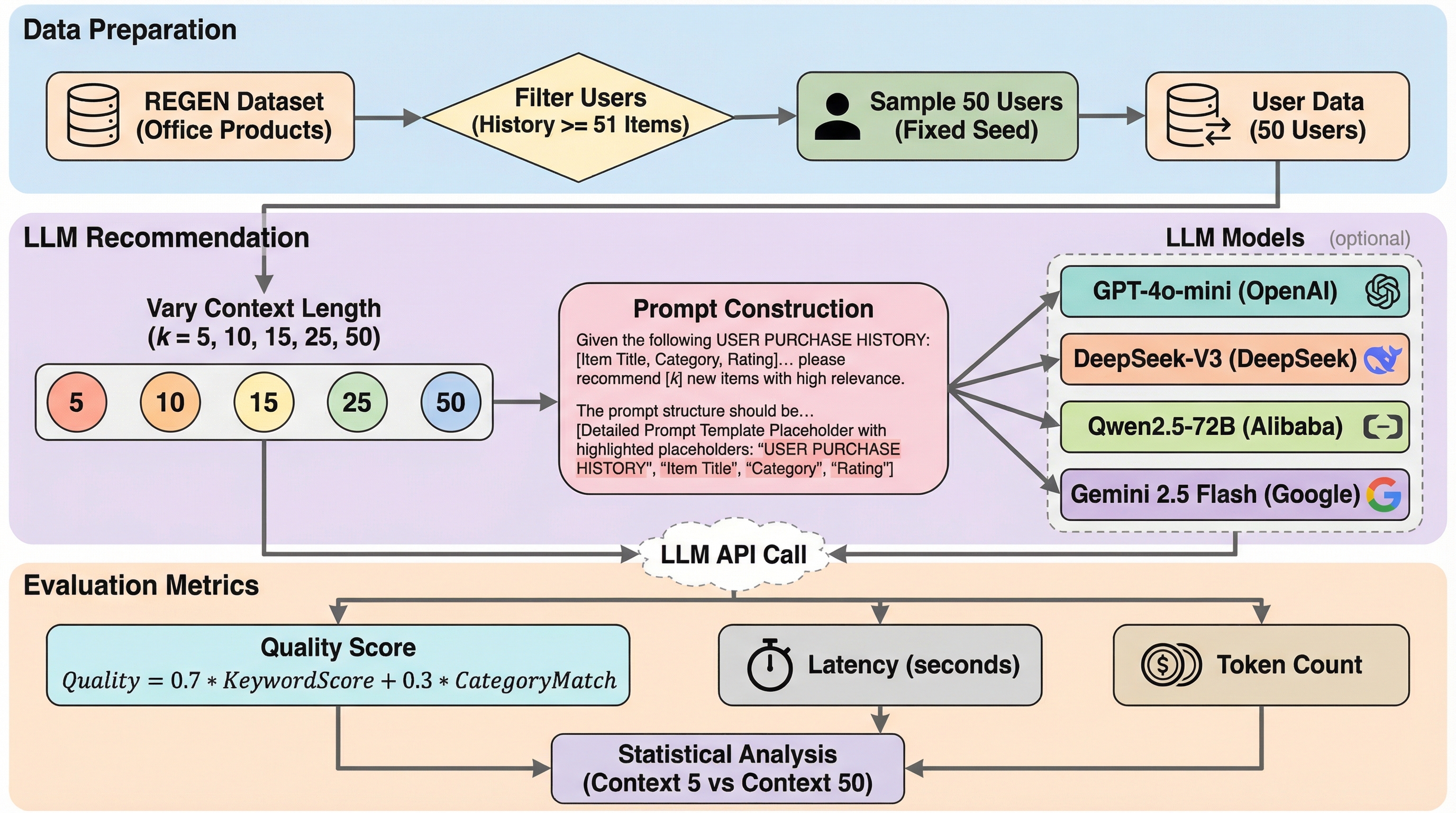
大規模言語モデル(LLM)を用いた推薦システムにおいて、ユーザーの購入履歴を5件から50件に増やしても推薦の質は向上せず、品質スコアは0.17から0.23の範囲で停滞することが判明しました。GPT-4o-mini、DeepSeek-V3、Qwen2.5-72B、Gemini 2.5 Flashの全モデルで共通して、履歴を増やしても統計的に有意な精度の改善は見られず、むしろコストと遅延が増大する傾向があります。履歴を5〜10件に制限することで、推薦の質を維持したまま推論コストを約88%削減し、リアルタイム性を高めることが可能であり、従来の「コンテキストは長いほど良い」という常識を覆す結果となりました。
なぜこの問題か
現在、パーソナライズされた製品推薦のために大規模言語モデル(LLM)が広く導入されています。実務者の間では、ユーザーの過去の購入履歴をより長く提供するほど、モデルはユーザーの好みを深く理解し、より正確な予測ができるようになるという共通の仮定が存在していました。この信念に基づき、数十から数百の過去のインタラクションを含む長いコンテキストウィンドウが利用されることが一般的です。しかし、この「履歴が長いほど良い」という仮定は、推薦のシナリオにおいて体系的に検証されてきたわけではありません。LLMは文書の要約や質問回答などのタスクにおいて長いコンテキストを活用する能力を示していますが、製品推薦という特定のタスクにおいて、拡張されたユーザー履歴をどれほど効果的に活用できるかは不明確でした。 長いコンテキストの使用には、API費用の増大、推論遅延の悪化、計算リソースの要求増加といった重大なコストが伴います。推薦システムが、計画や推論、多対話を行うエージェント的なエコシステムへと進化する中で、コンテキストを効率的に管理することは、スケーラブルで応答性の高いパーソナライゼーションを実現するための基盤となります。…
核心:何を提案したのか
本研究では、4つの最先端LLM(GPT-4o-mini、DeepSeek-V3、Qwen2.5-72B、Gemini 2.5 Flash)を対象に、コンテキストの長さが推薦の質に与える影響を体系的に調査するベンチマークを提案しました。具体的には、ユーザーの購入履歴の長さを5、10、15、25、50アイテムの5段階で変化させ、それぞれの条件下でモデルが次に購入される製品をどれだけ正確に予測できるかを測定しました。評価対象となったモデルは、OpenAI、Google、Alibaba、DeepSeekといった異なるプロバイダーから選定されており、特定のアーキテクチャに依存しない普遍的な傾向を捉えることを目的としています。 実験には、Amazonの製品レビューを生成的なナラティブで強化したREGENデータセットを使用しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related