XIMP:分子物性予測のためのクロスグラフ間メッセージパッシング
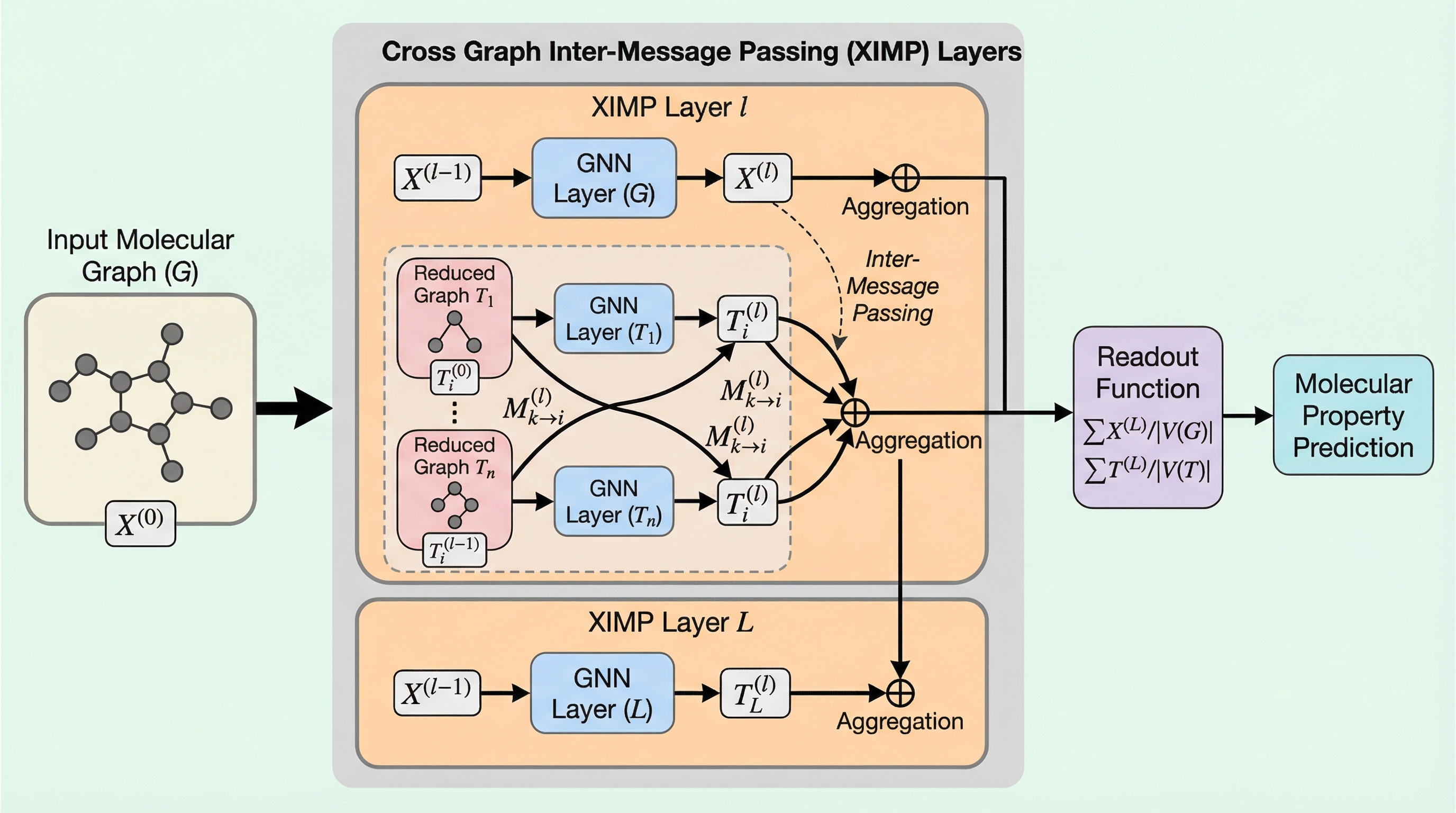
創薬の初期段階で不可欠な分子物性予測において、従来のグラフニューラルネットワークはデータが少ない環境で精度が上がらず、古典的なフィンガープリント手法に劣るという課題がありました。 本研究で提案された「XIMP」は、原子レベルの分子グラフに加えて、構造を階層的に捉えるジャンクションツリーや薬理学的な特徴を保持する拡張縮約グラフといった複数の抽象化表現を統合し、それらの間で情報を双方向に伝達する新しい枠組みです。 10種類の多様なタスクを用いた検証の結果、XIMPは既存の最先端モデルや伝統的な手法を多くのケースで上回り、特にデータが限られた状況下で化学的な知識を効果的に活用することで高い汎化性能と理論的な表現力の向上を実現しました。